Dubbo 系列(07-3)集群容错 - 负载均衡
Dubbo 系列(07-3)集群容错 - 负载均衡
Spring Cloud Alibaba 系列目录 - Dubbo 篇
1. 背景介绍
相关文档推荐:
在 Dubbo 的整个集群容错流程中,首先经过 Directory 获取所有的 Invoker 列表,然后经过 Routers 根据路由规则过滤 Invoker,最后幸存下来的 Invoker 还需要经过负载均衡 LoadBalance 这一关,选出最终调用的 Invoker。在前篇文章已经分析了 服务字典 和 服务路由 的基本原理,接下来继续分析 LoadBalance。
1.1 负载均衡算法
Dubbo-2.7.3 提供了 4 种负载均衡实现,分别是:
- 加权随机算法:RandomLoadBalance。请求较少时产生的随机数可能会比较集中,此时多数请求会落到同一台服务器上,多数情况下可以忽略,请求越多分布越平均。RandomLoadBalance 是 Dubbo 默认的负载均衡算法。
- 加权轮询算法: RoundRobinLoadBalance。处理慢的节点会成为瓶颈。
- 一致性 Hash: ConsistentHashLoadBalance。粘滞连接,尽可能让客户端总是向同一服务提供者发起调用,除非该提供者挂了。
- 最少活跃调用数算法:LeastActiveLoadBalance。请求处理前时加 1,处理完后减 1,这样处理慢的节点的活跃调用数会越来越大。最终,处理快的节点会承担更多的请求。
1.2 继承体系
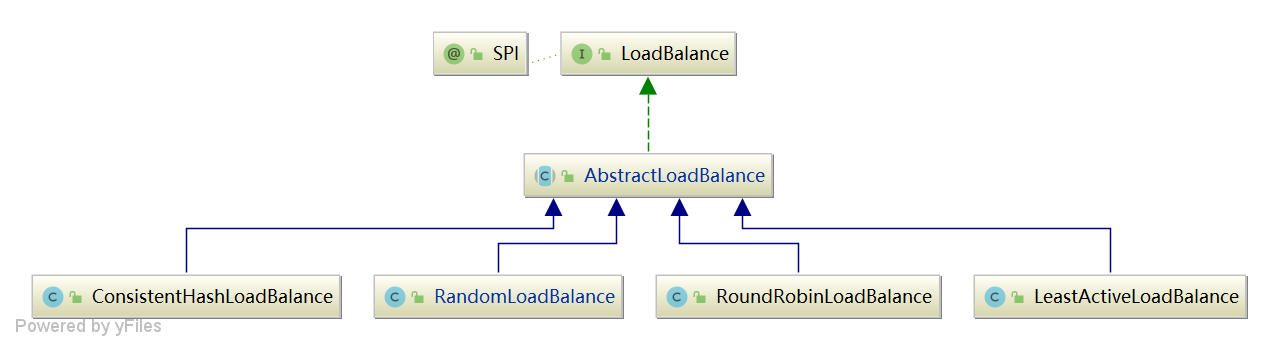
总结: 四种 负载均衡实现类均继承自 AbstractLoadBalance, 该类实现了 LoadBalance 接口,还封装了一些公共逻辑 ,比如服务提供者权重计算逻辑。
Dubbo 默认是基于权重随机算法的 RandomLoadBalance,根据 loadbalance 参数可以指定负载均衡算法。接口定义如下:
@SPI(RandomLoadBalance.NAME)
public interface LoadBalance {
@Adaptive("loadbalance")
<T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException;
}
2. 源码分析
2.1 AbstractLoadBalance
AbstractLoadBalance 除了实现了 LoadBalance 接口,还提供了服务提供者权重计算逻辑。
2.1.1 LoadBalance 入口
首先来看一下负载均衡的入口方法 select,如下:
@Override
public <T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) {
if (CollectionUtils.isEmpty(invokers)) {
return null;
}
// 如果 invokers 列表中仅有一个 Invoker,直接返回即可,无需进行负载均衡
if (invokers.size() == 1) {
return invokers.get(0);
}
// 调用 doSelect 方法进行负载均衡,该方法为抽象方法,由子类实现
return doSelect(invokers, url, invocation);
}
总结: select 本身的逻辑很简单,将具体的负载均衡算法委托给子类 doSelect 实现。
2.1.2 权重计算
AbstractLoadBalance 还提供了服务提供者权重计算逻辑。具体实现如下:
protected int getWeight(Invoker<?> invoker, Invocation invocation) {
// 从 url 中获取指定方法权重 weight 配置值,默认值为 100
int weight = invoker.getUrl().getMethodParameter(invocation.getMethodName(), WEIGHT_KEY, DEFAULT_WEIGHT);
if (weight > 0) {
// 获取服务提供者启动时间戳
long timestamp = invoker.getUrl().getParameter(REMOTE_TIMESTAMP_KEY, 0L);
if (timestamp > 0L) {
// 计算服务提供者运行时长
int uptime = (int) (System.currentTimeMillis() - timestamp);
// 获取服务预热时间,默认为10分钟
int warmup = invoker.getUrl().getParameter(WARMUP_KEY, DEFAULT_WARMUP);
// 如果服务运行时间小于预热时间,则重新计算服务权重,即降权
if (uptime > 0 && uptime < warmup) {
// 重新计算服务权重
weight = calculateWarmupWeight(uptime, warmup, weight);
}
}
}
