
字符串匹配算法之——KMP算法
字符串匹配在日常开发中很常用,用于判断一个字符串中是否包含另外一个字符串,例如Java中的indexOf方法,查到则返回对应的位置,未查询到则返回-1。
如图-1,在“abcabd”中查找“abd”,最终在下标3的位置匹配。
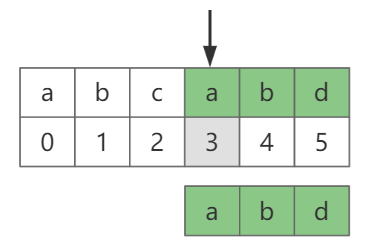
图-1
至于是如何匹配的,直觉上认为就是挨个匹配,应该没有什么难度。我们就看下这种挨个匹配的算法,看看是否存在提升空间。
我们先介绍一种简单的BF算法,即暴力算法(Brute Force),也称为经典的、朴素的算法。这其实就是刚才提到的挨个匹配,思路就是挨个比较。例如从“abcad”中查询“abd”是否存在,流程如图-2
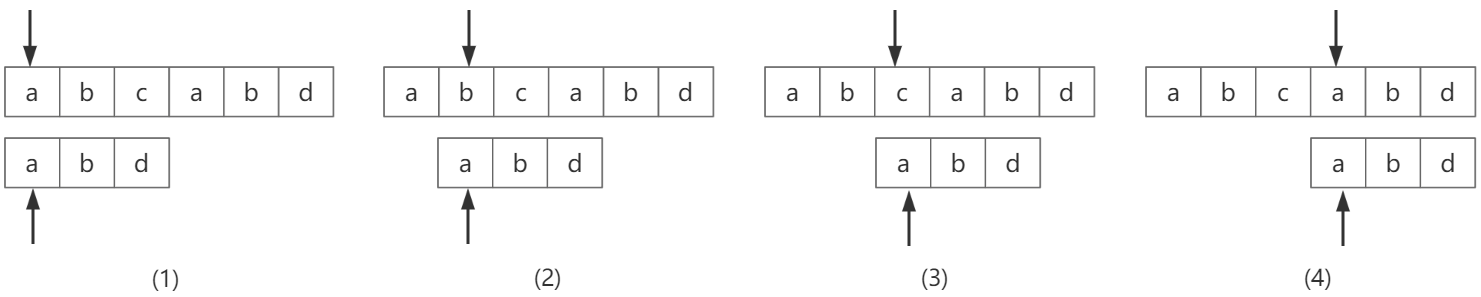
图-2
代码
1 public class StringSearch { 2 public static void main(String[] args) { 3 String a = "abcabd"; 4 String b = "abd"; 5 System.out.println(bf(a, b)); 6 } 7 8 private static int bf(String a, String b) { 9 //记录查找子串的位置 10 int bIndex = 0; 11 //从开头循环处理主串的每一个字符 12 for (int aIndex = 0; aIndex < a.length(); aIndex++) { 13 System.out.printf("aIndex=%d bIndex=%d %s %s\n", aIndex, bIndex, a.charAt(aIndex), b.charAt(bIndex)); 14 if (a.charAt(aIndex) == b.charAt(bIndex)) { 15 //记录匹配长度,和查找字符串相等说明完全匹配,即可退出 16 bIndex++; 17 if (bIndex == b.length()) { 18 return aIndex - b.length() + 1; 19 } 20 } else { 21 //部分匹配的子串时,主串回到此轮匹配的下一个位置,子串也需要从头开始 22 if (bIndex != 0) { 23 aIndex = aIndex - bIndex; 24 bIndex = 0; 25 System.out.printf("\treset index aIndex=%s bIndex=%d\n", aIndex, bIndex); 26 } 27 } 28 } 29 return -1; 30 } 31 }
输出
aIndex=0 bIndex=0 a a aIndex=1 bIndex=1 b b aIndex=2 bIndex=2 c d reset index aIndex=0 bIndex=0 #这里由于c!=d,导致主串需要从aIndex=1的位置重新匹配整个子串 aIndex=1 bIndex=0 b a aIndex=2 bIndex=0 c a aIndex=3 bIndex=0 a a aIndex=4 bIndex=1 b b aIndex=5 bIndex=2 d d 3
可以看出逻辑很简单,只要在主串中查询不到,就从开始位置的下一个位置重新开始匹配,同时子串的开始匹配位置也置为0。
如果是在我们日常开发中,一般不会用很长的字符串去查找,这种算法完全够用。
但是,我们再分析下是否还有改进的空间,再观察下步骤(1)
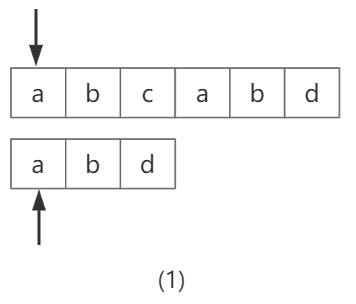
