Reinforcement Learning学习笔记|从Q-Learning到Actor Critic
Reinforcement Learning NOTE
最近,Deep Reinforcement Learning的应用和发现十分广泛,如Alpha GO。
我们将关注于学习解决增强学习的不同结构。包括Q-learning、Deep Q-Learning、Policy Gradient、Actor Critic 和 PPO。
Introduction
三个问题:
- What Reinforcement Learning is, and how rewards are the central idea
- The three approaches of Reinforcement Learning
- What the “Deep” in Deep Reinforcement Learning means
Answer:
-
增强学习的观念是:agent通过与环境交互和接受对于特定动作的奖励(或者惩罚)来从环境中学习。
-
我们的目标是最大化累计期待奖励。但是实际情况中,更早发生的奖励会更容易发生。因此我们定义奖励折扣gamma,是一个基于0-1之间的数字。
即,随着时间的流逝,奖励会以指数形式不断打折扣(减少)
-
学习的情景分类中,有带有起始状态的,和不带结束状态的。
-
我们有两种学习方法:
-
在每一个回合结束收集奖励之后计算最大的期待未来奖励:Monte Carlo Approach。
在Monte Carlo方法中,只会在游戏的最后计算奖励,之后会开启新的游戏。
公式1
-
在每一步后计算奖励:TD Learning。
TD method的目标是一个估计,实际上,要用之后一步的目标去更新之前的估计。
公式2
-
-
The Exploration/Exploitation Trade-off.
- Exploration是在寻找环境中的更多的信息
- Exploitation是利用已知只是去最大化奖励
- 我们的目的是最大化期望积累奖励,但是可能会进一个怪圈。
-
学习的是三种方法
- value-based,目标是优化值函数,值函数是用来告诉我们未来最大期待奖励的,对于某一个特定的状态。
- policy-based,这个方法就是直接给出要选择哪个动作,而不需要值函数。有两中策略:
- 决定性的:在特定状态,每次都会返回同样的动作
- 随机的:根据状态对应的概率来返回动作
- model-based:NULL
-
Deep RL Learning
因为使用了深度神经网络,所以加了Deep。
Diving deeper into Reinforcement Learning with Q-Learning
Q-Learning是一个基于值的增强学习算法。内容如下:
- What Q-Learning is
- How to implement it with Numpy
Q-table是如果在特定状态下,选择最优策略的情况下,未来最大的的期待奖励的值。
为了学习Q-table,要用到Q Learning算法。
-