return weight >= 0 ? weight : 0;
}
总结: 权重的计算分两步:一是获取指定方法 weight 参数,默认值是 100;二是如果服务的启动时间小于预热时间,根据比例(uptime/warmup)重新计算权重大小,也就是通常说的冷启动。
冷启动的目的是对服务进行降权,避免让服务在启动之初就处于高负载状态。服务预热是一个优化手段,与此类似的还有 JVM 预热。主要目的是让服务启动后“低功率”运行一段时间,使其效率慢慢提升至最佳状态。
static int calculateWarmupWeight(int uptime, int warmup, int weight) {
// 计算权重,下面代码逻辑上形似于 (uptime / warmup) * weight。
// 随着服务运行时间 uptime 增大,权重计算值 ww 会慢慢接近配置值 weight
int ww = (int) ((float) uptime / ((float) warmup / (float) weight));
return ww < 1 ? 1 : (ww > weight ? weight : ww);
}
2.2 RandomLoadBalance
RandomLoadBalance 是加权随机算法的具体实现,它的算法思想很简单。假设我们有一组服务器 servers = [A, B, C],他们对应的权重为 weights = [5, 3, 2],权重总和为10。现在把这些权重值平铺在一维坐标值上,[0, 5) 区间属于服务器 A,[5, 8) 区间属于服务器 B,[8, 10) 区间属于服务器 C。接下来通过随机数生成器生成一个范围在 [0, 10) 之间的随机数,然后计算这个随机数会落到哪个区间上。比如数字3会落到服务器 A 对应的区间上,此时返回服务器 A 即可。
@Override
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
// 1. 构建每个 Invoker 对应的权重数组 weights[]
int length = invokers.size();
// 1.1 sameWeight表示是否所有的 Invoker 具有相同的权重值
boolean sameWeight = true;
int[] weights = new int[length];
int firstWeight = getWeight(invokers.get(0), invocation);
weights[0] = firstWeight;
int totalWeight = firstWeight;
// 1.2 计算总权重 totalWeight,并检测每个服务提供者的权重是否相同 sameWeight
for (int i = 1; i < length; i++) {
int weight = getWeight(invokers.get(i), invocation);
weights[i] = weight;
totalWeight += weight;
if (sameWeight && weight != firstWeight) {
sameWeight = false;
}
}
// 2. 权重值不相等时,计算随机数落在哪个区间上
if (totalWeight > 0 && !sameWeight) {
// 随机获取一个 [0, totalWeight) 区间内的数字
int offset = ThreadLocalRandom.current().nextInt(totalWeight);
// 循环让 offset 数减去服务提供者权重值,当 offset 小于0时,返回相应的 Invoker。
// 举例说明一下,我们有 servers = [A, B, C],weights = [5, 3, 2],offset = 7。
// 第一次循环,offset - 5 = 2 > 0,即 offset > 5,
// 表明其不会落在服务器 A 对应的区间上。
// 第二次循环,offset - 3 = -1 < 0,即 5 < offset < 8,
// 表明其会落在服务器 B 对应的区间上
for (int i = 0; i < length; i++) {
// 让随机值 offset 减去权重值
offset -= weights[i];
if (offset < 0) {
// 返回相应的 Invoker
return invokers.get(i);
}
}
}
// 3. 权重值相同,此时直接随机返回一个即可
return invokers.get(ThreadLocalRandom.current().nextInt(length));
}
总结: RandomLoadBalance 的算法比较简单,大致分为三步:
- 计算每个 Invoker 对应的权重数组 weights[]
- 权重值不相等时,计算随机数落在哪个区间上
- 权重值相同,此时直接随机返回一个
RandomLoadBalance 经过多次请求后,能够将调用请求按照权重值进行“均匀”分配。它是一个简单、高效的负载均衡实现,因此 Dubbo 选择它作为缺省实现。
2.3 LeastActiveLoadBalance