图-3
从要查找的字符串“abd”中能看到 a!=b,当匹配到第二个位置b=b时,此位置的b必然不等于a。因此在第二轮开始后,主串“abcabd”第二个位置的b就无需再判断了,可以直接跳过,如图-4
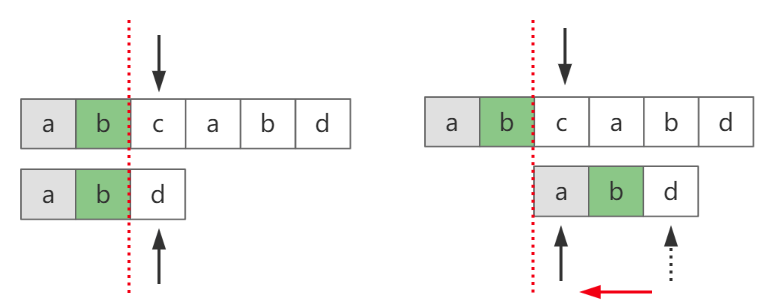
图-4
主串位置继续留在未匹配的位置c上,只需要把子串d的位置直接跳到开头a位置。
但是在BF算法中,并没有利用这个b必然不等于a的信息,第二轮又返回到了b的位置,并且继续和子串的a进行对比。这里其实就是可优化的空间,核心就是检测并保留这些不等的信息。
如何做到呢?上述的例子是提前知道了匹配的子串“abd”中a不等于b,且a、b、d都不同。那问题就转换为如何知道这些不等的关系,又如何保证匹配的字符不同?
不等的关系可以通过预处理来解决,但是重复字符怎么办呢?强制要求字符都不同必然不现实。
那我们能不能让有重复字符的子串也支持这种跳过的模式呢?或者换种思路,让有重复的字符能跳到字符重复出现的地方,是不是也可以呢?
我们先看一些有重复字符串的例子,第二列为字符对应的下标。
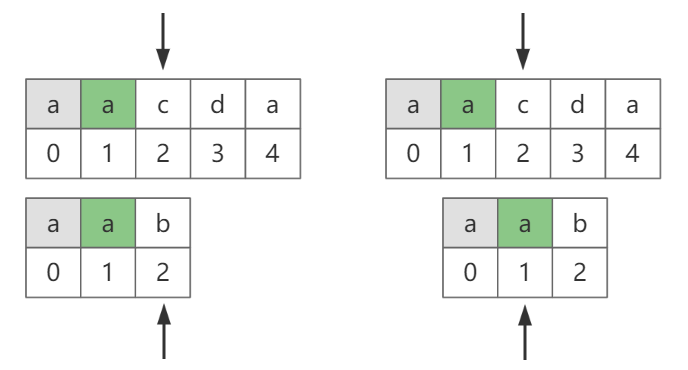
图-5
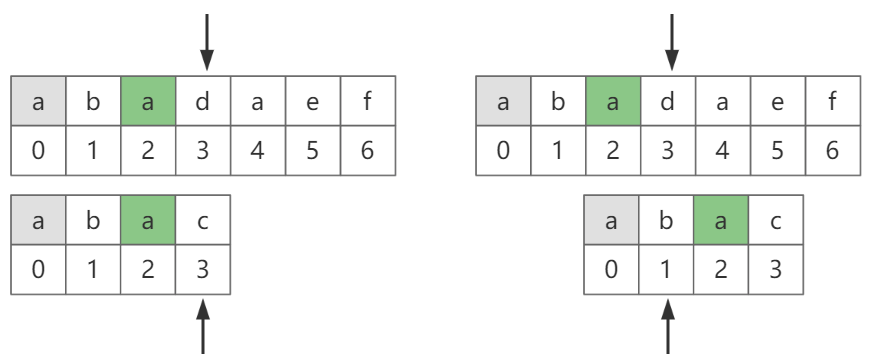
图-6
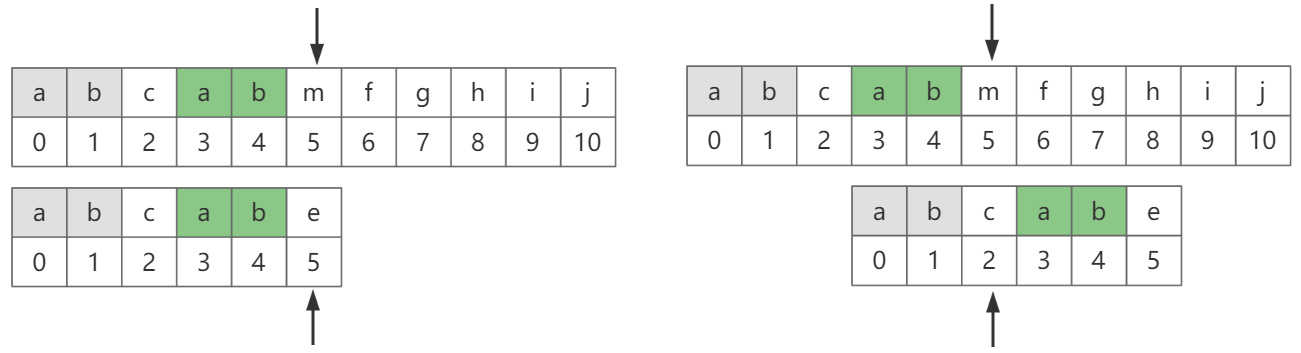
图-7
可以看到,即使出现重复字符,在下次匹配时仍可以保持主串当前位置不变,在子串中跳过一些字符。
可能到这里还是有些不明白,我们再看下图-7的例子“abcabe”子串,之所以能跳过ab这两个字符,是因为ab同时出现在了下标为0 1 和 3 4的位置。
而在主串“abcabmfghij”中,由于已经匹配到下标5(m)这个位置,必然说明之前的字符都是相同的(否则也不会匹配到这个位置),因此下标5之前的两个字符必然是ab,而这个ab又是子串开头位置,因此就没必要再次比较了(这个逻辑很重要,务必理解),如图-8所示
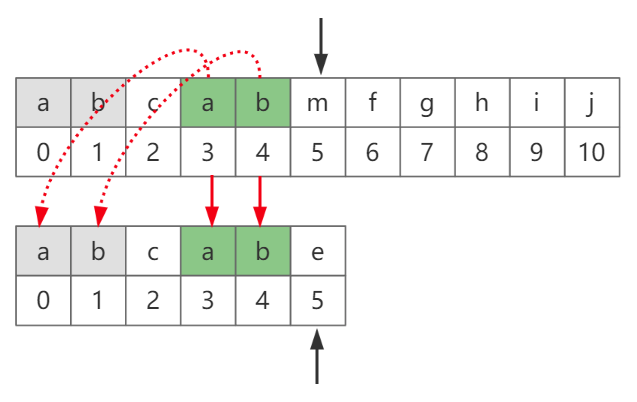
图-8
所以,现在的核心问题就是如何找出子串中各字符对应的跳过长度,才能确定不匹配时对应的跳转位置。
可以先想一下。
我们先介绍几个必要的概念。
前缀(prefix),是一个字符串中从开头位置往后,由一些连续字符构成的子串。
如“abcde”中,前缀有a、ab、abc、abcd、abcde,其中真前缀(proper prefix,为了方便后续都称为前缀)是指不包括最后一个字符的前缀(即不能是字符串本身)。
后缀(suffix),是包括最后一个字符,由连续字符串构成的子串,如上述例子的e、de、cde、bcde、abcde,对应的真后缀(proper suffix,后续统一称为后缀)就是不包含开头字符的后缀(即不能是字符串本身)。
我们把即是前缀又是后缀,且长度最长的前后缀称为LPS (longest proper prefix that is also a suffix,最长公共前后缀?先这么翻译吧,明白意思就行)。
例如上述字符串“abcab”前后缀如下
前缀:a、ab、abc、abca
后缀:b、ab、cab、bcab
因此字符串“abcab”最长的公共前后缀就是ab,长度为2。
此时,是不是看出些眉目了?其实这个LPS就是我们需要求解的,同时解决了重复和不重复的字符问题,有了它就能知道要跳过的长度了。
这时就可以引出由Donald Knuth、Vaughan Pratt和James H. Morris提出的KMP(Knuth–Morris–Pratt algorithm)算法了,此算法正是根据这种思路编写的,具体代码如下
