
The illustrated Transformer 笔记
The illustrated Transformer
Transformer是一种使用Attention机制类提升模型训练的速度的模型。该模型的最大优势在于其并行性良好。Transformer模型在Attention is All You Need中被提出,代码在Tensor2Tensorpackage中实现,以及一个 guide annotating the paper with PyTorch implementation。
1. A High-Level Look
![]()
![]()
至此为止,整体结构和Seq2Seq一致。不过内部结构有所不同。
Encoder和Decoder都是由多层更小的网络组成:
![]()
Encoder来说,每一个网络结构相同,但是不共享权重,每一个小的Encoder可以分为两层:![]()
Input首先流经Self-Attention层,这个层可以帮助Encoder查看输入序列中的其他单词,之后流经前馈网络。Decoder有着相同的结构,但是多了一个Encoder-Decoder层:
![]()
2. Bringing The Tensors Into The Picture
首先,我们运用Embedding算法将输入转化为vector,并只在最底层进行输入。得到一个vector list,list的长度一般是训练集的最大句子长度。
然后,Embedding输入Encoder层:
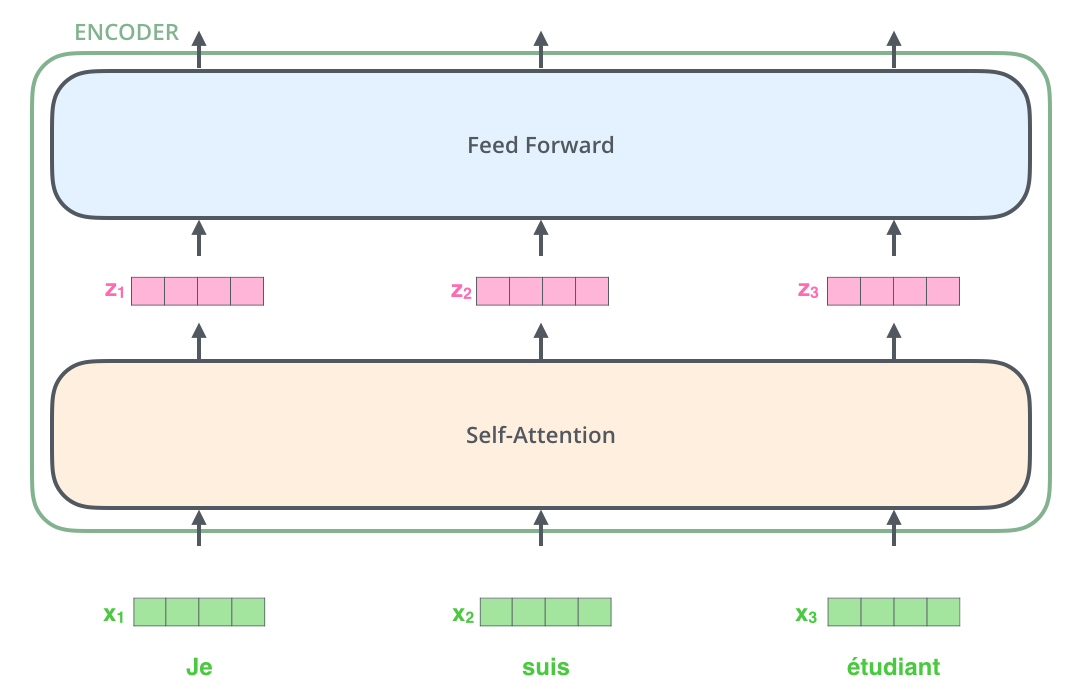
在经过Encoder的过程中,每个单词都会流经它自己的路径。这个路径只在Self-Attention有独立性,但是在前馈网络没有独立性,因此在流经这部分的时候可以进行并行运算。
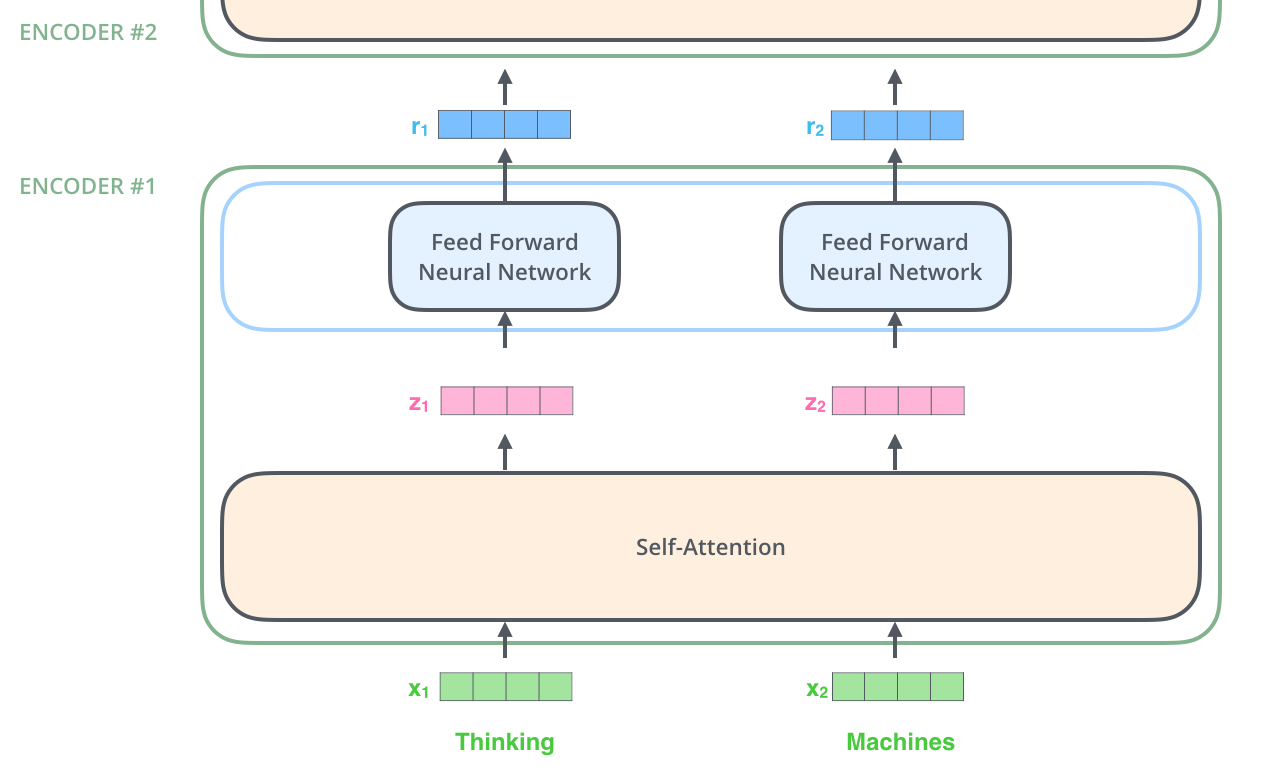
3. Self-Attention at a High Level
假设以下是我们想翻译的句子:"The animal didn't cross the street because it was too tired"
那这个it指代什么呢?如果用Self-Attention处理的话,会得到其指向animal。
在模型处理每一个单词的时候,Self-Attention将去查看输入序列的每一个单词来寻找可以帮助它更好编码这个单词的线索。
Self-Attention是用来将其他相关单词的“理解”加入到我们当前正在处理的单词中的方法。
4. Self-Attention in Detail
接下来是计算方法,以及如何通过矩阵进行运算。
首先是输入Embedding,对于每一个输入,创建Query向量、Key向量、Value向量;通过将Embedding乘以我们在训练过程中训练的三个矩阵来创建这些向量。
![]()
右侧矩阵是经过训练得到的经验矩阵,Embedding × Wq得到q,以此类推。新的向量的长度不是一定小于Embedding的。
那么,query、key、value向量是什么?
