
google论文:GFS
1. 导论
先给个定义:GFS是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。它运行于廉价的普通硬件上,但可以提供容错功能。它可以给大量的用户提供总体性能较高的服务。

Google File System. Designed for system-to-system interaction, and not for user-to-system interaction. The chunk servers replicate the data automatically.
Assumptions in Google File System (GFS)
- GFS should be built with commodity hardware
- Inexpensive disks and machines
- GSF stores a modest number of large files
- GSF stores a modest number of large files
- e.g. Big-table, Map-Reduce records
- Do not optimize for small files
- GSF stores a modest number of large files
- Workloads
- Large streaming reads (1MB or more) and small random reads (a few KBs)
- Sequential appends to files by hundreds of data producers
- Utilizing the fact that files are seldom modified again
- High sustained bandwidth is more important than latency
- Response time for individual read and write is not critical
Prerequisite
- 组件失效被认为是常态事件,而不是意外事件。
- 以通常的标准衡量,我们的文件非常巨大。
- 绝大部分文件的修改是采用在文件尾部追加数据,而不是覆盖原有数据的方式。
- 应用程序和文件系统API的协同设计提高了整个系统的灵活性。e.g.
- 放松了在GFS一致性模型的要求
- 引入了原子性的记录追加操作
- 三个冗余的数据可以不是位一致,但是要求校验和验证
- 系统的工作负载
- 读操作
- 大规模的流式读取
- 小规模的随机读取
- 写操作
- 许多大规模的、顺序的、数据追加方式的写操作
- 读操作
- 系统必须高效的、行为定义明确的实现多客户端并行追加数据到同一个文件里
- 使用最小的同步开销来实现的原子的多路追加数据操作是必不可少的
- 文件可以在稍后读取,或者是消费者在追加的操作的同时读取文件
- 高性能的稳定网络带宽远比低延迟重要
- 高速率的、大批量的处理数据
- 极少有程序对单一的读写操作有严格的响应时间要求
2. 架构

- Files are divided into chunks
- Fixed-size chunks (64MB)
- Replicated over chunkservers, called replicas
- Unique 64-bit chunk handles
-
Chunks as Linux files
-
Single master
- Multiple chunkservers
- Grouped into Racks
- Connected through switches
- Multiple clients
- Master/chunkserver coordination
- HeartBeat messages
注意逻辑的Master节点和物理的Master服务器的区别
Master节点
Master节点管理所有的文件系统元数据。这些元数据包括名字空间、访问控制信息、文件和Chunk的映射信息、以及当前Chunk的位置信息。Master节点还管理着系统范围内的活动,比如,Chunk租用管理、失效Chunk的回收、以及Chunk在Chunk服务器之间的迁移。
单一的Master节点可以通过全局的信息精确定位Chunk的位置以及进行复制决策。另外,我们必须减少对Master节点的读写,避免Master节点成为系统的瓶颈。客户端并不通过Master节点读写文件数据。反之,客户端向Master节点询问它应该联系的Chunk服务器。客户端将这些元数据信息缓存一段时间,后续的操作将直接和Chunk服务器进行数据读写操作。
Master服务器
Master服务器存储3种主要类型的元数据,包括:文件和Chunk的命名空间、文件和Chunk的对应关系、每个Chunk副本的存放地点。所有的元数据都保存在Master服务器的内存中。前两种类型的元数据(命名空间、文件和Chunk的对应关系)同时也会以记录变更日志的方式记录在操作系统的系统日志文件中,日志文件存储在本地磁盘上,同时日志会被复制到其它的远程Master服务器上。采用保存变更日志的方式,我们能够简单可靠的更新Master服务器的状态,并且不用担心Master服务器崩溃导致数据不一致的风险。Master服务器不会持久保存Chunk位置信息。Master服务器在启动时,或者有新的Chunk服务器加入时,向各个Chunk服务器轮询它们所存储的Chunk的信息。
Master服务器并不保存持久化保存哪个Chunk服务器存有指定Chunk的副本的信息。Master服务器只是在启动的时候轮询Chunk服务器以获取这些信息。Master服务器能够保证它持有的信息始终是最新的,因为它控制了所有的Chunk位置的分配,而且通过周期性的心跳信息监控Chunk服务器的状态。
- 简化了在有Chunk服务器加入集群、离开集群、更名、失效、以及重启的时候,Master服务器和Chunk服务器数据同步的问题。
- 只有Chunk服务器才能最终确定一个Chunk是否在它的硬盘上。Master服务器无需维护一个这些信息的全局视图
操作日志
操作日志包含了关键的元数据变更历史记录。这对GFS非常重要。这不仅仅是因为操作日志是元数据唯一的持久化存储记录,它也作为判断同步操作顺序的逻辑时间基线。文件和Chunk,连同它们的版本,都由它们创建的逻辑时间唯一的、永久的标识。
必须确保日志文件的完整,确保只有在元数据的变化被持久化后,日志才对客户端是可见的。把日志复制到多台远程机器,并且只有把相应的日志记录写入到本地以及远程机器的硬盘后,才会响应客户端的操作请求。
为了缩短Master启动的时间,我们必须使日志足够小。Master服务器在日志增长到一定量时对系统状态做一次Checkpoint,将所有的状态数据写入一个Checkpoint文件。在灾难恢复的时候,Master服务器就通过从磁盘上读取这个Checkpoint文件,以及重演Checkpoint之后的有限个日志文件就能够恢复系统。
由于创建一个Checkpoint文件需要一定的时间,所以Master服务器的内部状态被组织为一种格式,这种格式要确保在Checkpoint过程中不会阻塞正在进行的修改操作。
一致性模型