1 public class Kmp { 2 public static void main(String[] args) { 3 String a = "abcabanababc"; 4 String b = "ababc"; 5 int[] next = next(b); 6 print(b, next); 7 System.out.println(kmp(a, b, next)); 8 } 9 10 public static int kmp(String a, String b, int[] next) { 11 int bIndex = 0; 12 for (int aIndex = 0; aIndex < a.length(); aIndex++) { 13 System.out.printf("aIndex=%d bIndex=%d %s %s\n", aIndex, bIndex, a.charAt(aIndex), b.charAt(bIndex)); 14 if (a.charAt(aIndex) == b.charAt(bIndex)) { 15 bIndex++; 16 if (bIndex == b.length()) { 17 return aIndex - b.length() + 1; 18 } 19 } else { 20 if (bIndex != 0) { 21 //aIndex默认减一(for循环中会自动加一,相当于保持位置不动)需要重新比对bIndex对应的字符 22 aIndex--; 23 //bIndex取next中的位置 24 bIndex = next[bIndex]; 25 System.out.printf("\treset index aIndex=%s bIndex=%d\n", aIndex, bIndex); 26 } 27 } 28 } 29 return -1; 30 } 31 32 public static int[] next(String t) { 33 int j = 0; 34 int k = -1; 35 int[] next = new int[t.length() + 1]; 36 next[0] = -1; 37 while (j < t.length()) { 38 System.out.printf("k=%d j=%d\n", k, j); 39 if (k == -1 || t.charAt(k) == t.charAt(j)) { 40 System.out.printf("\tk=%d next[j+1]=next[%d+1]=k+1=%d+1=%d\n", k, j, k, k + 1); 41 next[j + 1] = k + 1; 42 j++; 43 k++; 44 } else { 45 System.out.printf("\t%s!=%s set k=next[k]=next[%d]=%d\n", t.charAt(k), t.charAt(j), k, next[k]); 46 k = next[k]; 47 } 48 } 49 return next; 50 } 51 52 private static void print(String b, int[] next) { 53 System.out.println("[PMT]"); 54 for (int i = 0; i < next.length; i++) { 55 System.out.printf("%2d ", i); 56 } 57 System.out.println(); 58 for (int i = 0; i < b.length(); i++) { 59 System.out.printf("%2s ", b.charAt(i)); 60 } 61 System.out.println(); 62 for (int e : next) { 63 System.out.printf("%2d ", e); 64 } 65 System.out.println(); 66 } 67 }
