存储器 - 高速缓存(CPU Cache):为什么要使用高速缓存
存储器 - 高速缓存(CPU Cache):为什么要使用高速缓存?
计算机组成原理目录:https://www.cnblogs.com/binarylei/p/12585607.html
1. 为什么需要高速缓存
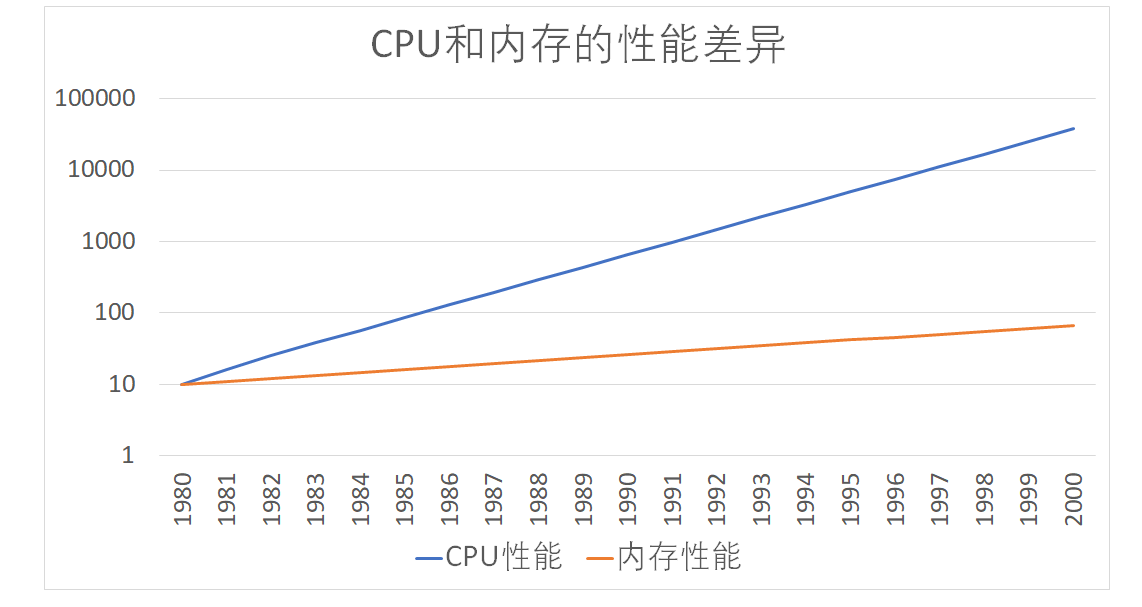
CPU 和内存访问性能的差距非常大。如今,一次内存的访问,大约需要 120 个 CPU Cycle。这也意味着,在今天,CPU 和内存的访问速度已经有了 120 倍的差距。
- CPU:按照摩尔定律,CPU 的访问速度每 18 个月便会翻一番,相当于每年增长 60%。比如我的笔记本是 Intel Core-i5-8250U 1.6GHz,也就是每秒可以访问 16 亿(= 1.6G)次。
- 内存:每年只增长 7% 左右。内存响应时间大概是 100us,也就是极限情况下,大概每秒可以访问 1000 万(= 1s / 100ns)次。
- HDD:磁盘寻道时间约 10ms,大概每秒可以访问 100 次。
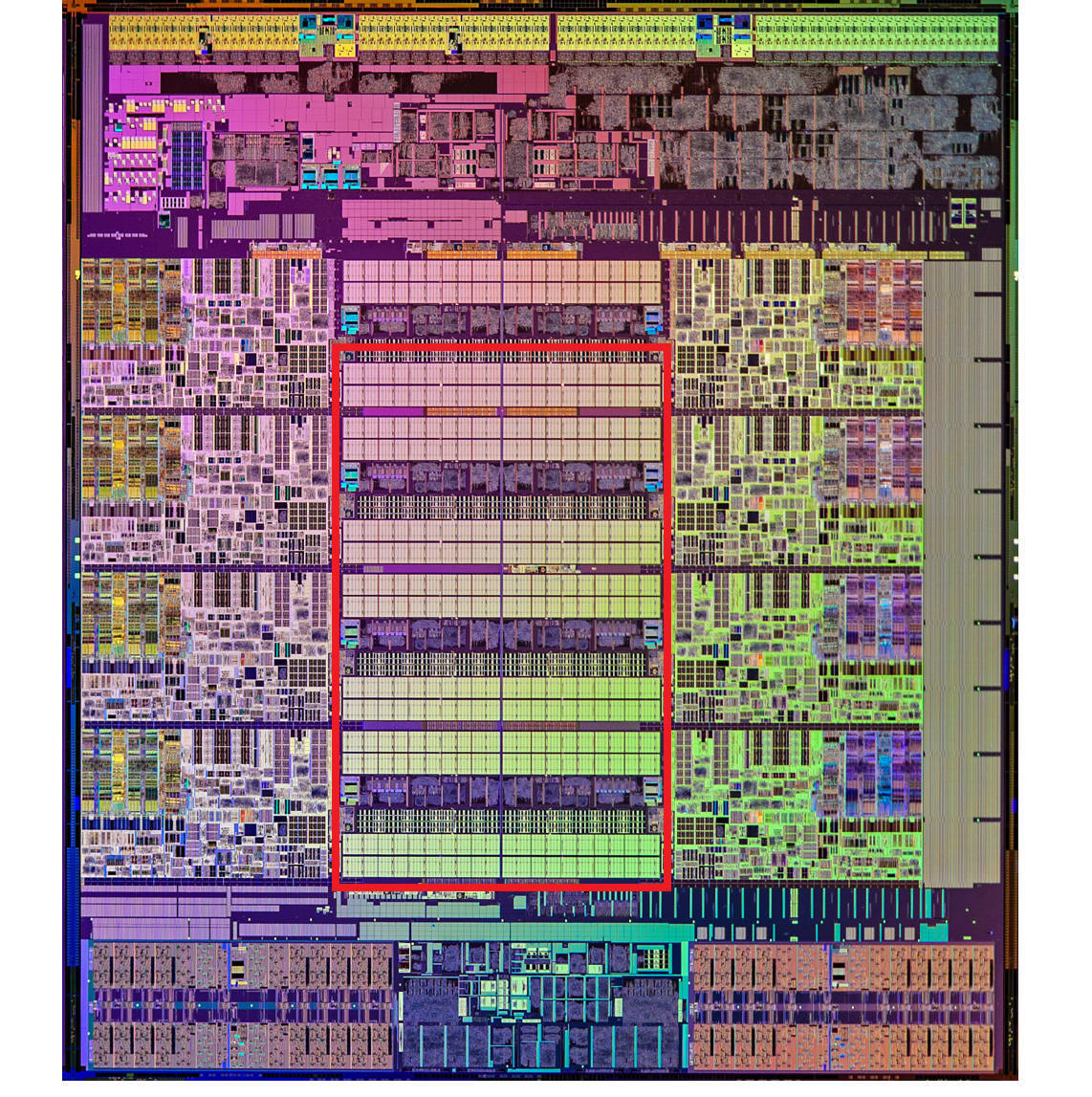
