数据结构--单向链表
C语言中,我们在使用数组时,会需要对数组进行插入和删除的操作,这时就需要移动大量的数组元素,但在C语言中,数组属于静态内存分配,数组在定义时就必须指定数组的长度或者初始化。这样程序一旦运行,数组的长度就不能再改变,若想改变,就只能修改源代码。实际使用中数组元素的个数也不能超过数组元素的最大长度,否则就会发生下标越界的错误(这是新手在初学C语言时肯定会遇到的问题,相信老师也会反复强调!!!但这种问题肯定会遇到,找半天找不到错误在哪,怪我咯???)。另外如果数组元素的使用低于最大长度,又会造成系统资源的浪费,会导致降低空间使用效率。
那有没有更合理的使用系统资源的方法呢?比如,但需要添加一个元素时,程序就可以自动的申请内存空间并添加新的元素,而当需要减少一个元素时,程序又可以自动地释放该元素占用的内存空间。我们聪明的祖先早就意识到了这个问题,于是就有了动态数据结构--链表结构(Linked list)。它主要是利用动态内存分配、使用结构体并配合指针来实现的一种数据结构。
链表有三种不同的类型:单向链表,双向链表以及循环链表。今天我们只对单向链表做详细的说明。
链表中最简单的一种是单向链表,它包含两个域,一个信息域和一个指针域。这个链接指向列表中的下一个节点,而最后一个节点则指向一个空值(NULL)。
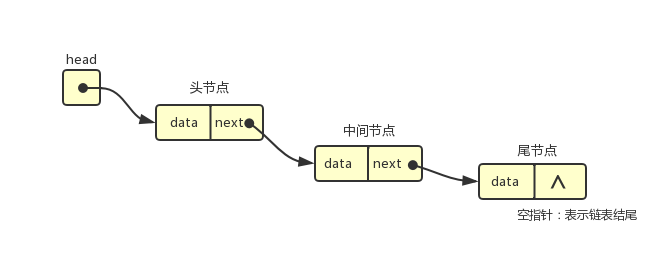
单向链表的存储结构
/*单向链表的代码表示*/
struct node
{
int data; // 数据域
struct node *next; // 指向下一个节点的指针
};
接下来进入正题,分别详细讲一下单向链表的插入、删除节点以及插入节点操作。
- 单向链表的建立
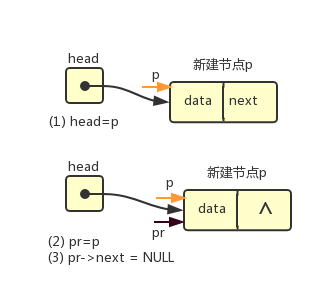
建立一个单向链表,我们可以使用向链表中添加节点的方式。首先,要为新建的节点动态申请内存空间,让指针变量指向这个新建节点,然后将新建节点添加到链表中,这时,我们需要考虑以下两种情况:
(1)若原链表为空,则将新建节点设置为头节点
(2)若原链表为非空,则将新建节点添加到表尾
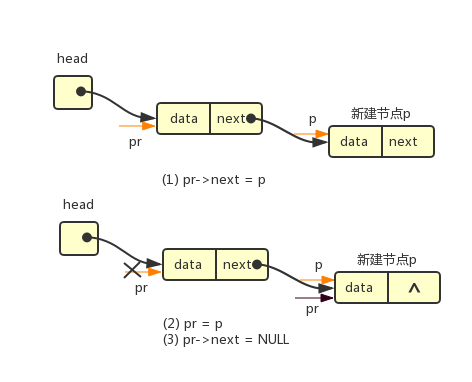
具体代码如下:
#include "stdio.h"
#include "stdlib.h"
struct link \*AppendNode(struct link \*head);
void DisplayNode(struct link *head);
void DeleteMemory(struct link *head);
struct link {
int data;
struct link *next;
};
int main(int argc, char const *argv\[\])
{
int i = 0;
char c;
struct link *head = NULL; //链表头指针
printf("Append a new node(y/n)?");
scanf("%c", &c);
while(c == 'Y' || c == 'y'){
head = AppendNode(head); //向head为头指针的链表末尾添加节点
DisplayNode(head);
printf("Append a new node(y/n)?");
scanf(" %c", &c);
i++;
}
printf("%d new nodes have been appened!\\n");
DeleteMemory(head);
return 0;
}
// 新建一个节点并添加到链表末尾,返回添加节点后的链表的头指针
struct link \*AppendNode(struct link \*head){
struct link \*p = NULL, \*pr = head;
int data;
p = (struct link *)malloc(sizeof(struct link)); // 通过malloc函数动态的申请内存,注意结构体占用内存的大小只能用sizeof()获取
