JUC源码分析-集合篇(九)SynchronousQueue
JUC源码分析-集合篇(九)SynchronousQueue
SynchronousQueue 是一个同步阻塞队列,它的每个插入操作都要等待其他线程相应的移除操作,反之亦然。SynchronousQueue 像是生产者和消费者的会合通道,它比较适合“切换”或“传递”这种场景:一个线程必须同步等待另外一个线程把相关信息/时间/任务传递给它。
SynchronousQueue(后面称SQ)内部没有容量,所以不能通过 peek 方法获取头部元素;也不能单独插入元素,可以简单理解为它的插入和移除是“一对”对称的操作。为了兼容 Collection 的某些操作(例如contains),SQ 扮演了一个空集合的角色。
SQ 的一个典型应用场景是在线程池中,Executors.newCachedThreadPool() 就使用了它,这个构造使线程池根据需要(新任务到来时)创建新的线程,如果有空闲线程则会重复使用,线程空闲了 60s 后会被回收。
1. 实现自己的 SQ
SQ 实现原理参考:http://ifeve.com/java-synchronousqueue/
1.1 阻塞算法实现
阻塞算法实现通常在内部采用一个锁来保证多个线程中的 put() 和 take() 方法是串行执行的。采用锁的开销是比较大的,还会存在一种情况是线程 A 持有线程 B 需要的锁,B 必须一直等待 A 释放锁,即使 A 可能一段时间内因为 B 的优先级比较高而得不到时间片运行。所以在高性能的应用中我们常常希望规避锁的使用。
public class NativeSynchronousQueue<E> {
boolean putting = false;
E item = null;
public synchronized E take() throws InterruptedException {
while (item == null)
wait();
E e = item;
item = null;
notifyAll();
return e;
}
public synchronized void put(E e) throws InterruptedException {
if (e==null) return;
while (putting)
wait();
putting = true;
item = e;
notifyAll();
while (item!=null)
wait();
putting = false;
notifyAll();
}
}
1.2 信号量实现
经典同步队列实现采用了三个信号量,代码很简单,比较容易理解:
public class SemaphoreSynchronousQueue<E> {
E item = null;
Semaphore sync = new Semaphore(0);
Semaphore send = new Semaphore(1);
Semaphore recv = new Semaphore(0);
public E take() throws InterruptedException {
recv.acquire();
E x = item;
sync.release();
send.release();
return x;
}
public void put (E x) throws InterruptedException{
send.acquire();
item = x;
recv.release();
sync.acquire();
}
}
2. SQ 源码分析
SQ 为等待过程中的生产者或消费者线程提供可选的公平策略(默认非公平模式)。非公平模式通过栈(LIFO)实现,公平模式通过队列(FIFO)实现。使用的数据结构是双重队列(Dual queue)和双重栈(Dual stack)。FIFO 通常用于支持更高的吞吐量,LIFO 则支持更高的线程局部存储(TLS)。
// 生产者
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
if (transferer.transfer(e, false, 0) == null) {
Thread.interrupted();
throw new InterruptedException();
}
}
// 消费者
public E take() throws InterruptedException {
E e = transferer.transfer(null, false, 0);
if (e != null)
return e;
Thread.interrupted();
throw new InterruptedException();
}
put 和 take 都是直接委托 transferer 完成的。本节以公平式 TransferQueue 为例分析 JDK8 的实现原理。
2.1 TransferQueue 数据结构
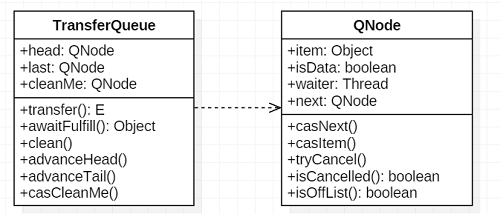
以上是 TransferQueue 的大致结构,可以看到 TransferQueue 是一个普通的队列,同时存在一个指向队列头部的指针 head,和一个指向队列尾部的指针 tail;cleanMe 的存在主要是解决不可清楚队列的尾节点的问题;队列的节点通过内部类 QNode 封装,QNode 是一个单链表结构,包含四个变量:
static final class QNode {
volatile Object item; // 节点包含的数据,非空表示生产者,空者是消费者
final boolean isData; // 表示该节点由生产者创建还是由消费者创建,生产者true,消费者false
volatile Thread waiter; // 等待在该节点上的线程。to control park/unpark
volatile QNode next; // 指向队列中的下一个节点
}
2.2 SQ 阻塞算法
SQ 的阻塞算法可以归结为以下几点:
(1) 双重队列
和典型的单向链表结构不同,SQ 使用了双重队列(Dual queue)和双重栈(Dual stack)存储数据,队列中的每个节点都可以是一个生产者或是消费者。
在消费者获取元素时,如果队列为空,当前消费者就会作为一个“元素为null”的节点被放入队列中等待,所以 QNode 中 的节点存储了生产者节点(item!=null & isData=true)和消费者节点(item=null & isData=false),这两种节点就是通过 isData 来区分的。但同一时间链表中要么全是生产者,要么全是消费者。
(2) 节点匹配
节点命中后修改 item 的状态,已取消节点引用指向自身,避免垃圾保留和内存损耗。通过自旋和 LockSupport 的 park/unpark 实现阻塞,在高争用环境下,自旋可以显著提高吞吐量。
- 当队列中已经有生产者(item!=null & isData=true)线程时,如果有一个消费者过来,这里会让队列中的生产者节点出队,并修改节点状态为 (item=null & next=this & isData=true)
- 当队列中已经有消费者(item=null & isData=false)线程时,如果有一个生产者过来,这里会让队列中的消费者节点出队,并修改节点状态为 (item!=null & next=this & isData=false)
- 如果队列中的节点取消或超时了,修改节点的状态为 item=this
如果全是生产者线程,当消费者线程调用 take 时会匹配链表中的元素,将第一个生产者线程节点 node 出队,也就是 transfer 的过程。数据从一个线程 transfer 到另一个线程,同时修改该节点 node 的状态。如果全是消费者线程亦然。
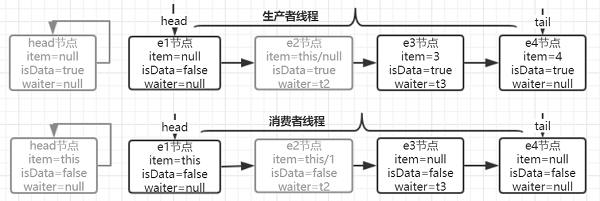
以生产者线程入队为例:
- 默认 head=tail 都指向同一个空节点。head 节点永远都是一个哨兵节点,真正的数据节点是从下一个节点开始。tail 节点永远指向真正的尾节点。
- 当队列为空或队列中全部是生产者线程时,即无法立即匹配时,节点入到队尾。入到队列后,不会立刻将该线程挂起,线程会自旋一定的次数后,始终无消费者线程过来,则挂起线程。
- 当生产者线程过来后,发现队列中生产者线程在等待,则消费者线程直接和队列中的头节点进行匹配,将 head.next.item 置为 null。
这时生产者线程如果是在自旋,则会发现 item 已属性改变,直接退出自旋,继续执行。
如果生产者线程已经被挂起,则消费者线程会唤醒该生产者线程。
下面主要分析 TransferQueue 的三个重要方法:transfer、awaitFulfill、clean。这三个方法是 TransferQueue 的核心,入口是 transfer(),下面具体看代码。
2.3 transfer
// 生产者e!=null,消费者e=null。timed=true表示超时等待,否则无限等待
E transfer(E e, boolean timed, long nanos) {
QNode s = null; // constructed/reused as needed
boolean isData = (e != null);
for (;;) {
QNode t = tail;
QNode h = head;
if (t == null || h == null) // saw uninitialized value
continue; // spin
// 1.1 h==t 表示还没有节点入队
// 1.2 isData==isData 表示该队列中的等待的线程与当前线程是相同模式
// (同为生产者,或者同为消费者,队列中只存在一种模式的线程)
// 总之只有生产者或只有消费者时,需要将该线程插入到队列中进行等待
if (h == t || t.isData == isData) { // empty or same-mode
QNode tn = t.next;
if (t != tail) // 其它线程修改了尾节点,continue
continue;
if (tn != null) { // 其它线程有节点入队,帮助其它线程修改尾节点 tail
advanceTail(t, tn);
continue;
}
if (timed && nanos <= 0) // can't wait
return null;
if (s == null) // 仅初始化一次s,通过区分isData生产者和消费者
s = new QNode(e, isData);
// 2. 最重要的一步,上面判断了这么多数据不一致的情况,最终完成节点入队,失败重试。
// 其实上面两个 continue 不执行也没有关系,大不了在这一步失败后重试
