缓存过期
缓存过期
Redis 系列目录:https://www.cnblogs.com/binarylei/p/11721921.html
缓存过期
Redis 缓存过期有 2 种策略,被动过期和主动过期。
- 被动过期删除:客户端访问 Redis 时,发现 key 已经过期,需要删除数据
- 主动过期删除:Redis 主线程有一个定时任务,默认没 100ms 执行一次,每次主动淘汰一批已经过期的数据。
接下来,我会依次分析被动过期和主动过期在 Redis 中是如何实现的。
数据结构
我们先看一下 KEY 的过期时间在 Reids 中是如何存储的。首先,为了方便查找,Redis 会将所有设置了过期时间的 KEY 单独存放。其次,KEY 的过期时间保存在 hash 节点中。
src/server.h/redisDb 保存所有的数据 dict,及设置过期时间的 KEY 集合 expires。
dict *dict; /* 数据key->value */
dict *expires; /* 设置了过期时间的key */
src/dict.h/dictEntry 保存 KEY 的过期时间 s64
int64_t s64; /* 过期时间 */
同时,src/db.c 定义了一系列的方法操作 KEY 的过期时间:
setExpire:设置 KEY 的过期时间。getExpire:获取 KEY 的过期时间。keyIsExpired:判断 KEY 是否过期。
有了这些基础,我们再来看过期删除是如何实现的。
被动删除
被动删除,客户端访问时才会淘汰过期数据,相比主动淘汰,更加节省 CPU。Redis 增删改查等数据操作,都会先调用 expireIfNeeded 方法判断数据是否过期,如果过期了,就会先把过期的数据淘汰,再执行客户端命令。下面是被动过期的执行流程。
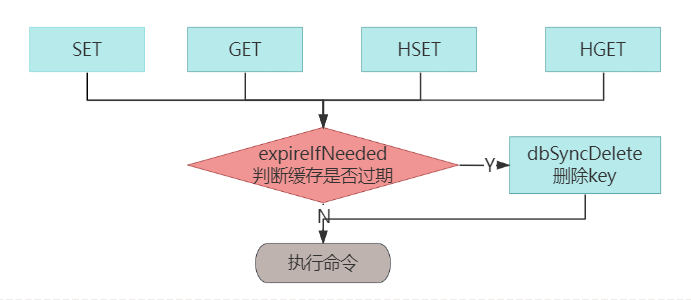
可以看到,Reids 的 GET、SET、HSET、KEYS 等操作,都会先调用 expireIfNeeded 方法。我们看一下这个方法。src/db.c
int expireIfNeeded(redisDb *db, robj *key) {
/* 判断key是否过期 */
if (!keyIsExpired(db,key)) return 0;
/* slave节点的数据是从master同步过来的,不主动淘汰key */
if (server.masterhost != NULL) return 1;
/* 删除过期的key */
if (server.lazyfree_lazy_expire) {
dbAsyncDelete(db,key);
} else {
dbSyncDelete(db,key);
}
return 1;
}
expireIfNeeded 方法也很简单,先判断 KEY 是否过期,如果过期了就删除该数据。需要注意的是,slave 节点是不能主动删除数据的,它的数据必须都从 master 同步过来,等 master 淘汰了该过期数据就会同步到从节点,此时 slave 就会删除该数据。否则,就有可能出现主从数据不一致的现象。
主动删除
和被动过期删除需要等客户端访问不同;主动删除策略,在 Reids 比较闲的时候,会主动扫描一定数据的 KEY,淘汰过期的数据。下图是主动删除的执行流程:
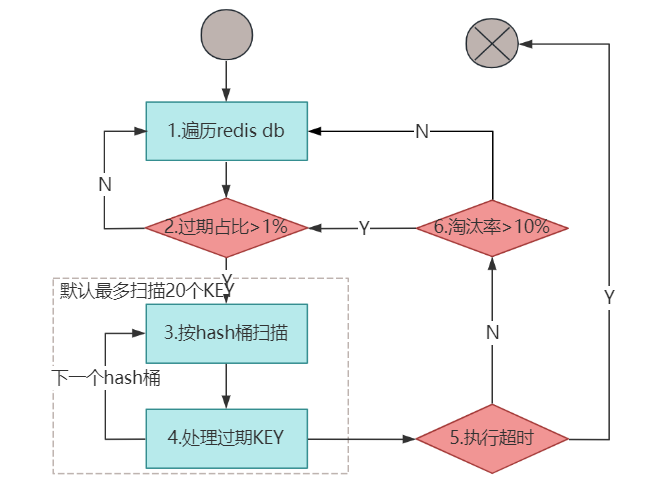