Q-learning:Action-Value Function(也叫作Q function)输入是state和action。这个函数会返回在特定状态执行特定动作的期待奖励。
![img]()
在我们未探索环境之前,Q-table的值是随机的。当我们探索环境时,Q-table会通过不断运用Bellman等式更新,来给我们越来越好的估计值。
-
Q-Learning算法过程:
![img]()
-
初始化Q-table所有的值,一般为0
-
3-5重复进行,知道我们到了最大回合或者人为停止
-
选择一个动作。但是开始的时候选择哪一个呢,大家都是零。
这里用到了exploration/exploitation trade-off 。即epsilon greedy strategy。
设置一个变量epsilon,初始为1,表示不使用Q-tbale的概率,因为此时Q-table不够可信。但是随着时间推移,epsilon会不断降低。
-
估计:
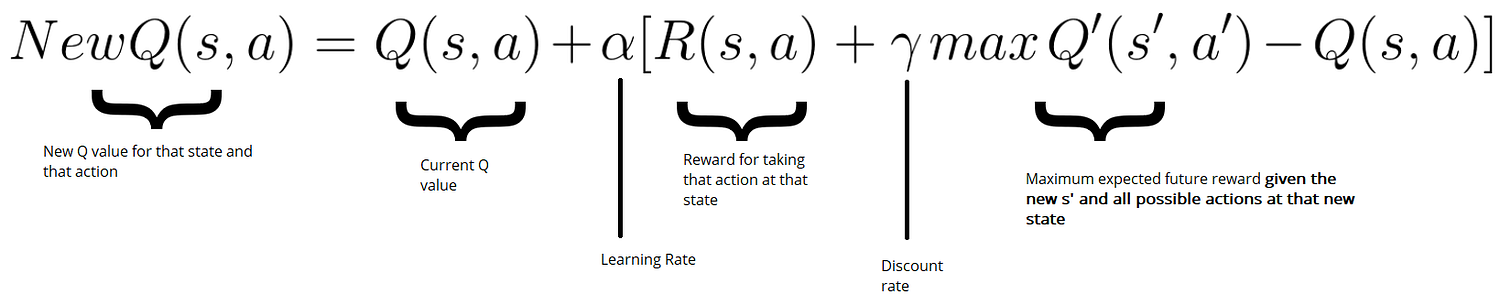
根据第三步的选择,我们执行动作并返回新的state和reward,通过Bellman 等式更新Q(s,a):
![img]()
-
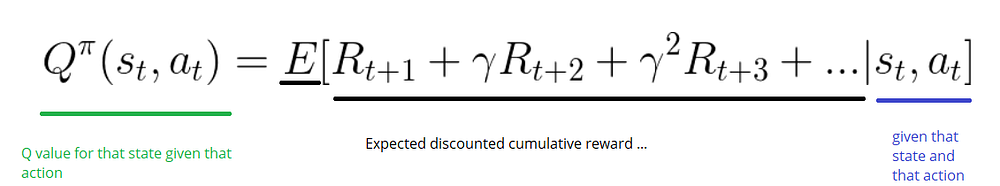


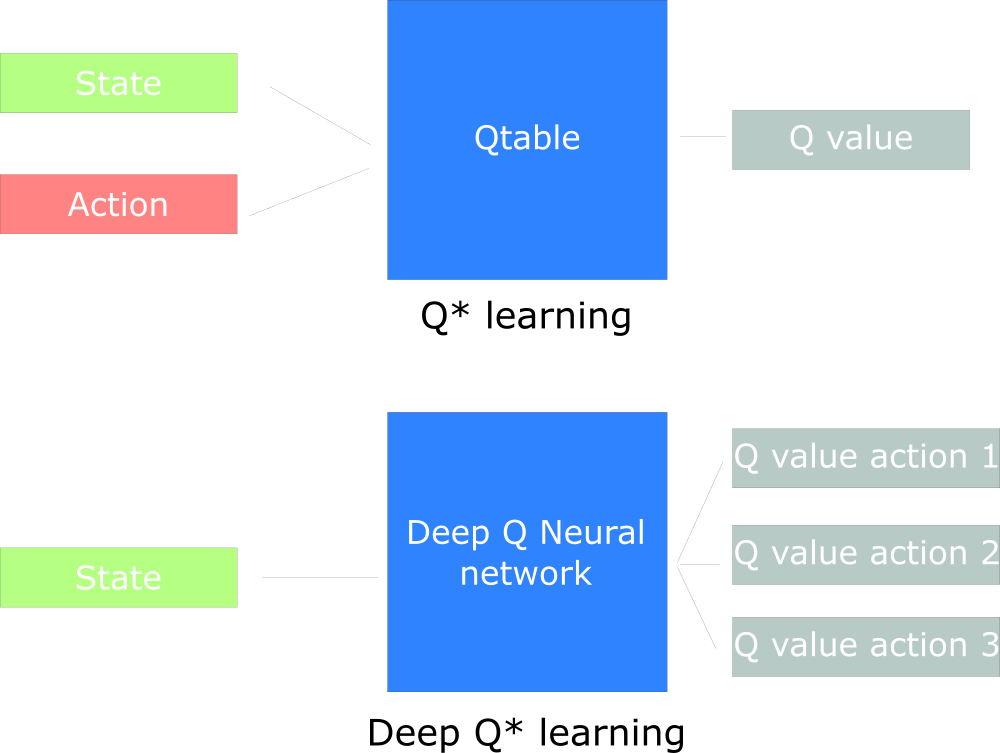
Deep Q-learning
我们不再使用Q-table,我们使用了神经网络来评估给定状态的各个action的Q值。
- What is Deep Q-Learning (DQL)?
- What are the best strategies to use with DQL?
- How to handle the temporal limitation problem
- Why we use experience replay
- What are the mathematics behind DQL
- How to implement it in Tensorflow
对于炒鸡大的环境,如果建立Q-table肯定不现实。最好的方法是建立一个神经网络会大致给出给定状态不同动作的Q值。
-
The Architecture
![img]()
DQNN输入四个帧,他们通过神经网络输出每一个动作可能的Q值。我们需要选择向量中最大的值。开始的话表现差,但是一切都会好起来的
-
预处理部分。可以来减少运算量。
-
我们要关注时序信息,则要需要更多的信息。
-
使用卷积神经网络。
-
经验重现。
-
避免忘记之前的经验。

Policy Gradients
在Policy-based方法中,不是学习值函数来告诉我们期待奖励,我们直接学习策略函数,可以将状态和放多对应起来。
In this article you'll learn:
- What is Policy Gradient, and its advantages and disadvantages
- How to implement it in Tensorflow.