为了弥补两者之间的性能差异,充分利用 CPU,现代 CPU 中引入了高速缓存(CPU Cache)。高速缓存分为 L1/L2/L3 Cache,不是一个单纯的、概念上的缓存(比如使用内存作为硬盘的缓存),而是指特定的由 SRAM 组成的物理芯片。下图是一张 Intel CPU 的放大照片。这里面大片的长方形芯片,就是这个 CPU 使用的 20MB 的 L3 Cache,可以看到现代 CPU 中大量的空间已经被 SRAM 占据。
程序运行的时间主要花在将对应的数据从内存中读取出来,加载到 CPU Cache 里。CPU 从内存中读取数据到 CPU Cache 的过程中,是一小块一小块来读取数据的。这样一小块一小块的数据,在 CPU Cache 里面,我们把它叫作缓存行(Cache Line)。在我们日常使用的 Intel 服务器或者 PC 里,Cache Line 的大小通常是 64 字节。
现在总结一下,为了平衡 CPU 和内存的性能差异,现在 CPU 引入高速缓存:
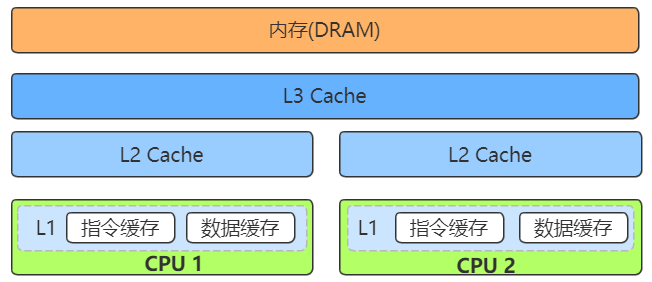
- 高速缓存(CPU Cache):用于平衡 CPU 和内存的性能差异,分为 L1/L2/L3 Cache。其中 L1/L2 是 CPU 私有,L3 是所有 CPU 共享。
- 缓存行(Cache Line):高速缓存的最小单元,一次从内存中读取的数据大小。常用的 Intel 服务器 Cache Line 的大小通常是 64 字节。