LeastActiveLoadBalance 翻译过来是最小活跃数负载均衡。活跃调用数越小,表明该服务提供者效率越高,单位时间内可处理更多的请求。此时应优先将请求分配给该服务提供者。
LeastActiveLoadBalance 需要配合 ActiveLimitFilter 使用,这个过滤器会记录每个接口方法的活跃数,进行负载均衡时每次也只从活跃数最少的 Invoker 里选出一个 Invoker 来执行。
LeastActiveLoadBalance 可以看成是 RandomLoadBalance 的加强版,因为如果选出有多个活跃数最小的 invokers,之后的逻辑和 RandomLoadBalance 完全一样。
2.3.1 算法实现
@Override
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
// 1. 初始化各种计数器
int length = invokers.size();
int leastActive = -1;
int leastCount = 0;
int[] leastIndexes = new int[length];
int[] weights = new int[length];
int totalWeight = 0;
int firstWeight = 0;
boolean sameWeight = true;
// 2. pk获取活跃数最小的invokers
for (int i = 0; i < length; i++) {
Invoker<T> invoker = invokers.get(i);
// 2.1 核心,获取活跃数
int active = RpcStatus.getStatus(invoker.getUrl(), invocation.getMethodName()).getActive();
int afterWarmup = getWeight(invoker, invocation); // 权重值
weights[i] = afterWarmup;
// 2.2 pk获取新的最小活跃数(第一个,之前的最小活跃数清空)
if (leastActive == -1 || active < leastActive) {
leastActive = active; // 重新记录最小活跃数
leastCount = 1; // 重新记录最小活跃个数
leastIndexes[0] = i; // 重新记录 Invoker
totalWeight = afterWarmup; // 重新记录总权重值
firstWeight = afterWarmup; // 重新记录总权重
sameWeight = true; // 重新记录是否权重值相等
// 2.3 pk获取相同的最小活跃数(多个)
} else if (active == leastActive) {
leastIndexes[leastCount++] = i;
totalWeight += afterWarmup; // 等同于RandomLoadBalance
if (sameWeight && i > 0
&& afterWarmup != firstWeight) {
sameWeight = false;
}
}
}
// 3. 如果同时有多个活跃数最小的 invokers,等同于 RandomLoadBalance
if (leastCount == 1) {
return invokers.get(leastIndexes[0]);
}
if (!sameWeight && totalWeight > 0) {
int offsetWeight = ThreadLocalRandom.current().nextInt(totalWeight);
for (int i = 0; i < leastCount; i++) {
int leastIndex = leastIndexes[i];
offsetWeight -= weights[leastIndex];
if (offsetWeight < 0) {
return invokers.get(leastIndex);
}
}
}
return invokers.get(leastIndexes[ThreadLocalRandom.current().nextInt(leastCount)]);
}
总结: 最后可以看到 LeastActiveLoadBalance 相比于 RandomLoadBalance 除了多出最小活跃数的比较外,其余的基本一致。
int active = RpcStatus.getStatus(invoker.getUrl(), invocation.getMethodName()).getActive();
2.3.2 最小活跃数统计
在 ActiveLimitFilter 中,请求处理前计数器 +1,请求处理后(不管成功或失败或异常)计数器 -1,这个计数器就是最小活跃数。相当于以下模拟代码,当然真实的 Filter 处理比这个要复杂一些。
try {
RpcStatus.beginCount(url, methodName, max);
...