输出
k=-1 j=0 k=-1 next[j+1]=next[0+1]=k+1=-1+1=0 k=0 j=1 a!=b set k=next[k]=next[0]=-1 k=-1 j=1 k=-1 next[j+1]=next[1+1]=k+1=-1+1=0 k=0 j=2 k=0 next[j+1]=next[2+1]=k+1=0+1=1 k=1 j=3 k=1 next[j+1]=next[3+1]=k+1=1+1=2 k=2 j=4 a!=c set k=next[k]=next[2]=0 k=0 j=4 a!=c set k=next[k]=next[0]=-1 k=-1 j=4 k=-1 next[j+1]=next[4+1]=k+1=-1+1=0 [PMT] 0 1 2 3 4 5 a b a b c -1 0 0 1 2 0 aIndex=0 bIndex=0 a a aIndex=1 bIndex=1 b b aIndex=2 bIndex=2 c a reset index aIndex=1 bIndex=0 aIndex=2 bIndex=0 c a aIndex=3 bIndex=0 a a aIndex=4 bIndex=1 b b aIndex=5 bIndex=2 a a aIndex=6 bIndex=3 n b reset index aIndex=5 bIndex=1 aIndex=6 bIndex=1 n b reset index aIndex=5 bIndex=0 aIndex=6 bIndex=0 n a aIndex=7 bIndex=0 a a aIndex=8 bIndex=1 b b aIndex=9 bIndex=2 a a aIndex=10 bIndex=3 b b aIndex=11 bIndex=4 c c 7
从代码中可以看到,匹配流程和BF算法基本一致,不同的就是发生不匹配时,bIndex的位置是从next数组中获得的。next数组叫做部分匹配表,或者PMT(Partial Match Table),里面存储的正是每个字符对应的LPS的长度(由于不匹配可能发生在子串中的任何一个位置,因此需要求任意一个字符的左侧字符串的LPS)。
我们重点看下next方法中对PMT的计算流程。
乍一看可能不太好理解,特别是这个k = next[k],因为从LPS特性上出发,我们自然想到的是通过枚举出每个字符对应的所有前后缀,然后选取一个最长的做为跳过长度,这种虽然能解决问题,但效率不高。
其实我们可以从公共前后缀的特点出发,而问题本身又是一个求最值的问题,可以考虑能否通过动态规划的方式来实现。
我们先看下是否存在子问题,我们要求解每个字符左侧部分的公共前后缀,处理到该位置,前面的字符串已经固定下来了,决定了的该字符对应的结果是不变的,
例如“abcab”中第三个字符c的左侧字符为“ab”,处理后续字符并不会改变这个“ab”。
我们再看下是否存在“重叠的子问题”,我们以“abcabc”为例,当处理到最后的字符c时,c之前的LPS为“ab”且前缀ab的后一个字符又是c,等于最后的字符c,因此LPS为“abc”,可见还是能用得上之前的最值的。
但如果不等呢,例如换成“abcabd”,也就是c!=d,这时应该如何处理?是不是应该取导致c这个位置的LPS长度对应的字符呢?