知道了为什么需要 CPU Cache,接下来我们就来看一看,CPU 究竟是如何访问 CPU Cache 的,以及 CPU Cache 是如何组织数据,使得 CPU 可以找到自己想要访问的数据的。
2. 高速缓存读操作
CPU Cache 和 Redis 缓存访问类似,都是先访问缓存,如果数据不存在再访问内存。在各类基准测试(Benchmark) 和实际应用场景中,CPU Cache 的命中率通常能达到 95% 以上。
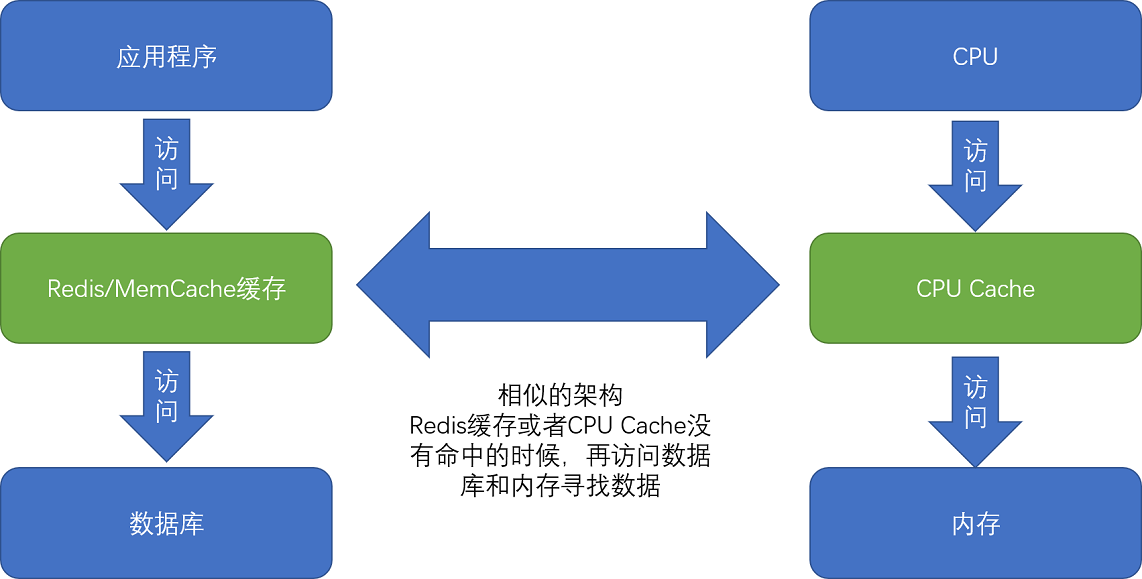
CPU 如何知道要访问的内存数据,存储在 Cache 的哪个位置呢?CPU 访问 Cache 的访问逻辑有以下几种。
- 直接映射 Cache(Direct Mapped Cache)
- 全相连 Cache(Fully Associative Cache)
- 组相连 Cache(Set Associative Cache)
2.1 直接映射(Direct Mapped Cache)
CPU 如何知道要访问的内存数据,存储在 Cache 的哪个位置呢?接下来,我就从最基本的直接映射 Cache(Direct Mapped Cache) 说起,带你来看整个 Cache 的数据结构和访问逻辑。