前面我们说了,Redis 将所有设置了过期时间的 KEY,都单独存放在 expires 字典表中。所以,主动删除其实就是遍历这个 expires 字典表,发现数据过期了就删除。当然,Reids 为了考虑性能,每次执行时都有扫描个数和时间的限制,超过了就主动退出,下一次再继续。我们看一下可以的代码 src/expire.c/activeExpireCycle 方法。
void activeExpireCycle(int type) {
static unsigned int current_db = 0;
int j, iteration = 0;
int dbs_per_call = CRON_DBS_PER_CALL;
long long start = ustime(), timelimit, elapsed; // ustime 时间单位为微秒
/* 计算最大执行时间,默认25ms。 */
timelimit = config_cycle_slow_time_perc*1000000/server.hz/100;
/* 1.遍历redis db,current_db指向下一个要扫描的数据库 */
for (j = 0; j < dbs_per_call && timelimit_exit == 0; j++) {
unsigned long expired, sampled;
redisDb *db = server.db+(current_db % server.dbnum);
current_db++;
/* 开始扫描该数据库下的key */
do {
unsigned long num, slots;
long long now, ttl_sum;
int ttl_samples;
iteration++;
/* 2.1没有设置过期时间的KEY,直接返回 */
if ((num = dictSize(db->expires)) == 0) {
break;
}
slots = dictSlots(db->expires);
now = mstime();
/* 2.2计算设置过期KEY的占比,如果小于10%,设置过期的KEY不多扫描一次不划算,等待扩容 */
if (slots > DICT_HT_INITIAL_SIZE &&
(num*100/slots < 1)) break;
expired = 0; // 过期KEY个数
sampled = 0; // 扫描KEY个数
if (num > config_keys_per_loop)
num = config_keys_per_loop; // 最大扫描的KEY个数
/* 3.这里开始真是扫描key进行过期淘汰,每次默认最多扫描20个key,400个桶。
* 3.1根据expires_cursor找到当前要扫描的hash桶位置
* 3.2依次扫描该hash桶的所有key,判断是否过期
* 3.3统计扫描到的key个数sampled和过期的个数expired
* 3.4扫描下一个桶expires_cursor++,直至扫描的key个数超过默认的20个
*/
long max_buckets = num*20;
long checked_buckets = 0;
while (sampled < num && checked_buckets < max_buckets) {
for (int table = 0; table < 2; table++) {
