
存储器 - 内存:程序的虚拟内存是如何映射到物理内存
存储器 - 内存:程序的虚拟内存是如何映射到物理内存
计算机组成原理目录:https://www.cnblogs.com/binarylei/p/12585607.html
程序运行时,指令和数据都需要先加载到内存里面,才会被 CPU 拿去执行。那程序中的虚拟地址最终是如何映射到内存中的物理地址呢?从简单页表,到多级页表,再到 TLB,都解决了那些问题?
- 简单页表:类似数组,时间复杂度为 O(1)。但空间复杂度为数组的长度,即页的个数。32 位的内存地址为 4MB(= 2^20 * 4byte)。
- 多级页表:类似 B+ 树,时间复杂度为 O(n),如 4 级页表就需要查询 4 次。但程序只需要存储正在使用的虚拟页的映射关系,空间复杂度大大降低。
- TLB:使用缓存保存之前虚拟页的映射关系。因为指令和数据往往都是连续的,存在空间局部性和时间局部性。也就是说,连续执行的多个指令和数据往往在同一个虚拟页中,没必要每次都从内存中读取页表来解析虚拟地址。
1. 虚拟地址和物理地址
另外,学习本节时可以将下面两个知识点对比学习。
- 内存地址映射:虚拟地址是如何映射到物理地址?
- 高速缓存映射:内存地址是如何映射到 CPU Cache?