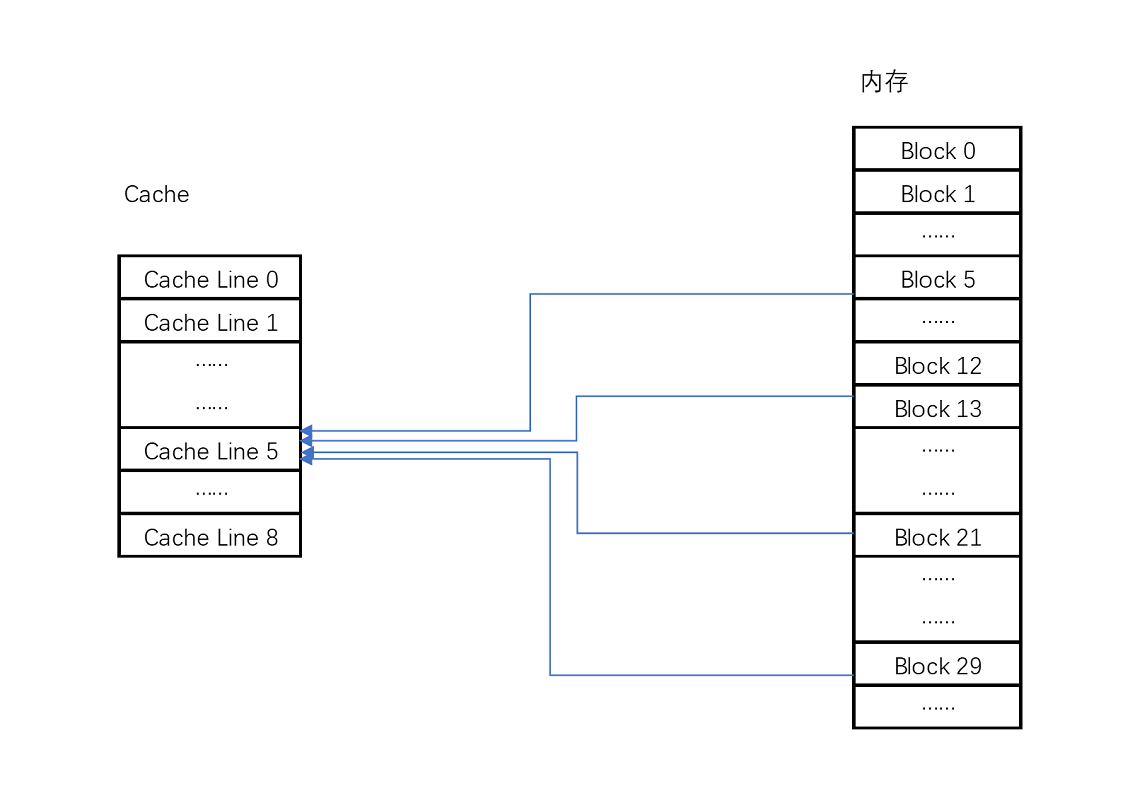
CPU 访问内存数据时按缓存行大小读写,通常是 64 byte。我们将内存将缓存行大小切分,每个内存地址必定会落到某个内存块上,数据在这个内存块的偏移量也是确定的。问题是如何将这个 "内存块 block" 和 "缓存行 Cache Line" 索引号映射关系确定下来。
- 索引号:CPU 直接映射是通过求余运算来实现,并且要求缓存行的个数必须是 2n。这样可以直接使用低位来表示索引号。
- 偏移量:可以根据块大小确定偏移量。
现在,我们知道了 Cache Line 的索引号和在这个 Cache Line 的偏移量,CPU 就可以在缓存行中读出这个数据了。通过索引号和偏移量建立内存映射关系,这在软件工程中很常见,比如内存的虚拟地址和物理地址之间的映射关系,再比如 innodb 中数据地址定位(页号 + 偏移量)。
比如说,我们的主内存被分成 0~31 号这样 32 个块。我们一共有 8 个缓存块。用户想要访问第 21 号内存块。如果 21 号内存块内容在缓存块中的话,它一定在 5 号缓存块(21 % 8 = 5)中。
了解 HashMap 的都知道,通过求余算法一定会出现哈希碰撞。同样的道理,此时也会出现多个内存块映射同一个缓存行的情况,CPU 如何判断这是不是我们想要访问的数据呢?