// t 如果不是尾节点 next 肯定不为空。要么指定自己(失效),要么指向下一个节点。
if (!t.casNext(null, s)) // failed to link in
continue;
// 执行失败没有关系,会有其他线程帮忙执行完成的 ok
advanceTail(t, s); // swing tail and wait
// 3. 等待其它线程匹配。二种情况:一是匹配完成,返回数据;二是等待超时/取消,返回原节点s
Object x = awaitFulfill(s, e, timed, nanos);
// 3.1 等待超时/取消,返回原节点s
if (x == s) { // wait was cancelled
clean(t, s);
return null;
}
// 3.2 匹配成功了,但是还需要将该节点从队列中移除
if (!s.isOffList()) { // not already unlinked
advanceHead(t, s); // unlink if head
if (x != null) // and forget fields
s.item = s;
s.waiter = null;
}
return (x != null) ? (E)x : e;
// 4. 如果队列已有线程在等待,直接进行匹配即可
} else { // complementary-mode
// 进行匹配,从队列的头部开始,即head.next
QNode m = h.next; // node to fulfill
if (t != tail || m == null || h != head)
continue; // inconsistent read
// 5.1 前面已经说过匹配成功会修改 item,并发时可能头节点已经匹配过了
// isData == (x != null) 相等则说明 m 已经匹配过了,因为正常情况是不相等才对
// 5.2 x==m 说明 m 被取消了,见 QNode#tryCancel()
// 5.3 CAS失败说明 m 已经被其他线程匹配了,所以将其出队,然后 retry
// CAS设置m.item为e,这里的e,如果是生产者则是数据,消费者则是null,
// 所以m如果是生产者,则item变为null,消费者则变为生产者的数据
Object x = m.item;
if (isData == (x != null) || // m already fulfilled
x == m || // m cancelled
!m.casItem(x, e)) { // lost CAS
advanceHead(h, m); // dequeue and retry
continue;
}
// 6. 与m匹配成功,将m出队,并唤醒等待在m上的线程m.waiter
// 同上,失败则说明有其它线程修改了头节点 ok
advanceHead(h, m); // successfully fulfilled
LockSupport.unpark(m.waiter);
return (x != null) ? (E)x : e;
}
}
}
从上面的代码可以看出 TransferQueue.transfer() 的整体流程:
- 判断当前队列是否为空或者队尾节点(头节点可能被修改)线程是否与当前线程匹配,队列为空或者不匹配都将进行入队操作
- 入队分成两步:修改 tail.next 为新节点,同时修改 tail 为新节点,这两步操作有可能分在两个不同的线程执行,不过不影响执行结果
- 入队之后需要将当前线程阻塞,调用 LockSupport.park() 方法,直到打断/超时/被匹配的线程唤醒。如果 ①打断/超时,返回节点本身;②匹配成功,返回队列中节点的数据,如果是队列中是生产者线程则返回数据本身,否则返回 null
- 如果被取消,则需要调用 clean() 方法进行清除
- 由于 FIFO,所以匹配总是发生在队列的头部,修改节点的 item 属性传递数据,同时唤醒等待在节点上的线程
// advanceHead 更新头节点并将失效的头节点踢出队列(h.next = h)
void advanceHead(QNode h, QNode nh) {
if (h == head &&
UNSAFE.compareAndSwapObject(this, headOffset, h, nh))
h.next = h; // forget old next
}
2.4 等待匹配 awaitFulfill
/**
* 等待匹配,该方法会进入阻塞,直到三种情况下才返回:
* a. 超时被取消了,返回值为 s
* b. 匹配上了,返回另一个线程传过来的值
* c. 线程被打断,会取消,返回值为 s
*/
Object awaitFulfill(QNode s, E e, boolean timed, long nanos) {
/* Same idea as TransferStack.awaitFulfill */
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Thread w = Thread.currentThread();
// 1. 自旋锁次数,如果不是队列的第一个元素则不自旋,因为压根轮不上他,自旋只是浪费 CPU
// 如果等待的话则自旋的次数少些,不等待就多些
int spins = ((head.next == s) ?