- Relaxed consistency model
-
Two types of mutations
- Writes
- Cause data to be written at an application-specified file offset
- Record appends
- Operations that append data to a file
- Cause data to be appended atomically at least once
- Offset chosen by GFS, not by the client
- Writes
-
States of a file region after a mutation
- Consistent
- All clients see the same data, regardless which replicas they read from
- Defined
- consistent + all clients see what the mutation writes in its entirety
- Undefined
- consistent +but it may not reflect what any one mutation has written
- Inconsistent
- Clients see different data at different times
- The client retries the operation
- Consistent
经过了一系列的成功的修改操作之后,GFS确保被修改的文件region是已定义的,并且包含最后一次修改操作写入的数据。GFS通过以下措施确保上述行为:(a) 对Chunk的所有副本的修改操作顺序一致,(b)使用Chunk的版本号来检测副本是否因为它所在的Chunk服务器宕机而错过了修改操作而导致其失效。失效的副本不会再进行任何修改操作,Master服务器也不再返回这个Chunk副本的位置信息给客户端。它们会被垃圾收集系统尽快回收。
使用GFS的应用程序可以利用一些简单技术实现这个宽松的一致性模型,这些技术也用来实现一些其它的目标功能,包括:
- 尽量采用追加写入而不是覆盖
- Checkpoint
- to verify how much data has been successfully written
- 自验证的写入操作
- Checksums to detect and remove padding
- 自标识的记录。
- Unique Identifiers to identify and discard duplicates
3. 系统交互
- Master uses leases to maintain a consistent mutation order among replicas
- Primary is the chunkserver who is granted a chunk lease
- All others containing replicas are secondaries
- Primary defines a mutation order between mutations
-
All secondaries follows this order
-
数据流和控制流分开
- 数据以管道的方式,顺序的沿着一个精心选择的Chunk服务器链推送
- Data transfer is pipelined over TCP connections
- Each machine forwards the data to the “closest” machine
- 全双工的交换网络
- Benefits:Avoid bottle necks and minimize latency
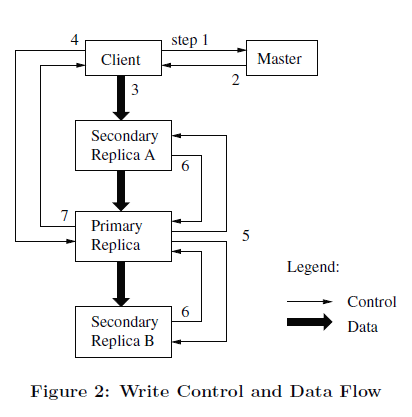
- 客户机向Master节点询问哪一个Chunk服务器持有当前的租约,以及其它副本的位置。如果没有一个Chunk持有租约,Master节点就选择其中一个副本建立一个租约。
- Master节点将主Chunk的标识符以及其它副本(又称为secondary副本、二级副本)的位置返回给客户机。客户机缓存这些数据以便后续的操作。只有在主Chunk不可用,或者主Chunk回复信息表明它已不再持有租约的时候,客户机才需要重新跟Master节点联系。
- 客户机把数据推送到所有的副本上。客户机可以以任意的顺序推送数据。Chunk服务器接收到数据并保存在它的内部LRU缓存中,一直到数据被使用或者过期交换出去。由于数据流的网络传输负载非常高,通过分离数据流和控制流,我们可以基于网络拓扑情况对数据流进行规划,提高系统性能,而不用去理会哪个Chunk服务器保存了主Chunk。
- 当所有的副本都确认接收到了数据,客户机发送写请求到主Chunk服务器。这个请求标识了早前推送到所有副本的数据。主Chunk为接收到的所有操作分配连续的序列号,这些操作可能来自不同的客户机,序列号保证了操作顺序执行。它以序列号的顺序把操作应用到它自己的本地状态中。
- 主Chunk把写请求传递到所有的二级副本。每个二级副本依照主Chunk分配的序列号以相同的顺序执行这些操作。
- 所有的二级副本回复主Chunk,它们已经完成了操作。
- 主Chunk服务器回复客户机。任何副本产生的任何错误都会返回给客户机。在出现错误的情况下,写入操作可能在主Chunk和一些二级副本执行成功。(如果操作在主Chunk上失败了,操作就不会被分配序列号,也不会被传递。)客户端的请求被确认为失败,被修改的region处于不一致的状态。我们的客户机代码通过重复执行失败的操作来处理这样的错误。在从头开始重复执行之前,客户机会先从步骤(3)到步骤(7)做几次尝试。
记录追加的原子性
- The client specifies only the data (not file offset)
- Similar to writes
- Mutation order is determined by the primary
- All secondaries use the same mutation order
- GFS appends data to the file at least once atomically
- The chunk is padded if appending the record exceeds the maximum size --> padding
- If a record append fails at any replica, the client retries the operation --> record duplicates
- File region may be defined but interspersed with inconsistent
快照
- Goals
- To quickly create branch copies of huge data sets
- To easily checkpoint the current state
- Copy-on-write technique