-
组标记(Tag):最简单的办法,当然是在缓存行中存储完整真实的物理内存地址,但有点浪费空间。前面已经说了缓存行的个数是 2n,可以直接使用低位表示索引号,也就是每个缓存行对应的低位地址是固定的,缓存行中只需要保存高位地址即可。
如 21 的低 3 位 101,缓存块本身的地址已经涵盖了对应的信息、对应的组标记,我们只需要记录 21 剩余的高 2 位的信息,也就是 10 就可以了。
-
有效位(valid bit):标记对应的缓存块中的数据是否是有效的,确保不是机器刚刚启动时候的空数据。如果有效位是 0,无论其中的组标记和 Cache Line 里的数据内容是什么,CPU 都不会管这些数据,而要直接访问内存,重新加载数据。
现在我们总结一下:一个内存的访问地址,最终包括高位代表的组标记、低位代表的索引,以及在对应的 Data Block 中定位对应字的位置偏移量。
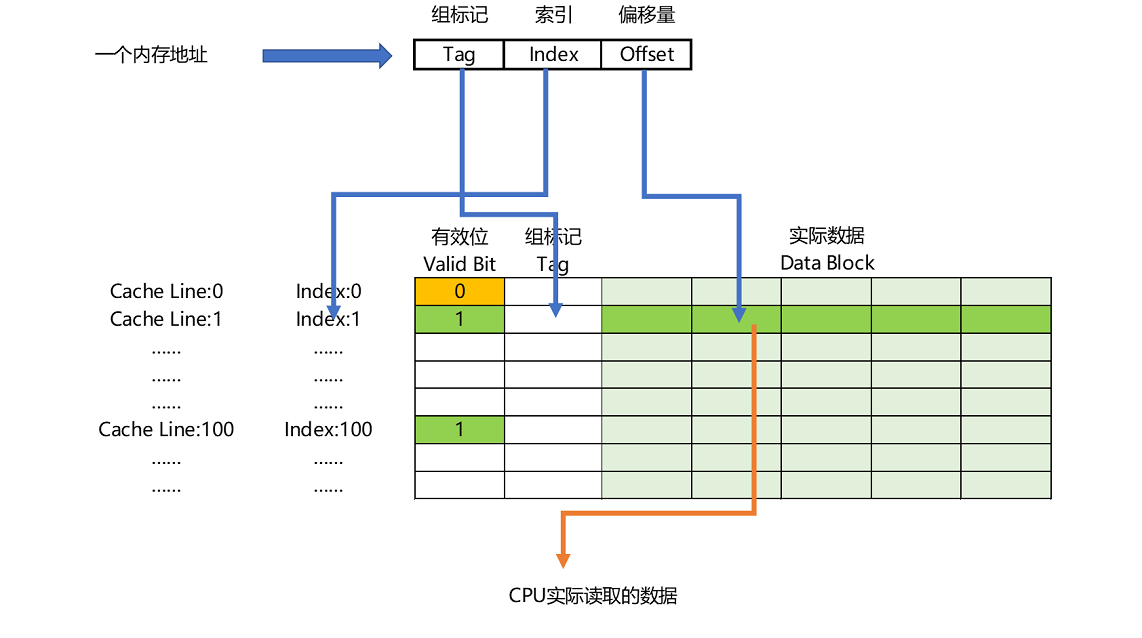
而内存地址对应到 Cache 里的数据结构,则多了一个有效位和对应的数据,由 "索引 + 有效位 + 组标记 + 数据" 组成。如果内存中的数据已经在 CPU Cache 里了,那一个内存地址的访问,就会经历这样 5 个步骤:
- 根据内存地址的低位,计算在 Cache 中的索引;
- 判断有效位,确认 Cache 中的数据是有效的;
- 对比内存访问地址的高位,和 Cache 中的组标记,确认 Cache 中的数据就是我们要访问的内存数据,从 Cache Line 中读取到对应的数据块(Data Block);
- 根据内存地址的 Offset 位,从 Data Block 中,读取希望读取到的字。