程序在编译时不可能知道装载后的物理内存地址,实际上,程序编译生成的地址都是虚拟地址。在我们日常使用的 Linux 或者 Windows 操作系统下,程序并不能直接访问物理内存。为了解决这个问题,当程序装载后,会通过虚拟地址映射到真实的物理地址。
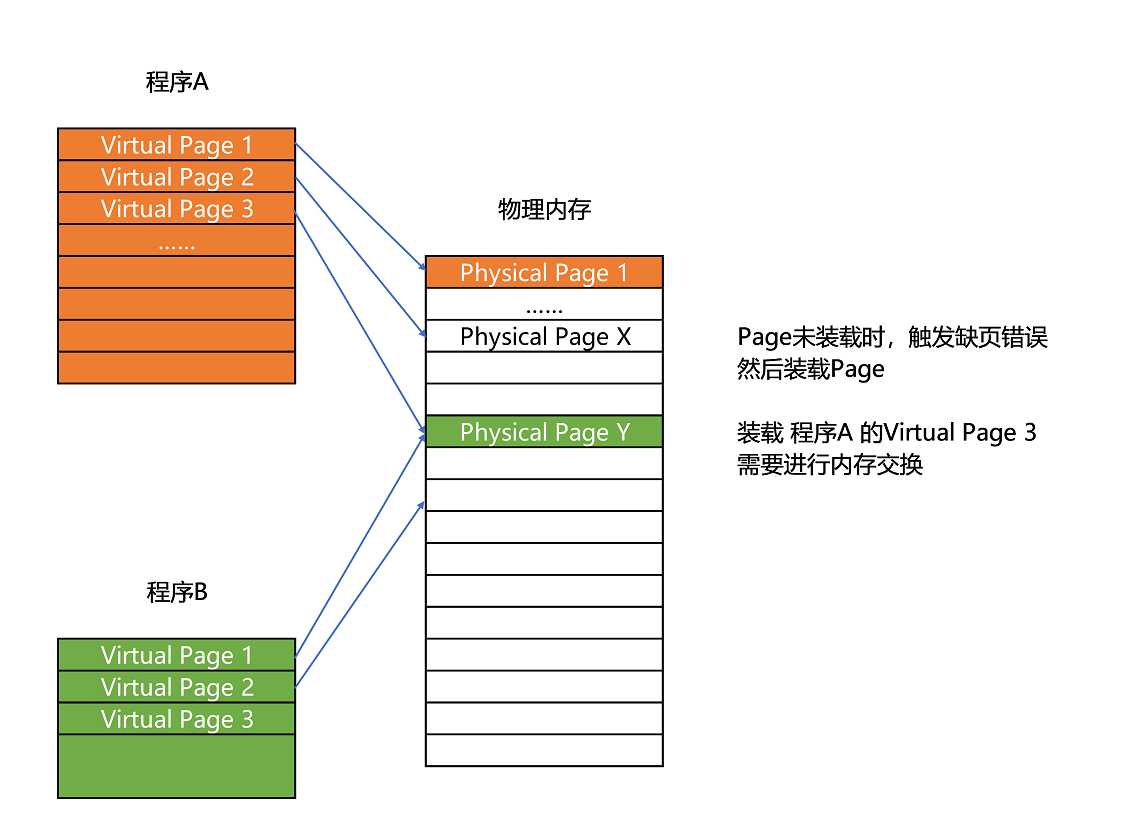
内存被分成固定大小的页(Page),然后再通过虚拟内存地址(Virtual Address) 到物理内存地址(Physical Address) 的地址转换(Address Translation),才能访问实际存放数据的物理内存位置。而我们的程序看到的内存地址,都是虚拟内存地址。
这些虚拟内存地址究竟是怎么转换成物理内存地址的呢?这一讲里,我们就来看一看。
2. 简单页表
页表(Page Table):想要把虚拟内存地址,映射到物理内存地址,最直观的办法,就是来建一张映射表。这个映射表,能够实现虚拟内存里面的页,到物理内存里面的页的映射。这个映射表,在计算机里面,就叫作页表。
页表地址转换,把一个内存地址分成页号(Directory) 和偏移量(Offset) 两个部分。以一个 32 位的内存地址,页的大小 4KB 为例,内存地址的 20 位的高位表示页号,12 位(212 = 4KB)的低位表示偏移量。

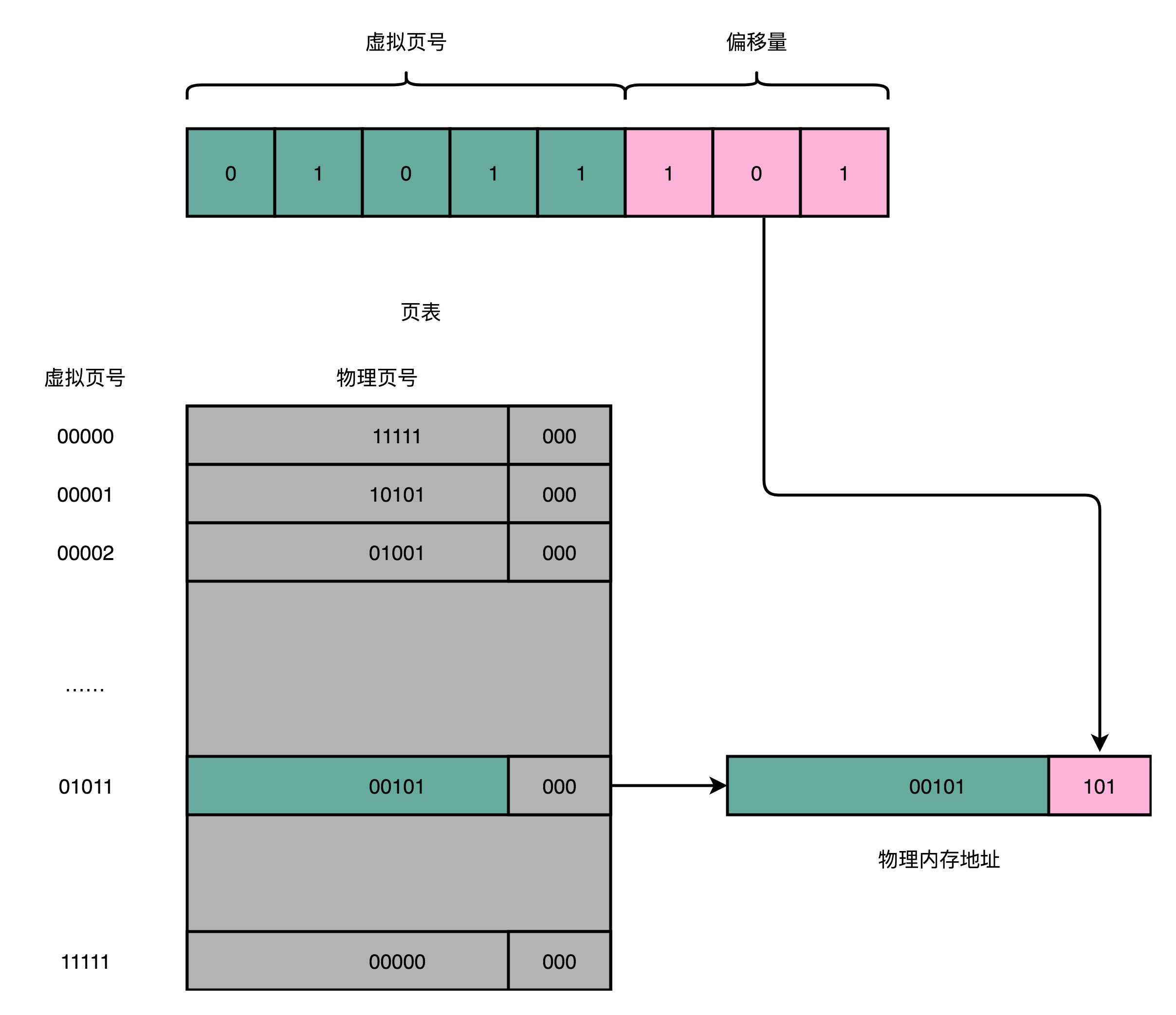
