WordCount优化
WordCount_Update
github项目地址
https://github.com/BillCYJ/WordCountPro
代码用的是姜骁腾的代码,测试用例是我自己写的,他的项目地址:https://github.com/skz12345/wcPro
PSP表格
| PSP2.1 | PSP阶段 | 预估耗时(小时) | 实际耗时(小时) |
| Planning | 计划 | 0.5 | 0.5 |
| Estimate | 估计任务需要多少时间 | 0 | 0 |
| Development | 开发 | 0 | 0 |
| Analysis | 需求分析 | 0 | 0 |
| Design Spec | 生成设计文档 | 0 | 0 |
| Design Review | 设计复审 | 0 | 0 |
| Coding Standard | 代码规范 | 0 | 0 |
| Design | 具体设计 | 0 | 0 |
| Coding | 具体编码 | 0 | 0 |
| Code Review | 代码复审 | 0 | 0 |
| Test | 测试 | 2 | 1 |
| Reporting | 报告 | 1 | 2 |
| Test Report | 测试报告 | 0.5 | 1 |
| Size Measurement | 计算工作量 | 0.5 | 0.5 |
| Postmortem | 总结 | 0.5 | 0.5 |
| 合计 | 5 | 5.5 |
一、基本任务
1.接口实现:
在该项目中,我负责输入控制模块,也就是先从参数中获取文件路径,再读取文件内容,并且需要对输入进行有效性检查。输入检查包括:判断输入文件是不是空文件、输入是不是符合输入要求、输入格式是否正确等多方面。
openFileAndPull 函数的功能是:处理输入。先判断输入文件是不是空文件,再判断文件格式是否正确,然后按行读取字符串,在每行字符串末尾加上一个换行符,全部存在result里面,每次都涉及到result这个字符串的拼接(字符串拼接有一个特别需要优化的地方,该文章在性能优化部分会详细说明,现在可以看我写的一篇博客,先了解一下:字符串拼接的性能分析),最后返回整个字符串result。
部分代码如下:(用的是姜骁腾的代码)
public String openFileAndPull () { if((this.filepath).length()==0)//判断输入是否为空,是则抛出异常 throw new IllegalArgumentException("Please input the filename!"); File file = new File(filepath); if(!file.getName().endsWith(".txt"))//判断是否文件后缀为.txt,否则抛出异常 throw new IllegalArgumentException("Error file format!"); try{ BufferedReader reader=null; StringBuilder strings=new StringBuilder(); reader=new BufferedReader(new FileReader(file)); String readline=""; while((readline=reader.readLine())!=null)//按行读取文件内容 { strings.append(readline+"\n");//每行末尾添加一个换行符 readline=null; } this.result=strings.toString();//将结果存入result if(isContainChinese(result))//调用方法判断result中是否有中文字符 { System.out.println("(文本中有中文字符)"); } reader.close(); } catch (Exception e) { System.out.println("Error path name!"); } return result; }
2.测试用例设计:
总共设计了20个测试用例,白盒测试和黑盒测试这两种方法都用到了。
白盒测试:我使用了语句覆盖指标设计测试用例,还覆盖了if分支。
黑盒测试:对多种输入情况进行了测试,比如:判断输入文件是不是空文件、输入是不是符合输入要求、输入格式是否正确、输入有无中文文字等方面。
部分测试用例如下表:
| Test Case ID 测试用例编号 | Test Item 测试项(即功能模块或函数) | Test Case Title 测试用例标题 |
重要级别 |
预置条件 | Input输入情况 | Procedure 操作步骤 | Output预期结果 | Output实际结果 |
Status是否通过计划 | Remark 备注(在此描述使用的测试方法) |
|---|---|---|---|---|---|---|---|---|---|---|
| 2_1 | 输入控制模块 | 空文件测试 | M | 无 | NULL | 无 |
ERROR |
ERROR |
是 | 白盒测试 |
| 2_2 | 输入控制模块 | 无后缀测试 | M | 无 | test | 无 |
ERROR |
ERROR |
是 | 白盒测试 |
| 2_3 | 输入控制模块 | 文件名有中文测试 | L | 无 | 我.txt | 无 |
ERROR |
ERROR |
是 | 白盒测试 |
