指令和运算 - 指令执行之函数调用:函数调用和递归调用是怎么实现的
指令和运算 - 指令执行之函数调用:函数调用和递归调用是怎么实现的
计算机组成原理目录:https://www.cnblogs.com/binarylei/p/12585607.html
1. 为什么我们需要程序栈
1.1 示例
// function_example.c
#include <stdio.h>
int static add(int a, int b)
{
return a+b;
}
int main()
{
int x = 5;
int y = 10;
int u = add(x, y);
}
同样编译一下 function_example.c 文件后,使用 objdump 查看汇编指令:
gcc -g -c function_example.c
objdump -d -M intel -S function_example.o
我们把这个程序编译之后,objdump 出来。我们来看一看对应的汇编代码。
int static add(int a, int b)
{
0: 55 push rbp
1: 48 89 e5 mov rbp,rsp
4: 89 7d fc mov DWORD PTR [rbp-0x4],edi
7: 89 75 f8 mov DWORD PTR [rbp-0x8],esi
return a+b;
a: 8b 55 fc mov edx,DWORD PTR [rbp-0x4]
d: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8]
10: 01 d0 add eax,edx
}
12: 5d pop rbp
13: c3 ret
0000000000000014 <main>:
int main()
{
14: 55 push rbp
15: 48 89 e5 mov rbp,rsp
18: 48 83 ec 10 sub rsp,0x10
int x = 5;
1c: c7 45 fc 05 00 00 00 mov DWORD PTR [rbp-0x4],0x5
int y = 10;
23: c7 45 f8 0a 00 00 00 mov DWORD PTR [rbp-0x8],0xa
int u = add(x, y);
2a: 8b 55 f8 mov edx,DWORD PTR [rbp-0x8]
2d: 8b 45 fc mov eax,DWORD PTR [rbp-0x4]
30: 89 d6 mov esi,edx
32: 89 c7 mov edi,eax
34: e8 c7 ff ff ff call 0 <add>
39: 89 45 f4 mov DWORD PTR [rbp-0xc],eax
3c: b8 00 00 00 00 mov eax,0x0
}
41: c9 leave
42: c3 ret
说明: 可以看出来,在这段代码中
- main 函数:和上一节我们讲的的程序执行区别并不大,它主要是把 jump 指令换成了函数调用的 call 指令(第 34 行)。call 指令后面跟着的,仍然是跳转后的程序地址。
- add 函数:可以看到 add 函数编译之后,代码先执行了一条 push 指令和一条 mov 指令;在函数执行结束的时候,又执行了一条 pop 和一条 ret 指令。这四条指令的执行,其实就是在进行我们接下来要讲压栈(Push)和出栈(Pop)操作。
1.2 函数调用和指令跳转对比
函数调用和上一节我们讲的指令跳转(if…else 分支语句和 for/while 循环语句)有点像。
- 相同点:都是在原来顺序执行的指令过程里,执行了一个内存地址的跳转指令,让指令从原来顺序执行的过程里跳开,从新的跳转后的位置开始执行。
- 不同点:指令跳转后就不再回来了,就在跳转后的新地址开始顺序地执行指令。而函数调用执行完后需要跳回去继续执行。