总结: 对于一个内存地址转换,其实就是这样三个步骤:
- 把虚拟内存地址,切分成页号和偏移量的组合;
- 从页表里面,查询出虚拟页号,对应的物理页号;
- 直接拿物理页号,加上前面的偏移量,就得到了物理内存地址。
下面我们先计算一下,这样一个页表需要多大的空间吗?我们还是以 32 位的内存地址空间为例,需要一个数组大小为 220 的数组,同时存储一个内存地址需要 4byte 大小,共需要内存大小为 4MB(= 220 * 4 byte)。根据虚拟页号查找物理页号公式如下:
物理页号 = arr[虚拟页号]
很显然,一个程序就需要 4MB,我们的计算机上运行上千个进程是很正常的,这样一算下来,光存储页表的开销就有 4GB 啊?你有没有更好的数据结构来存储页面呢?
3. 多级页表
很明显,大部分进程所占用的内存是有限的,我们只需要保存那些用到的页之间的映射关系就好了。如果你对数据结构比较熟悉,你可能要说了,那我们是不是应该用哈希表(HashMap)这样的数据结构呢?
很可惜你猜错了。在实践中,我们其实采用的是一种叫作多级页表(Multi-Level Page Table) 的解决方案。为什么我们不用哈希表而用多级页表呢?别着急,听我慢慢跟你讲。
3.1 进程的内存地址分配 - "两头实、中间空"