有两种方法:决定性的随机的。
-
决定性的策略是状态对应行为的那种,适用于确定性环境中。
-
随机的输出转移概率,反之。
-
大多数情况是用随机的
-
优势?
- 收敛性更好。
- 在高维空间中更加高效。
- 可以学习随机策略。我们不需要使用exploration/exploitation trade off,因为有随机的情况存在。也可以摆脱感知混淆的问题。
-
劣势?
- 收敛在局部最优而非全局最优(好吧)
-
π(a|s)=P[a|s],将其看做优化问题,我们必须寻找最好的参数来最大化J(θ),共计两步
- 使用J来衡量π的好坏
- 用策略梯度上升的方法寻找最好的参数。
-
第一步:
-
我们使用目标函数(策略得分函数)计算策略的期待奖励。有三个差不多效果的方法,根据环境进行选择。
-
在一个情节环境中,如果从s1出发,总奖励是多少?
![img]()
-
在连续环境中,我们使用平均值,因为我们不能以来一个特定开始状态。
![img]()
-
第三种,我们使用每一个时间步骤的平均奖励。我们想得到每一步的最大奖励。
-
-
-
第二步:梯度上升
-
我们已经找到了评价标准,现在需要去最大化得分函数。需要梯度上升。
-
为什么是梯度上升而不是下降?因为我们想最大化而非最小化。
-
我们想找的最合适的theta:
![img]()
-
我们的目标是求J的梯度:
![img]()
但是偏导一个概率很难,除非是对数形式。因此,我们使用似然比例技巧:
![img]()
之后转换为期望形式:
![img]()
我们只需要计算log策略函数的偏导。我们对于策略梯度:
![img]()
-