1.3 几种解决方案对比
如何解决函数调用完成后,又重新返回继续执行的问题?你又有什么好的解决方案呢?
- 将被调用函数的指令直接插入在调用处。也就是将 main 函数中的 call 指令直接替换为 add 函数的指令。但问题是函数调用可能有非常多的层级,同时也导致代码不能利用,浪费内存空间。
- 和指令跳转一样,使用寄存器将跳转的地址缓存下来。但同样当函数调用可能有非常多的层级后,寄存器根据不够用。如 Intel i7 CPU 只有 16 个 64 位寄存器。
2. 程序栈
最终,计算机科学家们想到了一个比单独记录跳转回来的地址更完善的办法,那就是栈。
- 程序栈(Stack):我们在内存里面开辟一段空间,使用后进先出(LIFO,Last In First Out)的数据结构。
- 压栈(Push)与出栈(Pop):每次程序调用函数之前进行压栈,如果函数执行完之后就出栈。
- 栈帧(Stack Frame):在真实的程序里,压栈的不只有函数调用完成后的返回地址。比如函数 A 在调用 B 的时候,需要传输一些参数数据,这些参数数据在寄存器不够用的时候也会被压入栈中。整个函数 A 所占用的所有内存空间,就是函数 A 的栈帧。
思考:为什么栈地址是从高到低的?即为什么栈低的地址大于栈顶的?有什么好处
其实这是一个内存优化分配问题。系统分配一个任务所用的内存是一定的,这个内存是包括椎和栈的。分配内存时,堆从低到高,栈从高到低,这样可以最大化共享内存,不用事先给栈指定一个最大深度。比如,在加载代码的时候都是从低地址往高地址存放代码。
2.1 函数调用过程
了解了栈的知识,我们再看一下上面的案例:
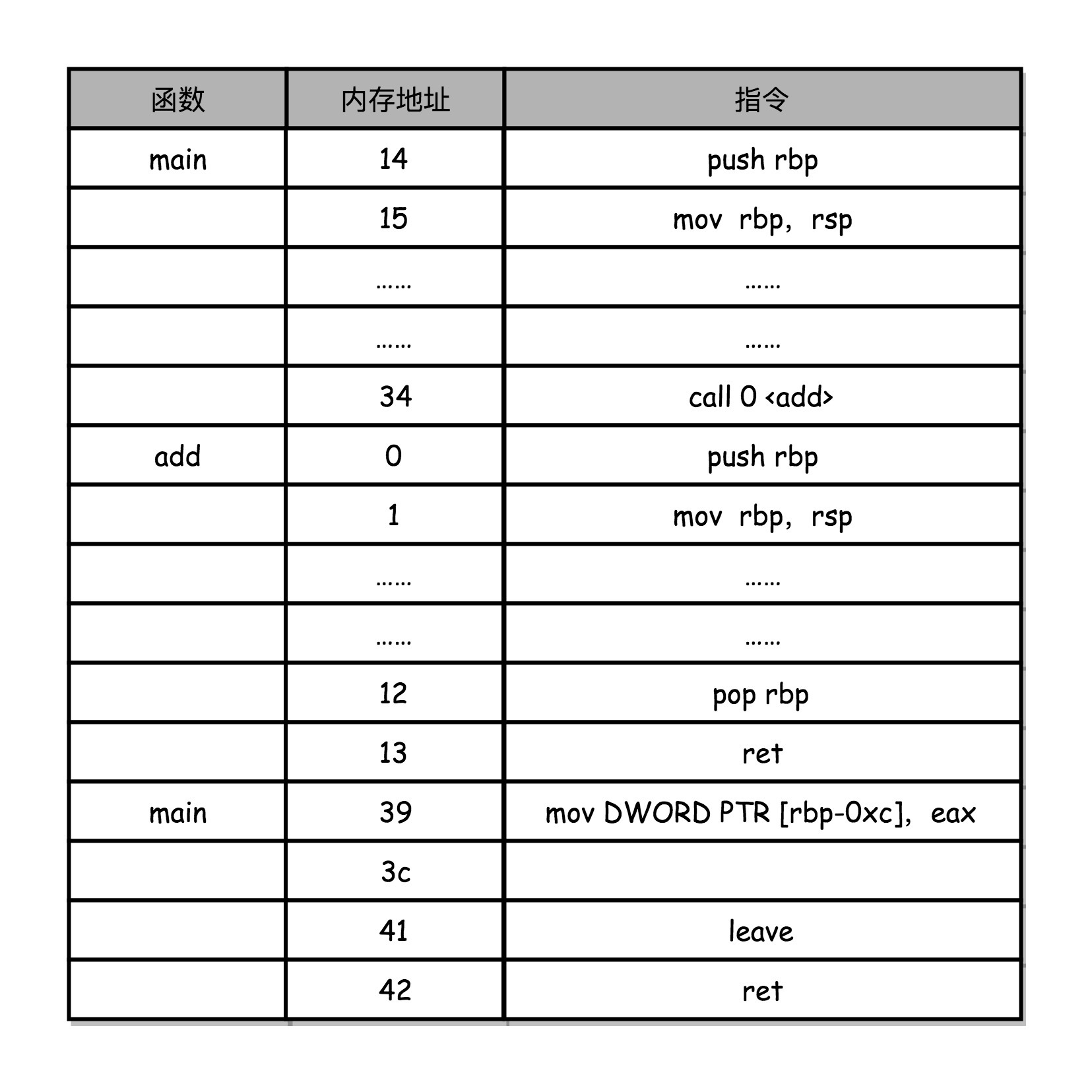
我们在调用第 34 行的 call 指令时,会把当前的 PC 寄存器里的下一条指令的地址压栈,保留函数调用结束后要执行的指令地址。而 add 函数的第 0 行,push rbp 这个指令,就是在进行压栈。
- 第 0 行的 push rbp 指令:把之前调用函数(也就是 main 函数)的栈帧的栈底地址,压到栈顶。其中,rbp 又叫栈帧指针(Frame Pointer),是一个存放了当前栈帧位置的寄存器。
- 第 1 行的 mov rbp, rsp 指令:把 rsp 这个栈指针(Stack Pointer)的值复制到 rbp 里,即 rbp 指向该栈帧的栈底,而 rsp 始终会指向栈顶。这个命令意味着,rbp 这个栈帧指针指向的地址,变成当前最新的栈顶,也就是 add 函数的栈帧的栈底地址。
而在函数 add 执行完成之后,又会调用第 12 行的 pop rbp 来将当前的栈顶出栈。
- 第 12 行的 pop rbp 指令:来将当前的栈顶出栈,这部分操作维护好了我们整个栈帧。
- 第 13 行的 ret 指令:同时要把 call 调用的时候压入的 PC 寄存器里的下一条指令出栈,更新到 PC 寄存器中,将程序的控制权返回到出栈后的栈顶。
2.2 栈溢出
待补充...
2.3 内联优化
上面我们提到一个方法,把一个实际调用的函数产生的指令,直接插入到的位置,来替换对应的函数调用指令。尽管这个通用的函数调用方案,被我们否决了,但是如果被调用的函数里,没有调用其他函数,这个方法还是可行的。
事实上,这就是一个常见的编译器进行自动优化的场景,我们通常叫函数内联(Inline)。我们只要在 GCC 编译的时候,加上对应的一个让编译器自动优化的参数 -O,编译器就会在可行的情况下,进行这样的指令替换。当然内联也是有代价的,内联意味着指令不能复用了。
推荐阅读:
- 《深入理解计算机系统(第三版)》的 3.7 小节《过程》:进一步了解函数调用是怎么回事。
每天用心记录一点点。内容也许不重要,但习惯很重要!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号