RpcStatus.endCount(url, methodName, getElapsed(invocation), true)
} catch(Exception e) {
RpcStatus.endCount(url, methodName, getElapsed(invocation), false);
}
2.4 ConsistentHashLoadBalance
关于 一致性Hash 的原理 和 一致性Hash的替代品?哈希槽的时代来临了,这两篇文章对 Hash取模 -> 一致性Hash -> Hash槽 演进过程讲解的十分清楚。
一致性 Hash 负载均衡可以让参数相同的请求每次都路由到相同的服务器上,这种负载均衡策略可以让某些节点下线时,请求会平摊到其他服务提供者,不会引起剧烈变动。
2.4.1 一致性 Hash 原理
如果有 A、B、C 三台服务器,如果同时有 1000 个请求到达,想让参数相同的请求尽量均匀的分布到这三台服务器上,怎么办呢?
(1)Hash取模
最简单的办法就是 Hash 取模,这样参数相同的请求就会落到同一台服务器上。
核心算法:hash(请求参数) % 3
那么问题来了,如果这时突然有一台服务器挂了,这时就是对 2 取模,也是说请求会重新分配服务器。有没有办法尽可能避免这种情况呢?
(2)一致性 Hash
一致性 hash 算法也是取模算法,只是之前是对服务器数量取模,一致性 hash 算法是对 2^32 取模。
核心算法:hash(服务器地址) % 2^32
请求地址:hash(请求参数) % 2^32
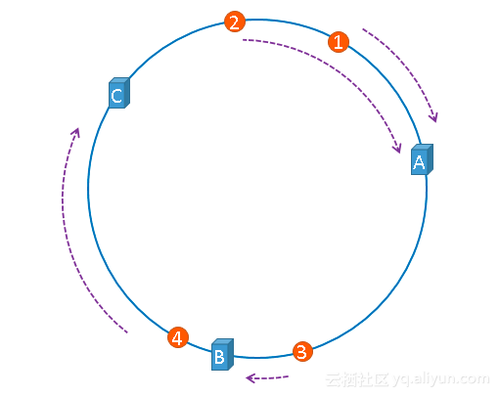
服务器地址和请求都对 2^32 取模后,必然都会落到上述的 hash 环上,那如何将请求和服务器对应上呢?按顺时针的方向,依次将请求分发到对应的服务器。这样做的好处是:当某台服务器宕机或新增加服务器时,只会影响这台服务器对应的请求。
那一致性 hash 有什么问题呢?理想情况下,这三台服务器均匀的分布在 hash 环上,这样请求也可以均匀的分发给这三台服务器,但现实是这三台服务器的地址取模后都在一起,这样导致大量的请求落到一个服务器上。
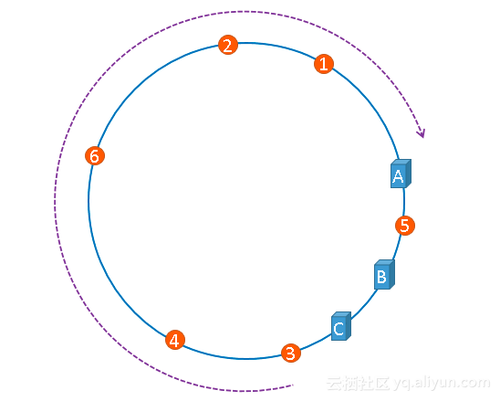
(3)Hash槽
针对一致性 hash 出现的数据倾斜问题,又演化出了 hash 槽的概念。 hash 槽解决数据倾斜的思路:既然问题是服务器在 hash 槽上分布不均匀造成的,那么可以虚拟出 n 份 A、B、C 服务器,让这些服务器相对均匀的分布在 hash 环上。

如上所示,相同颜色的节点均属于同一个服务提供者,比如 Invoker1-1,Invoker1-2,……, Invoker1-160。这样做的目的是通过引入虚拟节点,让 Invoker 在圆环上分散开来,避免数据倾斜问题。所谓数据倾斜是指,由于节点不够分散,导致大量请求落到了同一个节点上,而其他节点只会接收到了少量请求的情况。
2.4.2 算法实现
了解了一致性 hash 的基本原理,我们从 doSelect 方法来看一下一致性 hash 负载均衡的算法实现。
@Override
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
String methodName = RpcUtils.getMethodName(invocation);
String key = invokers.get(0).getUrl().getServiceKey() + "." + methodName;
int identityHashCode = System.identityHashCode(invokers);
ConsistentHashSelector<T> selector = (ConsistentHashSelector<T>) selectors.get(key);
// 当invokers发生变化时,重新生成ConsistentHashSelector
if (selector == null || selector.identityHashCode != identityHashCode) {
selectors.put(key, new ConsistentHashSelector<T>(invokers, methodName, identityHashCode));
selector = (ConsistentHashSelector<T>) selectors.get(key);
}
return selector.select(invocation);
}
总结: doSelect 的核心算法都委托给 ConsistentHashSelector 完成,需要注意的是每当 invokers 列表发生变化时都会重新生成该对象。