要知道为什么使用多级页表而不是哈希表,首先就要知道,一个进程的内存地址空间是怎么分配的。在整个进程的内存地址空间,通常是 "两头实、中间空"。在程序运行的时候,内存地址从顶部往下,不断分配占用的栈的空间。而堆的空间,内存地址则是从底部往上,是不断分配占用的。
所以,在一个实际的程序进程里面,虚拟内存占用的地址空间,通常是两段连续的空间。而不是完全散落的随机的内存地址。而多级页表,就特别适合这样的内存地址分布。
3.2 页表树
事实上,多级页表就像一个多叉树的数据结构,所以我们常常称它为页表树(Page Table Tree)。这种数据结构其实和 B+ 树类似,允许一个结点存储多条记录,并且非叶子结点只存储索引,只有叶子结点存储数据。
使用多级页表后,同样的虚拟内存地址,偏移量的部分和上面简单页表一样不变,而原先的页号部分需要拆分成多段。我们还是以一个 32 位的内存地址,页的大小 4KB 为例,其 20 个高位表示页号,12 个低位表示偏移量。如果拆分成一个 4 级的多级页表,需要将前 20 个高位从高到低,分成 4 级到 1 级这样 4 个页表索引。
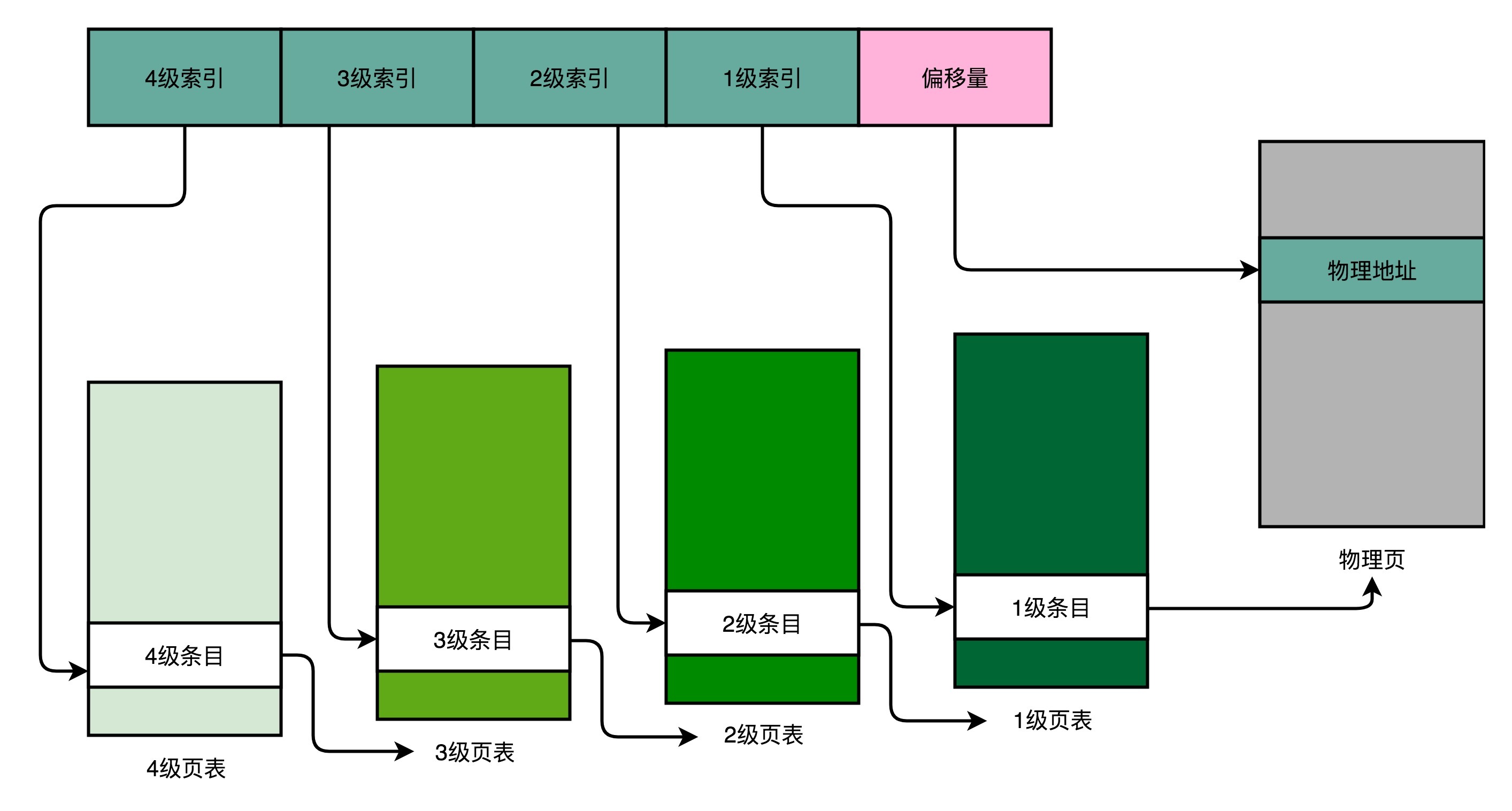
说明: 一个进程会有一个 4 级页表,通过虚拟地址查找物理地址时:
- 先通过 4 级页表索引,找到 4 级页表里面对应的条目(Entry)。这个条目里存放的是一张 3 级页表所在的地址。4 级页面里面的每一个条目,都对应着一张 3 级页表,所以我们可能有多张 3 级页表。