if (table == 1 && !dictIsRehashing(db->expires)) break;
unsigned long idx = db->expires_cursor;
idx &= db->expires->ht[table].sizemask;
dictEntry *de = db->expires->ht[table].table[idx];
long long ttl;
checked_buckets++;
while(de) {
dictEntry *e = de;
de = de->next;
ttl = dictGetSignedIntegerVal(e)-now;
/* 4.activeExpireCycleTryExpire进行缓存淘汰 */
if (activeExpireCycleTryExpire(db,e,now)) expired++;
sampled++;
}
}
db->expires_cursor++;
}
/* 5.计算执行时间,判断是否超时。每迭代16次统计一次执行时间 */
if ((iteration & 0xf) == 0) {
elapsed = ustime()-start;
if (elapsed > timelimit) {
timelimit_exit = 1;
break;
}
}
/* 6.如果缓存淘汰率大于10%继续,说明过期数据很多,可以牺牲一下可用性,多淘汰一点过期数据 */
} while (sampled == 0 || (expired*100/sampled) > config_cycle_acceptable_stale);
}
}
这些步骤里面,我希望你重点关注一下 Redis 是如何在性能和可用性上做抉择的。如果想将过期数据都淘汰,必然这段时间服务是不可用的,牺牲了可用性。所以,Redis 设置了每次扫描的 KEY 个数和扫描时长,超出了就主动退出。同时,如果设置过期时间的 KEY 不多(小于 1%),那淘汰的数据也不会多,扫描一次必然性价比不高,此时直接等待字典表扩容即可。相反,如果发现过期的数据较多(淘汰率大于10%),则继续扫描直至超时。
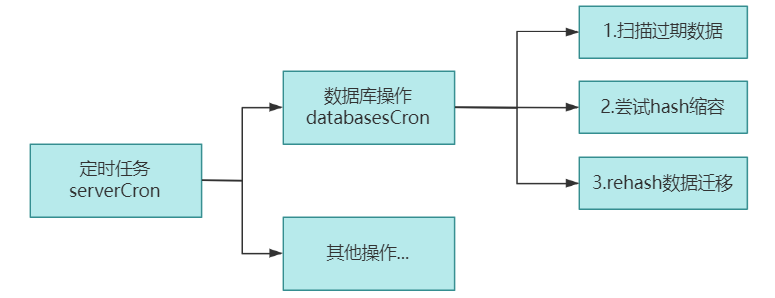
接下来,我们看一下主动删除是什么时候执行的。Redis 有一个主线程的定时任务,默认 1s 执行 10 次。每次执行时都会扫描过期数据、hash resize缩容、rehash数据迁移等。感兴趣的可以看一下代码,src/server.c 下的 serverCron 和 databasesCron 方法。
总结
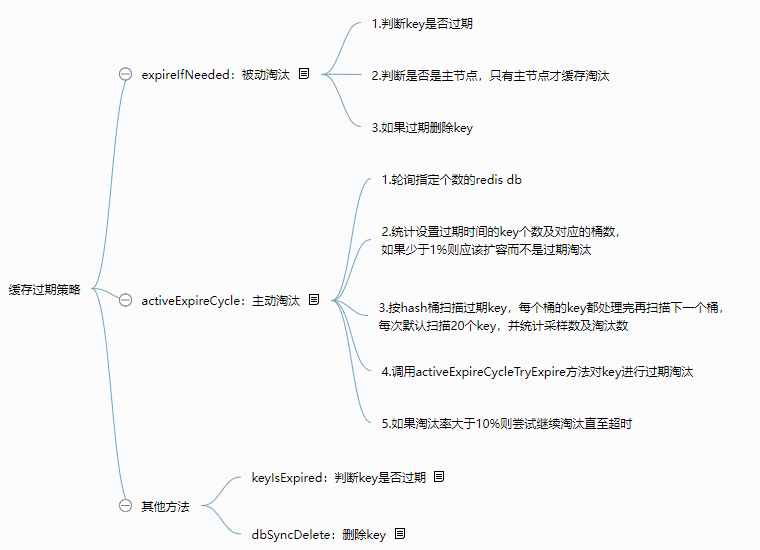
今天,我重点分析了 Reids 缓存过期删除的两种策略,我们复习一下。
1.被动过期删除:数据增删改查时都会调用 expireIfNeeded 方法,判断缓存是否过期。
2.主动过期删除:默认每 100ms 扫描一次设置了过期时间的数据,activeExpireCycle 方法为了避免阻塞应用,每次只会扫描部分数据。
讲到这里,Reids 缓存过期删除的源码我就介绍完了。我建议你特别关注下 Redis 在性能和可用性的平衡,架构设计往往鱼和熊掌不可兼得。最后,我用一张思维导图来帮助你理解和记忆这两种过期删除策略:
文章推荐:
每天用心记录一点点。内容也许不重要,但习惯很重要!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号