if (p == NULL){
printf("No enough memory to allocate!\\n");
exit(0);
}
if (head == NULL){ //原链表为空
head = p;
}else{ // 原链表为非空,则将新建节点添加到表尾
while(pr->next != NULL){ // 如果pr指向的不是表尾,则移动pr直到指向表尾
pr = pr->next;
}
pr->next = p;
}
printf("Input node data:");
scanf("%d",&data); // 输入新建节点的数据
p->data = data;
p->next = NULL; // 将新建节点置为表尾
return head;
}
// 显示链表中所有的节点
void DisplayNode(struct link *head){
struct link *p = head;
int j = 1;
while(p != NULL){ // p不在表尾,循环打印节点的值
printf("%5d%10d\\n", j, p->data);
p = p->next;
j++;
}
}
//释放head指向的链表中所有节点占用的内存
void DeleteMemory(struct link *head){
struct link \*p = head, \*pr = NULL;
while(p != NULL){ // p不在表尾,释放节点占用的内存
pr = p; // 在pr中保存当前节点的指针
p = p->next; // p指向下一个节点
free(pr); // 释放pr指向的当前节点占用的内存
}
}
代码运行结果如下: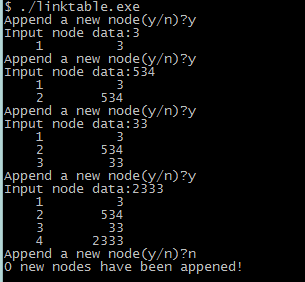
2. 单向链表的删除操作
链表的删除操作就是将待删除的节点从链表中断开,那么待删除节点的上一个节点就成为尾节点。在删除节点时,我们要考虑一下4种情况:
(1)若原链表为空,则不执行任何操作,直接退出程序
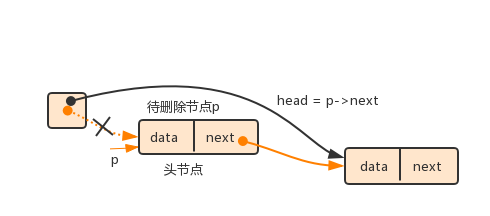
(2)若待删除节点是头节点,则将head指向当前节点的下一个节点,再删除当前节点
(3)若待删除节点不是头节点,则将前一节点的指针域指向当前节点的下一节点,即可删除当前节点。当待删除节点是尾节点时,由于p->next=NULL,因此执行pr->next = p->next后,pr->next的值也变为了NULL,从而使pr所指向的节点由倒数第二个节点变成尾节点。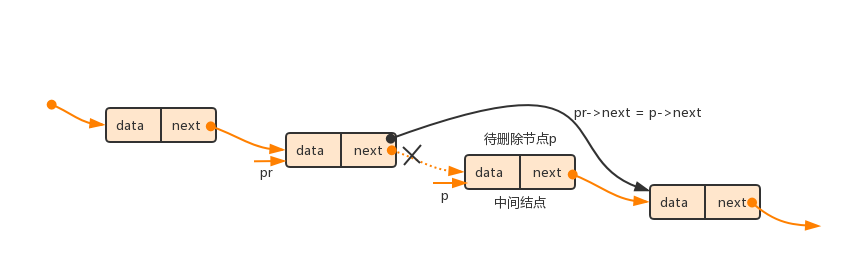
(4)若待删除的节点不存在,则退出程序
注意:节点被删除后,只表示将它从链表中断开而已,它仍占用着内存,必须要释放这个内存,否则会出现内存泄漏。
删除一个节点的代码如下:
// 从head指向的链表中删除一个节点,返回删除节点后的链表的头指针
struct link \*DeleteNode(struct link \*head, int nodeData)
{
struct link \*p = head, \*pr = head;
if (head == NULL) // 若原链表为空,则退出程序
{
printf("Linked Table is empty!\\n");
return head;
}
while(nodeData != p->data && p->next != NULL) // 未找到待删除节点,且没有到表尾
{
pr = p; // 在pr中保存当前节点的指针
p = p->next; // p指向当前节点的下一节点
}
if (nodeData == p->data) // 若当前节点就是待删除节点
{
if (p == head) // 若待删除节点为头节点
{
head = p->next; // 将头指针指向待删除节点的下一节点