- 再根据 3 级页表索引,在 3 级页表中查找对应的 2 级页表地址。
- 依次类推,直到 1 级页表。在最后一级页表中,保存虚拟地址对应的物理地址页号。
多级页表的结构和 B+ 树非常类似,允许一个结点存储多条记录,并且非叶子结点只存储索引,只有叶子结点存储数据。
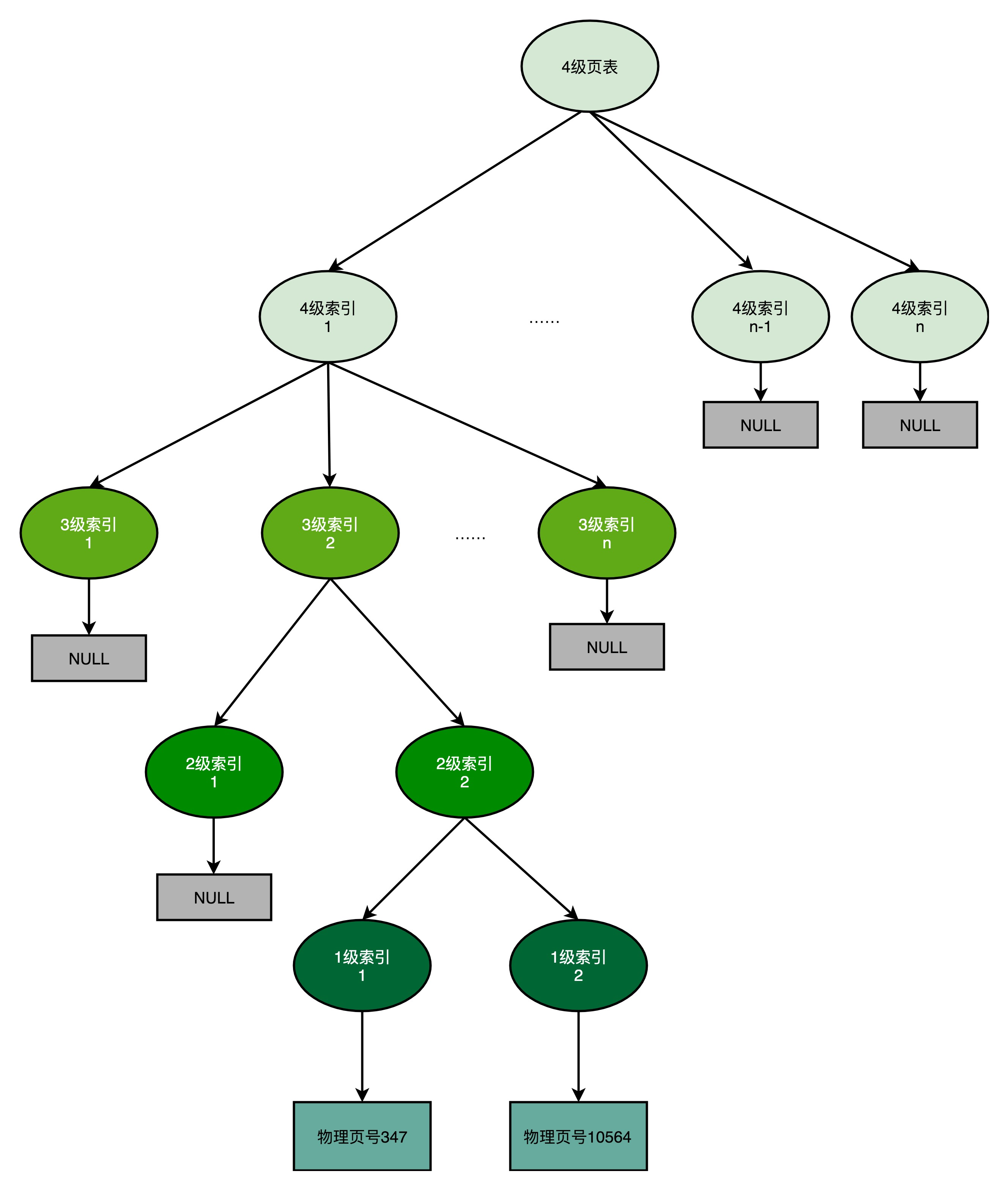
3.3 复杂度分析
3.3.1 空间复杂度
如果 32 位的内存地址(20 位页号 + 12 位偏移量)平均拆分成 4 级,每级都用 5 bit 表示,那么每张页表能存储 2^5 = 32 条记录。
- 满 1 级页表:一个满页大小 128 byte,可以映射 128 KB 内存地址。一个页表共 32 条记录,每条记录中存储物理内存对应的页号,需要 4 byte,而对应的一个页的大小为 4KB。
- 满 2 级页表:对应的就是 32 个 1 级页表,也就是 4MB(= 32 * 128 KB)。
那么,我们现在可以推算一下,一个进程占用 8MB 的内存空间需要多大的页表空间?8MB 分成了 2 个 4MB 的连续空间,一共需要 2 个独立的、填满的 2 级索引表,也就意味着 64 个 1 级索引表,2 个独立的 3 级索引表,1 个 4 级索引表。一共需要 69 个索引表,大概就是 9KB(= 69 * 128byte)。比起 4MB 来说,只有差不多 1/500。