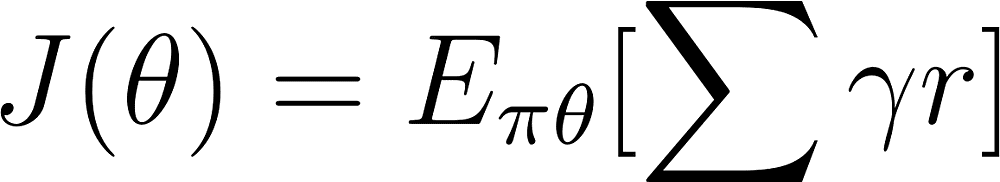
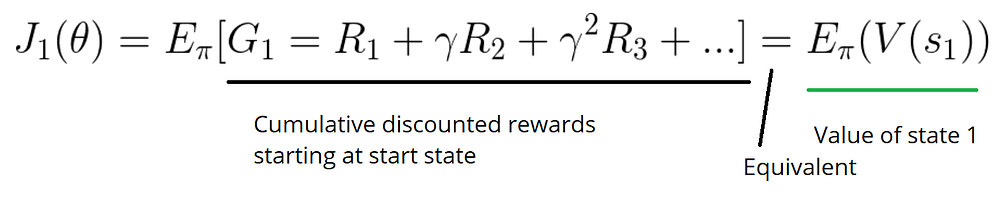
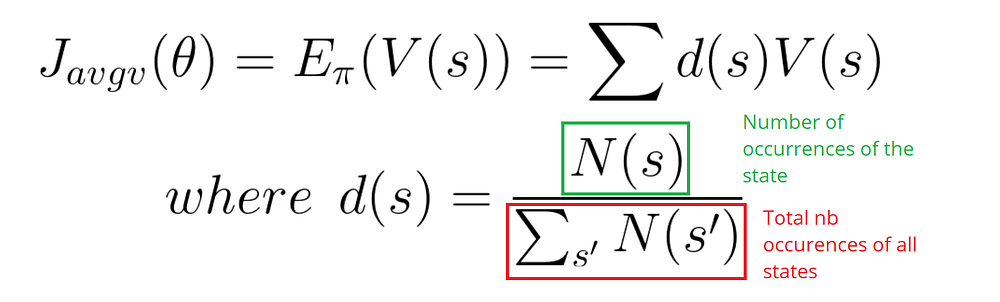
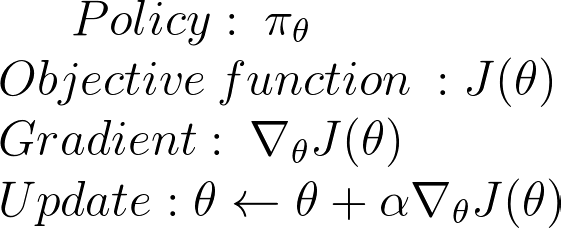
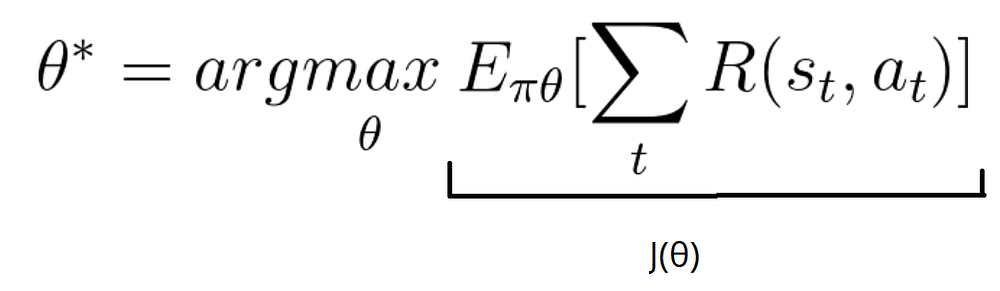
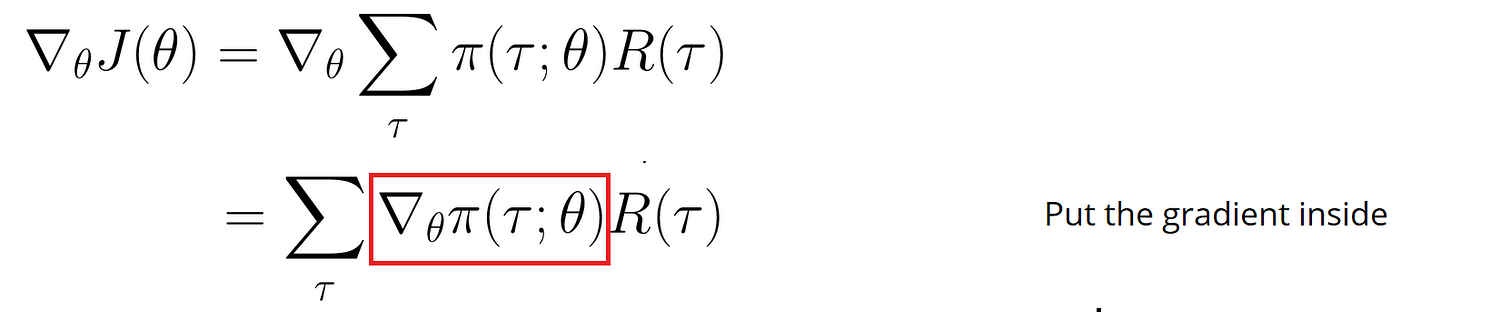

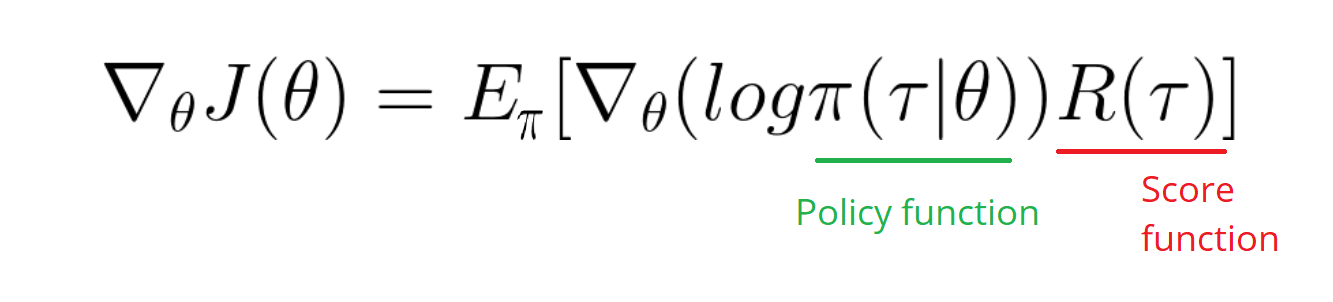

Advantage Actor Critic Method
Policy Gradient有着很大的问题,如果我们在一个Monte Carlo的序列情景中,等待序列结束来计算奖励。就算过程中有坏的action(reward)我们也会计算在其中。
因此,为了有一个最优的策略我们不得不去做大量的采样。这是一个缓慢的过程,因为需要很长时间才可以去收敛。那么如果对于Monte Carlo序列,在每一个步骤都进行更新呢。
-
我们在每一步进行更新:TD Learning。
![img]()
因此,我们不需要总的reward,而是我们需要去训练一个Critic模型,这个模型可以大致相当于值函数。这个值函数代替了Policy Gradient中只在回合结束的时候计算奖励的奖励函数。
-
Actor Critic有着两个神经网络。
Actor:策略函数,控制agent如何行动
Critic:值函数,衡量动作的价值。
这两个网络是并行运行的。而且,两个网络,两套参数,必须分开优化。