(1)生成 hash 槽
ConsistentHashSelector(List<Invoker<T>> invokers, String methodName, int identityHashCode) {
// virtualInvokers是虚拟hash槽
this.virtualInvokers = new TreeMap<Long, Invoker<T>>();
this.identityHashCode = identityHashCode;
URL url = invokers.get(0).getUrl();
this.replicaNumber = url.getMethodParameter(methodName, HASH_NODES, 160);
String[] index = COMMA_SPLIT_PATTERN.split(url.getMethodParameter(methodName, HASH_ARGUMENTS, "0"));
// 1. 获取参与 hash 计算的参数下标值,默认对第一个参数进行 hash 运算
argumentIndex = new int[index.length];
for (int i = 0; i < index.length; i++) {
argumentIndex[i] = Integer.parseInt(index[i]);
}
// 2. 构建虚拟hash槽,replicaNumber=160,相当于在hash槽上放160个槽位
// 外层轮询40次,内层轮询4次,共40*4=160次,也就是同一节点虚拟出160个槽位
for (Invoker<T> invoker : invokers) {
String address = invoker.getUrl().getAddress();
for (int i = 0; i < replicaNumber / 4; i++) {
// 2.1 对 address + i 进行 md5 运算,得到一个长度为16的字节数组
byte[] digest = md5(address + i);
// 2.2 对 digest 部分字节进行4次 hash 运算,得到四个不同的 long 型正整数
for (int h = 0; h < 4; h++) {
// h = 0 时,取 digest 中下标为 0 ~ 3 的4个字节进行位运算
// h = 1 时,取 digest 中下标为 4 ~ 7 的4个字节进行位运算
// h = 2, h = 3 时过程同上
long m = hash(digest, h);
virtualInvokers.put(m, invoker);
}
}
}
}
总结: ConsistentHashSelector 构建主要任务是构建 hash 槽,另外就是确认参数一致性 hash 的参数个数,默认是第一个参数。在 for 循环中,可以看到每个 Invoker 都虚拟出了 160 个槽位,无论代码写的有多么复杂,都是为了让 Invoker 尽可能的在 hash 环上均匀分布。
(2)hash 匹配
public Invoker<T> select(Invocation invocation) {
String key = toKey(invocation.getArguments()); // 参与一致性hash的参数
byte[] digest = md5(key);
return selectForKey(hash(digest, 0)); // 请求匹配
}
// 匹配请求参数在hash环上对应的Invoker
private Invoker<T> selectForKey(long hash) {
// TreeMap 中查找第一个节点值大于或等于当前 hash 的 Invoker
Map.Entry<Long, Invoker<T>> entry = virtualInvokers.ceilingEntry(hash);
// 如果 hash 大于 Invoker 在圆环上最大的位置,此时 entry = null,
// 需要将 TreeMap 的头节点赋值给 entry
if (entry == null) {
entry = virtualInvokers.firstEntry();
}
return entry.getValue();
}
总结: 选择的过程相对比较简单了。首先是对参数进行 md5 以及 hash 运算,得到一个 hash 值。然后再拿这个值到 TreeMap 中查找目标 Invoker 即可。
2.5 RoundRobinLoadBalance
... 以后再研究。
每天用心记录一点点。内容也许不重要,但习惯很重要!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号