- 如果在 2、3 这两个步骤中,CPU 发现,Cache Line 并不是要访问的内存地址的数据,那 CPU 就会访问内存,并把对应的 Block Data 更新到 Cache Line 中,同时更新该 Cache Line 对应的有效位和组标记的数据。
总结: 要想确定一个内存地址在缓存中的映射关系,主要是确定索引号和偏移量。 CPU Cache 直接映射类似 HashMap,也是通过求余来建立映射关系,当然也无法避免哈希碰撞。CPU 判断是不是我们想要访问的数据时,最简单的办法当然是在缓存中存储完整真实的物理内存地址,但这样太浪费空间了,CPU 巧妙地将内存地址拆分成高位和低位,用高位代表组标记,低位代表索引号。最终通过 "索引 + 组标记 + 偏移量" 建立映射关系,使得我们可以将很大的内存地址,映射到很小的 CPU Cache 地址里。
3. 高速缓存写操作
在搞清楚从内存加载数据到 Cache,以及从 Cache 里读取到想要的数据之后,我们又要面临一个新的挑战。CPU 不仅要读数据,还需要写数据,我们不能只把数据写入到 Cache 里面就结束了。CPU 要写入数据的时候,怎么既不牺牲性能,又能保证数据的一致性。
3.1 写操作挑战
CPU 数据写入时会有以下两个挑战:
- 什么时候写入主存?缓存什么时候失效?写直达 vs 写回策略。写入 Cache 的性能也比写入主内存要快,那我们写入的数据,到底应该写到 Cache 里还是主内存呢?如果我们直接写入到主内存里,Cache 里的数据是否会失效呢?CPU 提供了写直达 vs 写回两种策略。
- 多核 CPU 缓存一致性的问题。无论是写直达还是写回策略都不能解决多核 CPU 缓存一致性的问题。现在计算机采用缓存一致性协议 MESI 解决一致性问题。
下面先介绍这两种写入策略。