![img]()
-
算法过程:
-
在每一个时间步骤,我们取现在的状态,将这个作为输入输入到Actor和Critic中。
-
策略部分输出一个策略,得到新状态和奖励。
-
Critic计算在该状态执行该动作的值,而Actor用这个q值更新权重。
![img]()
-
Actor在更新完参数后,产生下一个状态,Critic利用这个状态更新它的值参数。
![img]()
Advantage Actor Critic
以值为基础的方法有这高变动性的,为了解决这个问题,我们使用Advantage function而非值函数,定义如下:
![img]()
这个函数会告诉我们,与一般的动作相比,该动作在该状态执行下的提升有多少,即额外奖励。如果大于0,则梯度朝向该方向前进,否则反之。
我们可以将TD error作为Advantage function的很好的估计。
![img]()
-
-
A2C是Advantage Actor Critic,A3C是异步,Asynchronous Advantage Actor Critic。
A3C算法中建立多个Agent,共同运行并实时更新全局网络的权重值。
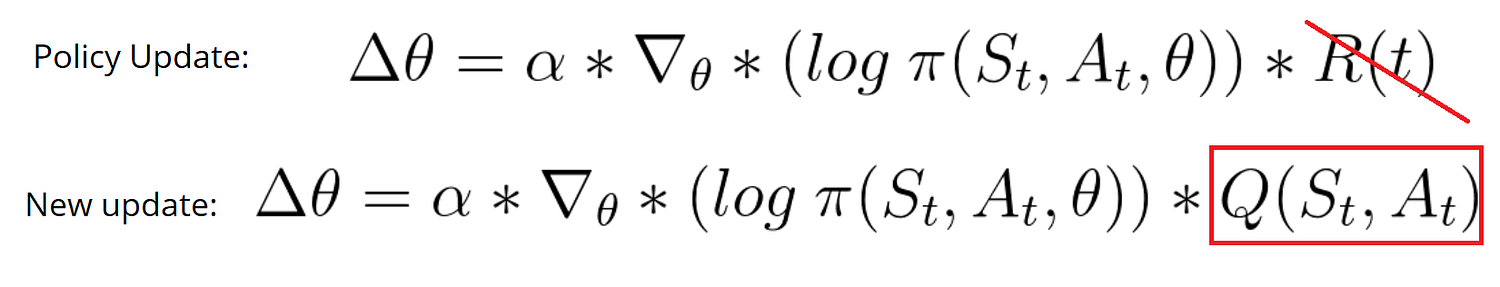
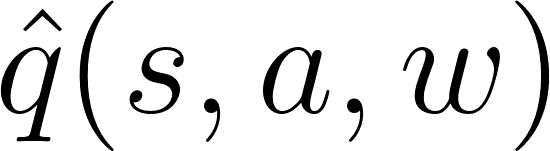

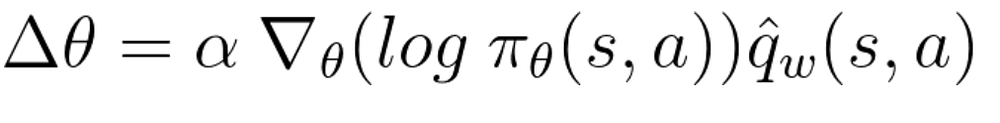
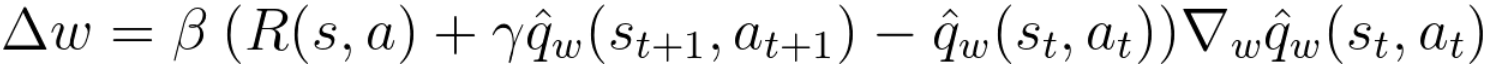



 浙公网安备 33010602011771号
浙公网安备 33010602011771号