}
else // 若待删除节点不是头节点
{
pr->next = p->next; // 让前一节点的指针指向待删除节点的下一节点
}
free(p); // 释放为已删除节点分配的内存
}
else // 没有找到节点值为nodeData的节点
{
printf("This Node has not been found!\\n");
}
return head; // 返回删除节点后的链表头指针
}
3. 单链表的插入操作
向一个链表中插入一个新节点时,首先要新建一个节点,并将新建节点的指针域初始化为空NULL,然后在链表中寻找适当的位置执行节点插入操作,此时需要考虑下面4种情况:
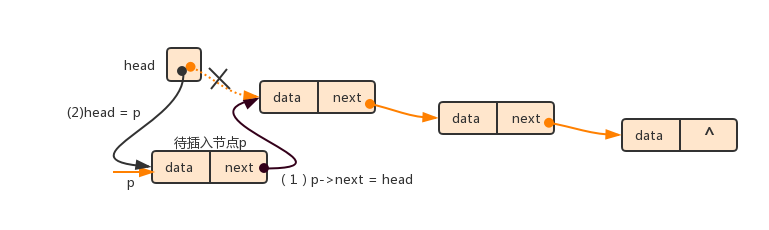
(1)若原链表为空,则将新建节点p作为头节点,让head指向新节点p
(2)若原链表为非空,折按新建节点的值的大小(假设原链表已按节点值升序排列)确定插入新节点的位置。若在头结点前插入新节点,则将新节点的指针域指向原链表的头结点,并且让head指向新节点p
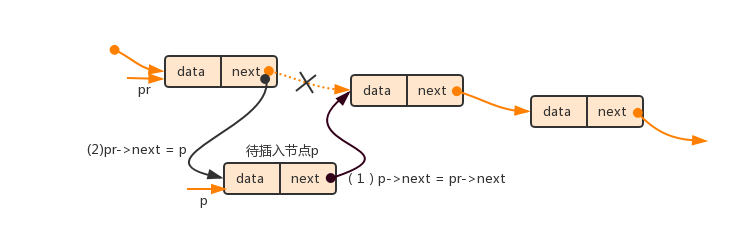
(3)若在原链表中间插入新节点,则将新节点p的指针域指向下一节点,并且让前一节点的指针域指向新建节点p
(4)若在表尾插入新节点,则将尾节点的指针域指向新节点p
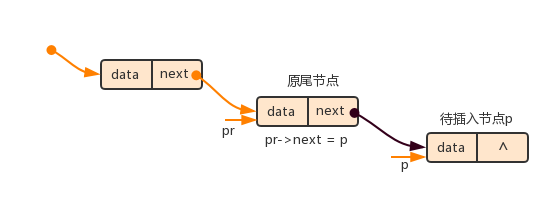
具体代码如下:
// 在已按升序排列的链表中插入一个新节点,返回插入节点后的链表头指针
struct link \*InsertNode(struct link \*head, int nodeData)
{
struct link \*pr = head, \*p = head, *temp = NULL;
p = (struct link *)malloc(sizeof(struct link)); // 给新建节点动态申请内存空间
if (p == NULL) // 若动态申请内存失败,则退出程序
{
printf("No enough memory!\\n");
exit(0);
}
p->next = NULL; // 将新建节点的指针域初始化为空
p->data = nodeData; // 将新建节点的数据域初始化为nodeData
if (head == NULL) // 若原链表为空
{
head = p; // 将新建节点作为头节点
}
else // 若原链表为非空
{
// 未找到新建节点的插入位置并且没有到尾节点
while(pr->data < nodeData && pr->next != NULL)
{
temp = pr; // 在temp中保存当前节点pr的指针
pr = pr->next; // pr跳到下一节点
}
// 找到需要插入的位置
if (pr->data >= nodeData)
{
if (pr == head) // 若当前节点为头节点,则将新建节点插入头节点之前
{
p->next = head; // 将新节点的指针域指向原链表的头节点
head = p; // head指向新建节点
}
else // 在原链表中插入新节点
{
pr = temp;
p->next = pr->next; // 新建节点的指针域指向当前节点的下一节点
pr-next = p; // 当前节点的下一节点指向新节点
}
}
else // 新建节点的值为最大值,插在原链表尾部
{
pr->next = p; // 原链表的尾节点指向新节点
}
}
return head; // 返回插入新节点后的链表的头指针
}
到此,对于单链表的操作已经介绍完了。通过写这篇博客,我也深刻学习了单链表的结构和一些主要操作,在写作的过程中也翻阅了很多资料,让我意识到数据结构的重要性,不懂数据结构,你永远只能当一个码农。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号