- 写直达(Write-Through):每一次数据都要写入到主内存里面。
- 写回(Write-Back):数据写到 CPU Cache 就结束。只有当 CPU Cache 是脏数据时,才把数据写入主内存。
3.2 写直达(Write-Through)
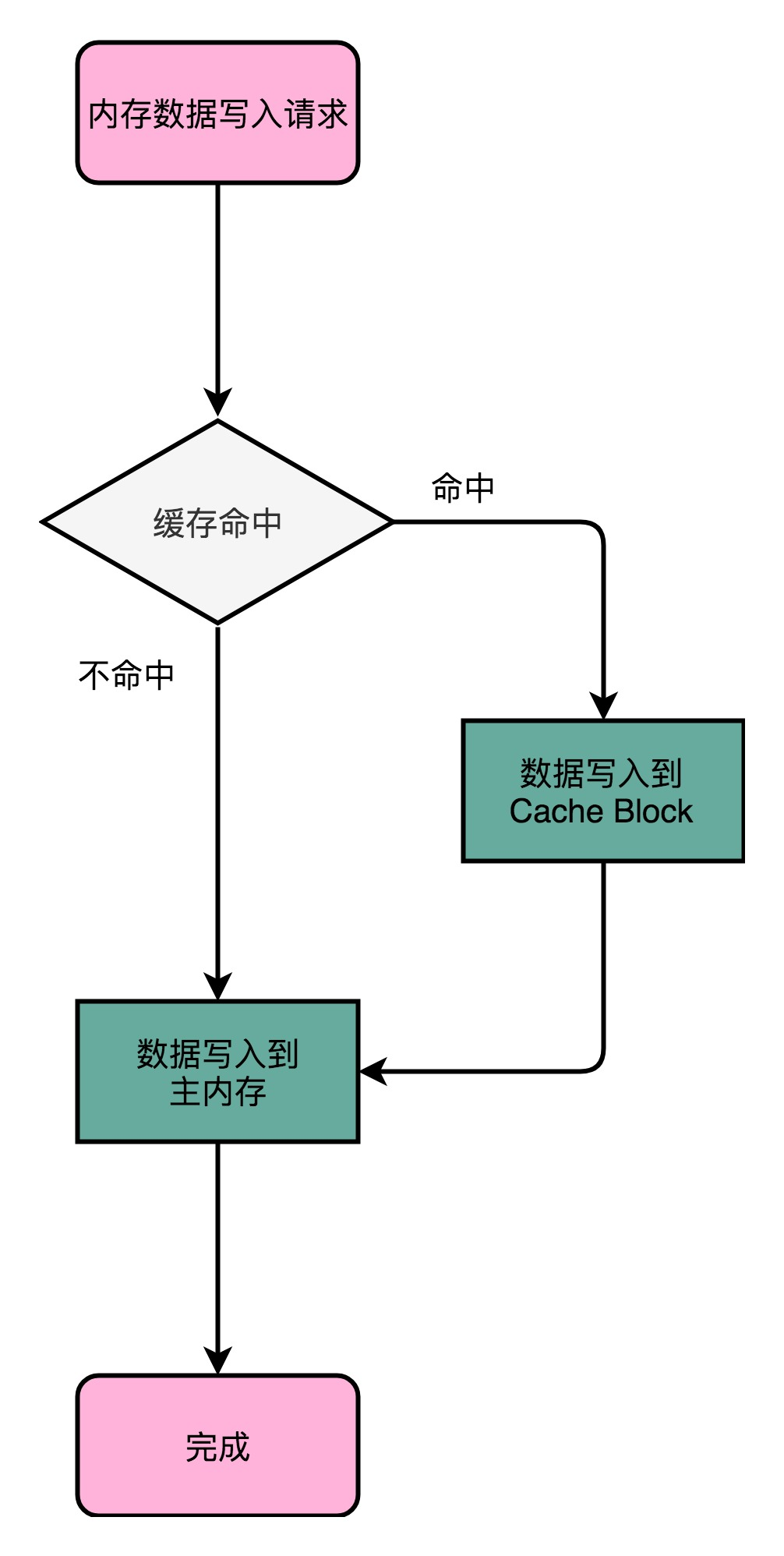
写直达策略中,每一次数据都要写入到主内存里面。写入前,先判断数据是否已经在 Cache 里面了。
- 命中缓存。如果数据已经在 Cache 里,先把数据写入更新到 Cache 里面,再写入到主内存里面;
- 未命中缓存。如果数据不在 Cache 里,只需要更新主内存。
写直达的这个策略很直观,但是问题也很明显,那就是这个策略很慢。
3.3 写回(Write-Back)
既然可以从 CPU Cache 里面加载数据,那么写入时能否只写入 CPU Cache 中,不用同步到主内存里呢?当然是可以的。CPU 提供了写回策略,不再是每次都把数据写入到主内存,而是只写到 CPU Cache 里。只有当 CPU Cache 里面的数据要被“替换”的时候,我们才把数据写入到主内存里面去。
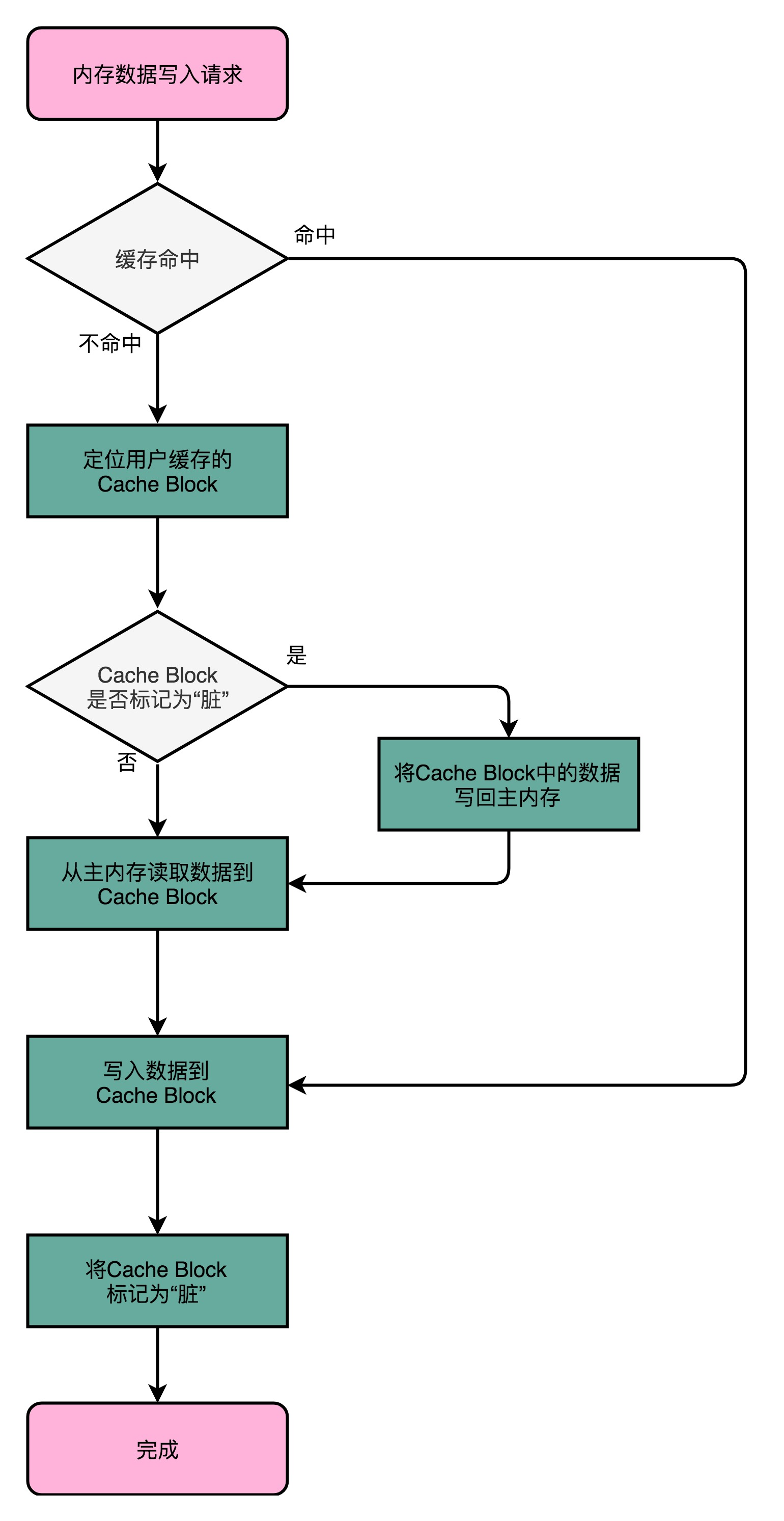
- 命中缓存。如果要写入的数据,就在 CPU Cache 里面,那么只是更新 CPU Cache 里面的数据。同时标记 CPU Cache 里的这个 Block 是脏(Dirty)的。所谓脏的,就是指这个时候,我们的 CPU Cache 里面的这个 Block 的数据,和主内存是不一致的。
- 未命中缓存。如果要写入的数据所对应的 Cache Block 里,放的是别的内存地址的数据,需要判断 Cache Block 里面的数据有没有被标记成脏的。