| 2_4 | 输入控制模块 | 输入文件名错误测试 | H | 无 | tt.txt | 无 |
空 |
空 |
是 | 白盒测试 |
| 2_5 | 输入控制模块 | 文件后缀名错误测试 | H | 无 | test.c | 无 |
ERROR |
ERROR |
是 | 黑盒测试 |
| 2_6 | 输入控制模块 | 文件后缀名错误测试 | H | 无 | test.cpp | 无 |
ERROR |
ERROR |
是 | 黑盒测试 |
| 2_7 | 输入控制模块 | 文件后缀名错误测试 | H | 无 | test.java | 无 |
ERROR |
ERROR |
是 | 黑盒测试 |
| 2_8 | 输入控制模块 | 文件后缀名错误测试 | H | 无 | test.html | 无 |
ERROR |
ERROR |
是 | 黑盒测试 |
| 2_9 | 输入控制模块 | 文件后缀名错误测试 | H | 无 | test.md | 无 |
ERROR |
ERROR |
是 | 黑盒测试 |
| 2_10 | 输入控制模块 | 文件后缀名错误测试 | H | 无 | test.js | 无 |
ERROR |
ERROR |
是 | 黑盒测试 |
| 2_11 | 输入控制模块 | 输入过多测试 | M | 无 | test1.txt test1.txt | 无 |
ERROR |
ERROR |
是 | 黑盒测试 |
| 2_12 | 输入控制模块 | 正确输入测试 | H | 无 | test2.txt | 无 |
"Let's go"+"\n" |
"Let's go" |
是 | 黑盒测试 |
| 2_13 | 输入控制模块 | 正确输入测试 | H | 无 | test3.txt | 无 |
"Let's\ngo"+"\n" |
"Let's go"+"\n" |
是 | 黑盒测试 |
| 2_14 | 输入控制模块 | 正确输入测试 | H | 无 | test4.txt | 无 |
"abc-cba\a-c"+"\n" |
"abc-cba\a-c"+"\n" | 是 | 黑盒测试 |
| 2_15 | 输入控制模块 | 正确输入测试 | H | 无 | test5.txt | 无 |
"好不好"+"\n" |
"好不好"+"\n" | 是 | 黑盒测试 |
| 2_16 | 输入控制模块 | 正确输入测试 | H | 无 | test6.txt | 无 |
"dasd你"+"\n" |
"dasd你"+"\n" | 是 | 黑盒测试 |
| 2_17 | 输入控制模块 | 文件中是否有汉字测试 | M | 无 | test7.txt | 无 |
True |
True |
是 | 黑盒测试 |
| 2_18 | 输入控制模块 | 文件中是否有汉字测试 | M | 无 | test8.txt | 无 |
Flase |
Flase |
是 | 黑盒测试 |
| 2_19 | 输入控制模块 | 输入只有汉字测试 | M | 无 | test9.txt | 无 |
ERROR |
ERROR |
是 | 黑盒测试 |
| 2_20 | 输入控制模块 | 文件中有很多字符串 | M | 无 | test10.txt | 无 | 正确输出 | 正确输出 | 是 | 黑盒测试 |
3.单元测试运行结果:
设计的测试用例全部通过了测试,运行时间极短,符合要求。
测试用例基本覆盖了所有可能出现的情况,并覆盖了所有分支。
测试结果如图:
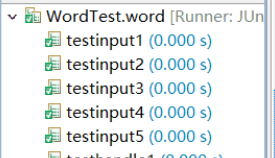
4.小组贡献率:
经小组成员讨论,我做的输入部分在本项目中的小组贡献率为0.26。
二、扩展任务
1.开发规范:
使用《阿里巴巴 Java 开发手册》作为代码规范。例如:如果该函数实现了非常复杂的功能导致函数过长,这样会使得代码难以理解阅读,不利于阅读以及修改。所以,尽量将函数体限制在一个屏幕的大小。在邹欣老师的“现代软件工程讲义3 代码规范与代码复审”中,知道了代码需要遵循一定的风格规范和设计规范,代码风格应该力求简明易读,在一些细节方面需要养成习惯。
2.静态代码检查:
选择的工具:Alibaba Java Coding Guidelines
下载地址:https://github.com/alibaba/p3c
3.组员代码评价:
我负责检查谭淼的代码,可以看出,他的编码习惯还是比较好的,存在的问题就是命名很乱,很难理解他定义的变量的意思;另外,注释较少,应在关键的地方增加注释!这也是我们小组存在的最大的问题。
三、高级任务
1.测试数据集
使用大文件的数据集来对本程序进行压力测试。我使用了一本英文的电子书作为测试集的来源,分别构造出了大小为100K,1M,4M,16M的数据集,并记录运行时间。
2.同行评审
本次评审的结论:
1.代码注释较少
2.代码冗余严重
3.用str1+=str2这种方法的字符串拼接会生成额外的对象,消耗大量性能和内存
3.性能优化
1.字符串拼接,别用str1+=str2
2.用冒泡排序、快速排序、堆排序,需要根据输入的数据量、内存的限制、速度的限制等多方面综合考虑
4.小组分工及所输出的贡献
陈云佳:输入模块 0.26
谭 淼:核心模块 0.26
黄成宇:核心模块 0.24
赖御纶:输出模块 0.24
参考
http://www.cnblogs.com/hayitutu/
https://blog.csdn.net/billcyj/article/details/79777701

 浙公网安备 33010602011771号
浙公网安备 33010602011771号