- Metadata for the source file or directory tree is duplicated
- Reference count for chunks are incremented
- Chunks are copied later at the first write
Master Operation
- Namespaces are represented as a lookup table mapping full pathnames to metadata
- Use locks over regions of the namespace to ensure proper serialization
-
Each master operation acquires a set of locks before it runs
-
GFS has no directory (i-node) structure
- Simply uses directory-like file names: /foo, /foo/bar
- Thus listing files in a directory is slow
- Simply uses directory-like file names: /foo, /foo/bar
- Concurrent Access
- Read lock on a parent path, write lock on the leaf file name
- protect delete, rename and snapshot of in-use files
- Read lock on a parent path, write lock on the leaf file name
- Rebalancing
- Places new replicas on chunk servers with below-average disk space utilizations
- Re-replication
- When the number of replicas falls below 3 (or user-specified threshold)
- The master assigns the highest priority to copy (clone) such chunks
- Spread replicas of a chunk across racks
- When the number of replicas falls below 3 (or user-specified threshold)
Example of Locking Mechanism
Preventing /home/user/foo from being created while /home/user is being snapshotted to /save/user
- Snapshot operation
- Read locks on /home and /save
- Write locks on /home/user and /save/user
- File creation
- read locks on /home and /home/user
- write locks on /home/user/foo
- Conflict locks on /home/user
4. 其他细节
垃圾回收
- Deleted files
- Deletion operation is logged
- File is renamed to a hidden name(deferred deletion), then may be removed later or get recovered
- The master regularly scans and removes hidden files, existed more than three days
- HeartBeat messages inform chunk servers of deleted chunks
- Orphaned chunks (unreachable chunks)
- Identified and removed during a regular scan of the chunk namespace
- Stale replicas
- Chunk version numbering
- increases when the master grants a new lease of the chunk
- Chunk version numbering
Replica Operations
- Creation
- Disk space utilization
- Number of recent creations on each chunkserver
- Spread across many racks
- Re-replication
- Prioritized: How far it is from its replication goal…
- The highest priority chunk is cloned first by copying the chunk data directly from an existing replica
- Rebalancing
- Periodically
Fault Tolerance
- Fast Recovery
- The master and the chunk server are designed to restore their state in seconds no matter how they terminated.
- Servers are routinely shut down just by killing the process
- Master Replications
- Master has the maps from file names to chunks
- One (primary) master manages chunk mutations
- Several shadow masters are provided for read-only accesses
- Snoop operation logs and apply these operations exactly as the primary does
- Several shadow masters are provided for read-only accesses
- Data Integrity
- Corruption of stored data
- High temperature of storage devices causes such errors
- Checksums for each 64KB in a chunk
- chunk servers verifies the checksum of data before sending it to the client or other chunk servers
- Corruption of stored data