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
for (;;) {
// 2. 支持打断
if (w.isInterrupted())
s.tryCancel(e);
// 3. 如果s的item不等于e,有以下二种情况,不管是哪种情况都不要再等待了,返回即可
// a. 超时或线程被打断了,此时x==s
// b. 匹配上了,此时x==另一个线程传过来的值
Object x = s.item;
if (x != e)
return x;
if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
s.tryCancel(e);
continue;
}
}
if (spins > 0) // 自旋,直到spins==0,进入等待
--spins;
else if (s.waiter == null)
s.waiter = w; // 设置等待线程才能被唤醒
else if (!timed)
LockSupport.park(this);
else if (nanos > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanos);
}
}
awaitFulfill() 主要涉及自旋以及 LockSupport.park() 两个关键点,自旋可去了解自旋锁的原理。
自旋锁原理:通过空循环则霸占着 CPU,避免当前线程进入睡眠,因为睡眠/唤醒是需要进行线程上下文切换的,所以如果线程睡眠的时间很段,那么使用空循环能够避免线程进入睡眠的耗时,从而快速响应。但是由于空循环会浪费 CPU,所以也不能一直循环。自旋锁一般适合同步快很小,竞争不是很激烈的场景。
java 中大量运用了这样的技术。凡是有阻塞的操作都会这样做,包括内置锁在内,内置锁其实也是这样的,内置锁分为偏向锁,轻量级锁和重量级锁,其中轻量级锁其实就是自旋来替代阻塞。
当然需要自旋多长时间。这是一个根据不同情况来设定的值并没有一个准确的结论,通常来说竞争越激烈这样多自旋一段时间总是好的,效果也越明显,但是自旋时间过长会浪费 cpu 时间所以,设定时间还是一个很依靠经验的值。
在这里其实是这样做的,首先看一下当前 cpu 的数量,NCPUS 然后分两种情况一种是设定了时间限的自旋时间。如果设定了时间限则使用 maxTimedSpins,如果 NCPUS 数量大于等于 2 则设定为为 32 否则为 0,既一个 CPU 时不自旋;这是显然了,因为唯一的 cpu 在自旋显然不能进行其他操作来满足条件。 如果没有设定时间限则使用 maxUntimedSpins,如果 NCPUS 数量大于等于 2 则设定为为 32 * 16,否则为 0;
另外还有一个参数 spinForTimeoutThreshold 这个参数是为了防止自定义的时间限过长,而设置的,如果设置的时间限长于这个值则取这个 spinForTimeoutThreshold 为时间限。这是为了优化而考虑的。这个的单位为纳秒。
2.5 节点清除 clean
大概总结一下 clean 方法在做什么?。
首先,这里的队列其实是单向链表。所以只能设置后继的节点而不能设置前向的节点,这会产生一个问题,就是加入队列尾的节点失效了要删除怎么办?我们没办法引用队列尾部倒数第二个节点。所以这里采用了一个方法就是讲当前的尾结点保存问 cleanMe 节点,这样在下次再次清除的时候通常 cleanMe 通常就不是尾结点了,这样就可以删除了。也就是每次调用的时候删除的其实是上次需要结束的节点。更多关于清除节点 clean
参考:
- 《JUC源码分析-集合篇(八):SynchronousQueue》:https://www.jianshu.com/p/c4855acb57ec
- 《源码分析-SynchronousQueue》:https://blog.csdn.net/u011518120/article/details/53906484
每天用心记录一点点。内容也许不重要,但习惯很重要!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号