它们都是为了更好地计算和理解的抽象概念。
其次,是计算得分。如果是计算第一个单词,就将第一个单词的q分别乘以所有单词的k,得到score。
![]()
接下来:是将得分除以维度开平方,以保证更稳定的梯度,之后通过Softmax层求权重:
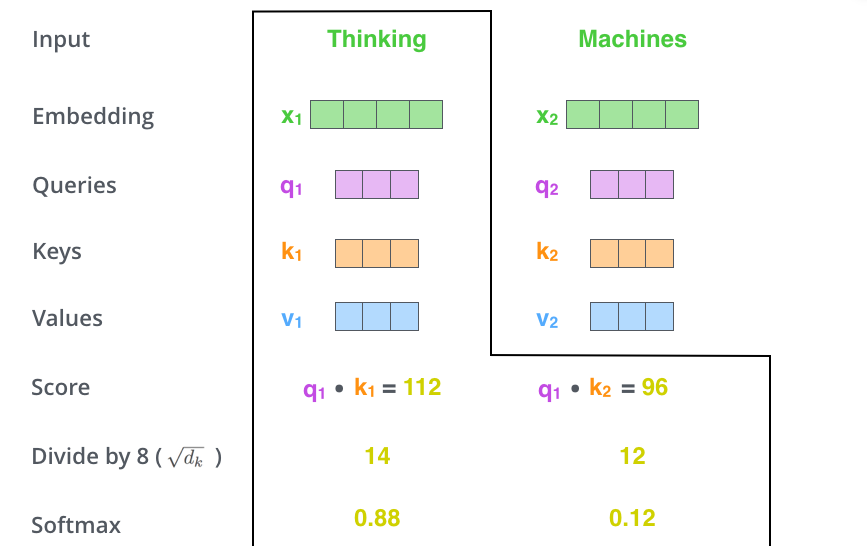
Softmax层决定了每个单词在这个位置表达了多少,明显的,当前单词的权重是最大的,但是有些时候,加入另一个与当前单词相关的单词很有用。
第五步是用Softmax得分乘以每一个自己的value值,这一步的意图是将我们想要关注的值保留而丢弃不需要关注的。
第六步是将所有加权向量加起来,得到这个位置这一层的输出:
这个过程可以通过矩阵运算得到,速度更快:
5. Matrix Calculation of Self-Attention


5. The Beast With Many Heads
Paper通过添加multi-headed机制重新定义了Self-Attention层,这使得在以下两部分提升Attention的表现:
- 扩展了模型来关注其他位置的能力
- 给了Attention层多个表示子空间
![img]()
对于每个head的权重不同,因此是取决于不同的子空间来发掘信息。但是会得到多个Z(对应于每一个Attention),要将这多个vector变成一个:我们将每一个连接起来并乘以一个权重矩阵:
![]()
![]()
Overall Graph
在实际应用中,我们会发现it的指代在一些head中是名词,另一些是形容词,即角度不同。
![]()
6. Representing The Order of The Sequence Using Positional Encoding
到目前为止,我们描述的模型中缺少的一件事是一种解释输入序列中单词顺序的方法,为了解决这个问题,Transformer为每个Embedding增添了位置向量。这些向量遵循模型学习的特定模式,这有助于确定每个单词的位置或序列中不同单词之间的距离。
![]()
![]()
这个是一个20个单词,Embedding size是512的Positional encoding。(???)
6. The Residuals
![]()
如果打开来看的话,具体是这样的:
![]()
对于Decoder来说也是这样的:![]()
7. The Decoder Side
Encoder的顶层将一系列K和V向量输送到Decoder的每一个小的Decoder以帮助Decoder更好地关注正确的位置。
重复这一个步骤知道生成结束符位置。每一步的输出被送到下一个时间步骤的底层并按照Encoder一样处理。不过在Self-Attention方面,只关注前面的已经输出的单词,而不是后面的为输出的单词。
Encoder-Decoder Attention则像多头Self-Attention一样工作,除了其从前面取出K、V直接进行乘积操作。
8. The Final Linear and Softmax Layer
![]()
9. Recap Of Training
10. The Loss Function
![]()
比较概率分布使用cross-entropyand Kullback–Leibler divergence.