- 如果是脏数据,我们要先把这个 Cache Block 里面的数据,写入到主内存里面。然后,再把当前要写入的数据,写入到 Cache 里,同时把 Cache Block 标记成脏的。
- 如果没有被标记成脏数据,那么我们直接把数据写入到 Cache 里面,然后再把 Cache Block 标记成脏的就好了。
- 加载缓存。加载内存数据到 Cache 里面的时候,也要多出一步同步脏 Cache 的动作。如果加载内存里面的数据到 Cache 的时候,发现 Cache Block 里面有脏标记,我们也要先把 Cache Block 里的数据写回到主内存,才能加载数据覆盖掉 Cache。
可以看到,在写回这个策略里,如果我们大量的操作,都能够命中缓存。那么大部分时间里,我们都不需要读写主内存,自然性能会比写直达的效果好很多。
参考:
- What Every Programmer Should Know About Memory:深入了解 CPU 和内存之间的访问性能。
- Fixing Java Memory Model:JSR-133 为什么增强 volatile 的内存语义。
- CPU 高速缓存的读操作处理:《计算机组成与设计:硬件 / 软件接口》的 5.4.1 小节。现代 CPU 已经很少使用直接映射 Cache 了,通常用的是组相连 Cache(set associative cache)。
- CPU 高速缓存的写操作处理:《计算机组成与设计:硬件 / 软件接口》的 5.3.3 小节。
每天用心记录一点点。内容也许不重要,但习惯很重要!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号