聚类之DBSCAN
产生数据
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.cluster import KMeans,DBSCAN
X, y = datasets.make_circles(n_samples=2000, factor=0.6, noise=0.06)
fig = plt.figure(figsize=(4,4))
plt.scatter(X[:,0],X[:,1],marker='o',s=5)

进行聚类
y_pred = DBSCAN(eps=0.1, min_samples=10).fit_predict(X)
fig = plt.figure(figsize=(4,4))
plt.scatter(X[:,0],X[:,1],c=y_pred,s=5)
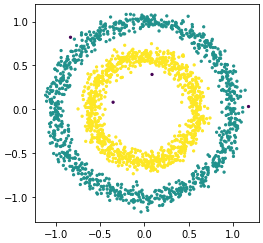
在y_pred中,通过0,1和-1来记录聚类据结果,其中-1表示噪点,每一种类别的点的数量打印如下
y_pred = list(y_pred)
print('类别0:',y_pred.count(0))
print('类别1:',y_pred.count(1))
print('噪点:',y_pred.count(-1))


 浙公网安备 33010602011771号
浙公网安备 33010602011771号