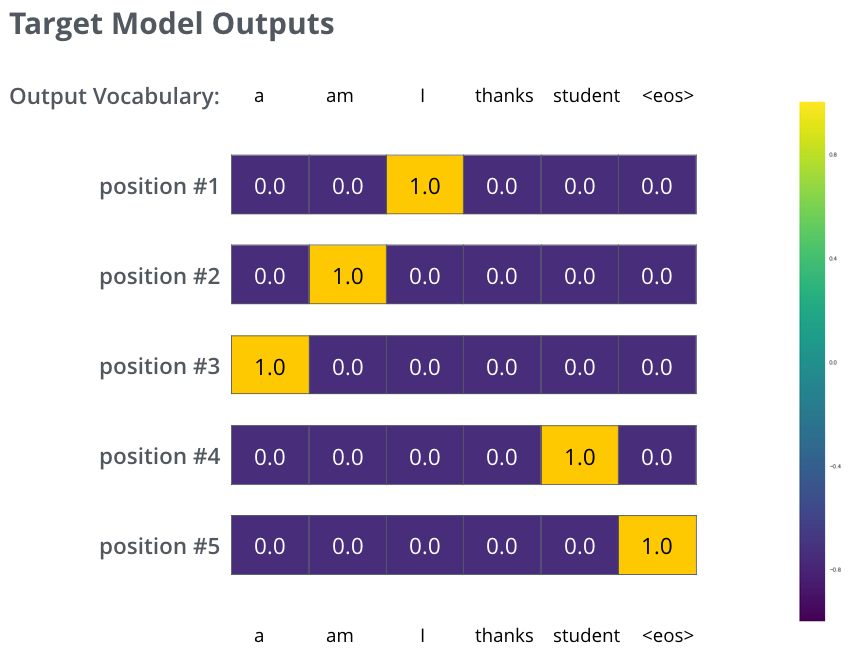
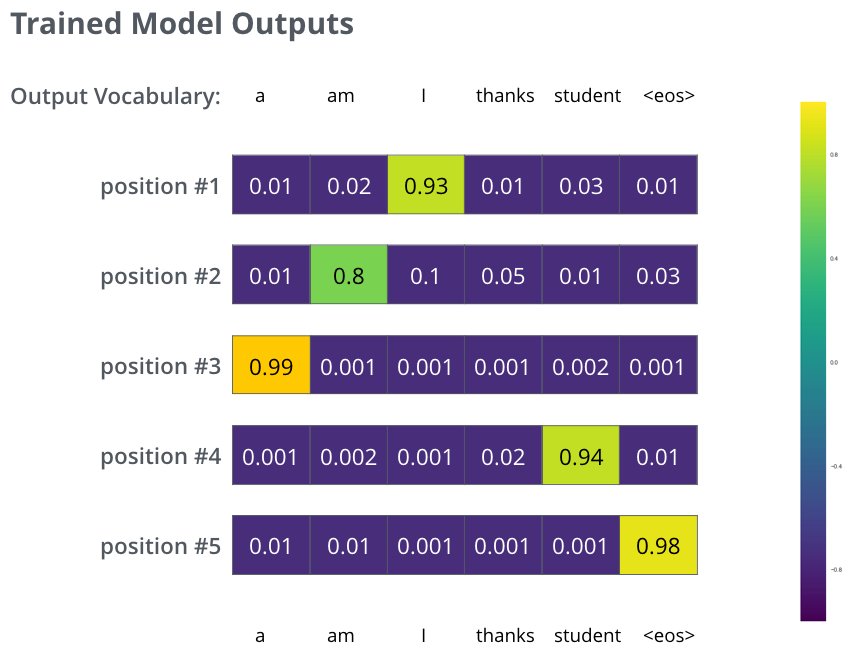
在训练过程中,分布是均匀的,而上图是我们的目标,因此要进行训练,可能会达到以下效果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号