3.3.2 时间复杂度
多级页表虽然节约了我们的存储空间,却带来了时间上的开销,所以多级页表其实是一个 "以时间换空间" 的策略。原本我们进行一次地址转换,只需要访问一次内存就能找到物理页号,算出物理内存地址。但是,用了 4 级页表,我们就需要访问 4 次内存,才能找到物理页号了。
4. 加速地址转换:TLB
多级页表以时间换空间的策略,大节省了内存开销。但使用 4 级页表后,就需要访问 4 次内存才能找到物理页号。而虚拟地址和物理内存地址之间的地址转换,是一个非常高频的动作,对它的性能要求非常高,你有什么好的解决方案呢?我们最先想到的可能就是加缓存,事实上,CPU 也是这么做的。
4.1 为什么可以使用缓存
程序所需要使用的指令,都顺序存放在虚拟内存里面。我们执行的指令,也是一条条顺序执行下去的。也就是说,对于指令地址和需要访问的数据,都存在空间局部性和时间局部性。
我们连续执行了 5 条指令,因为内存地址都是连续的,所以这 5 条指令通常都在同一个“虚拟页”里。我们可以把之前的内存转换地址缓存下来,使得不需要反复去访问内存来进行内存地址转换。

4.2 TLB
地址变换高速缓冲(Translation-Lookaside Buffer,TLB):是 CPU 中的一块缓存芯片,这块缓存存放了之前已经进行过地址转换的查询结果。有了 TLB ,当同样的虚拟地址需要进行地址转换的时候,我们可以直接在 TLB 查询结果,而不需要多次访问内存来完成一次转换。
TLB 和我们前面讲的 CPU 的高速缓存类似,可以分成指令的 TLB 和数据的 TLB,也就是 ITLB 和 DTLB。同样的,我们也可以根据大小对它进行分级,变成 L1、L2 这样多层的 TLB。另外,和高速缓存一样,同样需要用脏标记这样的标记位,来实现 "写回" 这样缓存管理策略。
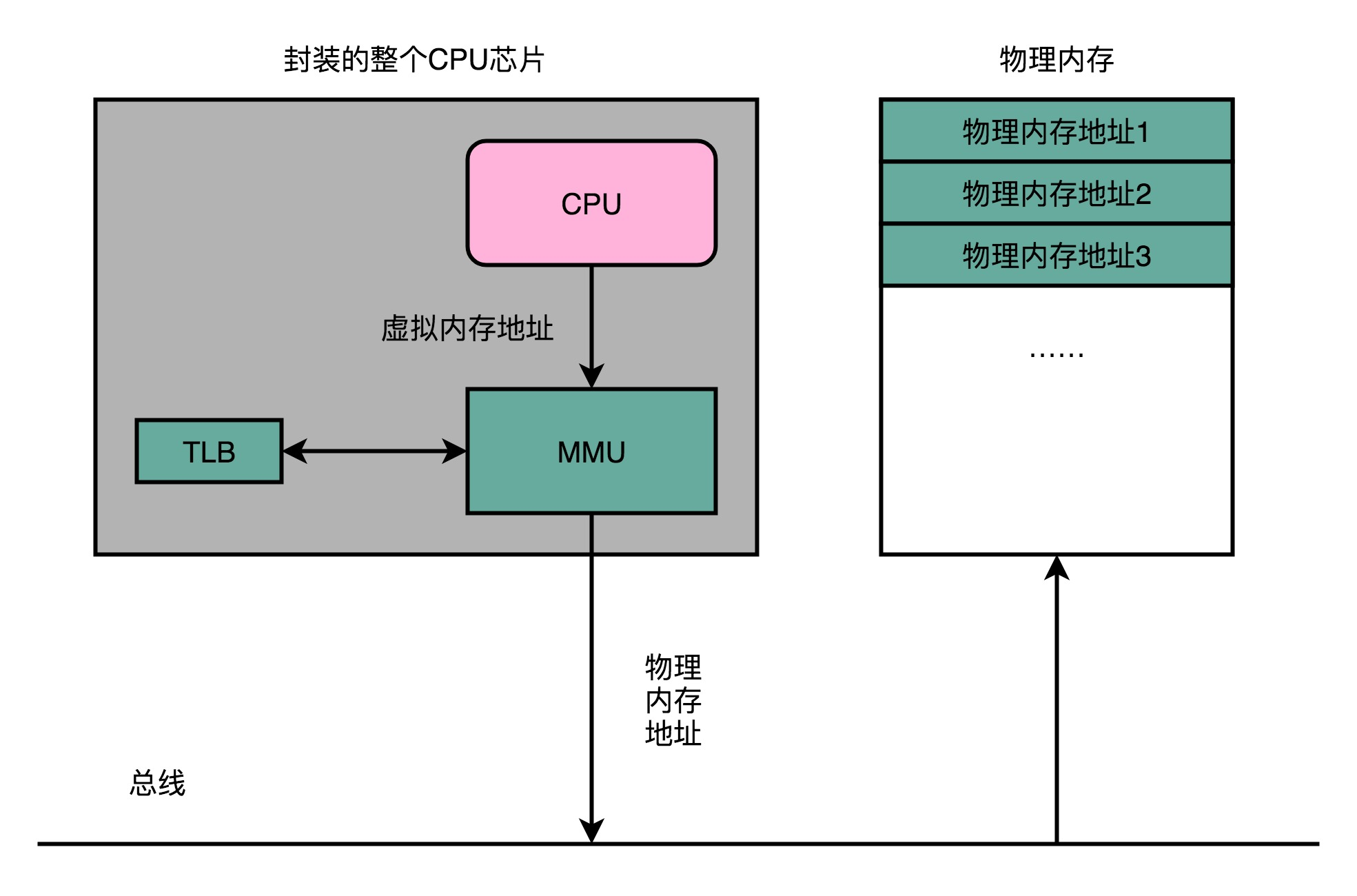
为了性能,我们整个内存转换过程也要由硬件来执行。在CPU芯片里面,我们封装了内存管理单元(MMU,Memory Management Unit)芯片,用来完成地址转换。和TLB的访问和交互,都是由这个 MMU 控制的。
参考:
- 《计算机组成与设计:硬件 / 软件接口》的第 5.7 章节:虚拟内存。
- 《What Every Programmer Should Know About Memory》的第 4 部分:Virtual Memory。
每天用心记录一点点。内容也许不重要,但习惯很重要!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号