我们换个角度理解这个LPS长度,其实就是和当前字符相等的字符的位置,正是因为字符相等才导致LPS长度增加。
也就是这个位置对应的字符和比较的字符相等说明可以和该字符组成更长的前后缀,即当前的位置+1就是LPS长度,如果不等则仍需要根据回溯的字符所处的位置再回溯,直到第一个字符为止。
这么说可能有点绕,看图-9,为了方便演示我们换一下子串为“abcabcffabca”。
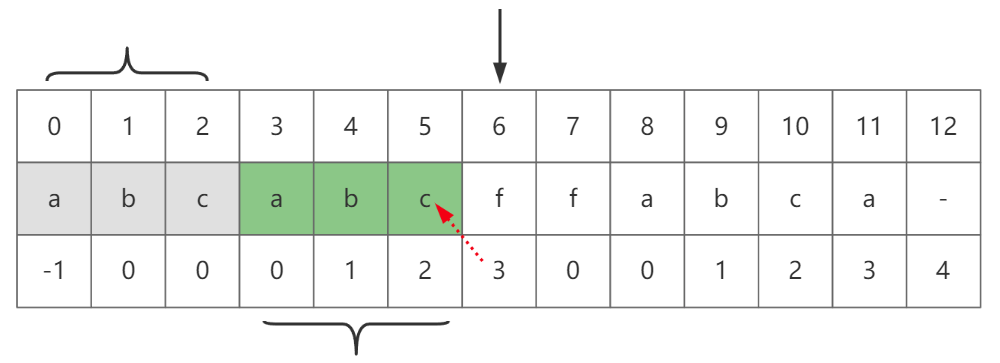
图-9
第一行为字符的下标,第三行为对应的LPS长度。可以看到下标6的字符“f”的LPS长度为3,说明f之前有三个字符构成了最长公共前后缀,即“abc”,我们刚才提到了这个3也是和当前字符相等的字符的位置(即字符下标的位置),但是下标3对应的是字符“a”,不等于“f”,因此需要再次根据下标3对应的LPS长度0,回溯到下标0对应的LPS长度为-1处,而-1表示都未查询到相同字符,因此最终下标7位置对应的LPS长度为-1+1=0,注意下标位置存储的LPS长度是前一个字符的。实际使用中并不会匹配到最后一个字符,可以想想为什么。
你可以尝试分析一下图-10下标10的LPS长度为何是3。
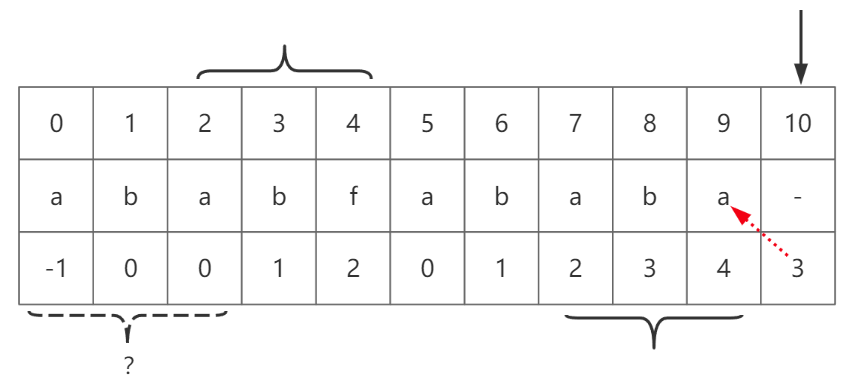
图-10
还是不明白?其实核心就是前后缀相同这个特性,前缀一定是从字符串最左侧开始出现的,后缀也必然要从字符串最左侧开始才能相同,可以结合图-11思考下。

图-11
参考资料

 浙公网安备 33010602011771号
浙公网安备 33010602011771号