
009 Linux 文件大小统计与排序( du于df和sort)

01 du 与 df 作用与区别?
Linux 最有用最常用的统计文件大小命令是什么?无疑就是 du 和 df 了。
du(disk usage)
du 能看到的文件只是一些当前存在的,没有被删除的。
df(disk free)
df 主要用于 Linux 系统上的文件系统磁盘使用情况统计。
当我们删除一个文件的时候,这个文件不是马上就在文件系统当中消失,而是暂时消失,当所有程序都不用时,才会根据 OS 的规则释放掉已经删除的文件,df 记录的是通过文件系统获取到的文件的大小,它比 du 强的地方就是能够看到已经删除的文件。
df 和 du 不一致情况就是是否可看到被删除的文件,这也是 df 统计可能比 du 统计大的原因。
02 du 常用命令示例
-
du -h # 显示当前目录下所有文件及目录(包含子目录下内容)大小,-h 会换算成 K、M、G 等人类易读结果;
-
du -b # 或-bytes 显示目录或文件大小时,以byte为单位;
-
du -k # 或--kilobytes,以1024 bytes为单位;
-
du -m #或--megabytes 以1MB为单位
-
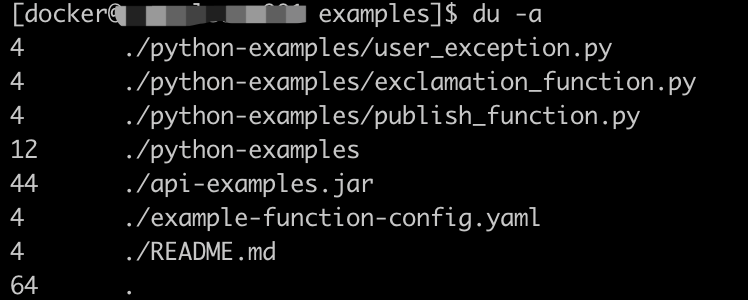
du -a # 显示当前目录下所有文件所占空间(含隐藏文件,包含目录,文件,层级目录下文件);
-
du -s # 显示当前目录总大小(不会列出层级子目录);

-
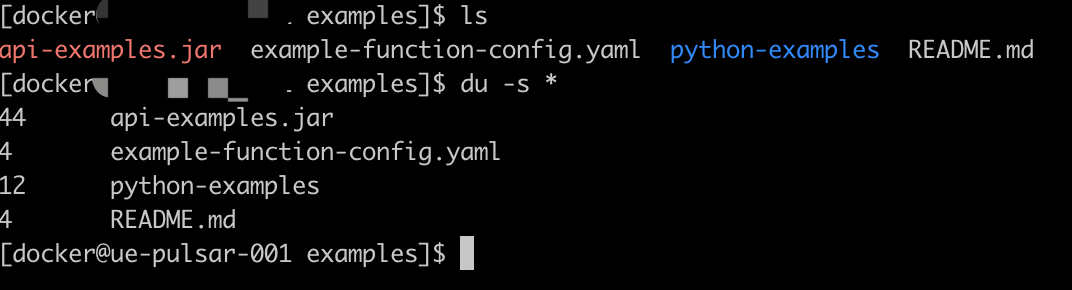
du -s * # 显示当前目录下每个文件夹和文件的大小(最常用)
-
du -s [文件夹1] [或文件1] # 显示指定目录或文件大小;

-
du --max-depth=1 [目录] # 只显示指定目录下第一层目录(不单个含文件)的大小;
-
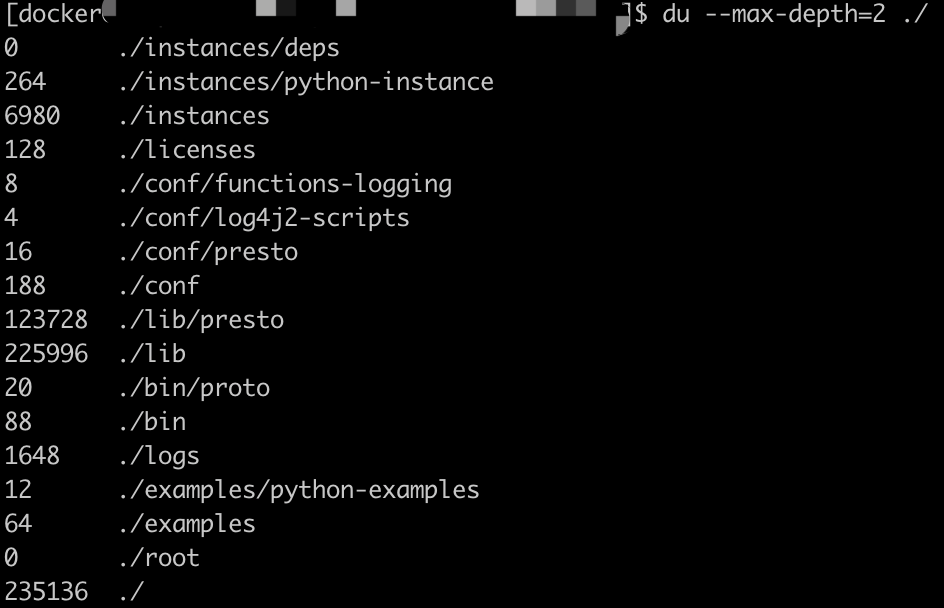
du --max-depth=2 [目录] # 只显示指定目录第一和二层目录(不含单个文件)的大小;
03 sort 常用参数
(sort 作用是将文件内容排序,以行为单位)
- -n # 依照数值的大小排序;
- -r # 以相反的顺序来排序;
- -o <输出文件> # 将排序后的结果存入制定的文件;
- -b # 忽略每行前面开始出的空格字符;
- -c # 检查文件是否已经按照顺序排序;
- -f # 排序时,将小写字母视为大写字母;
- -m # 将几个排序号的文件进行合并;
👇以下几个参数与 -n 排序方式互斥:
- -i # 排序时,除了040至176之间的ASCII字符外,忽略其他的字符;
- -d # 排序时,处理英文字母、数字及空格字符外,忽略其他的字符;
- -M # 将前面3个字母依照月份的缩写进行排序;
04 常用组合 du + sort + head
- du -a /temp/logs | sort -nr # 按照文件从大到小排序(含隐藏文件,包含目录,文件,层级目录下文件);
- du -m --max-depth=1 /temp/logs | sort -nr | head -n 10 # 指定目录第一层,显示前 Top10,-m: 统计单位为MB,为什么不用-h?sort 大小排序只看数字,不看单位,可能会导致 2G 反而排序在 200M 之后;(只显示指定目录下第一层目录(不单个含文件)的大小;)
- du -m --max-depth=1 /temp/logs | sort -nr -o 'sort.txt' | head -n 10 # 使用sort -o 参数将排序结果存入指定文件sort.txt 中。
05 如何删除文件,如大的日志文件?
通常使用 rm 命令删除文件以释放空间。但是我们无法删除文件是非常常见的,因为应用程序此时正在使用该文件,直接删除它们会产生有害影响,例如挂起应用程序,应用程序崩溃等。
方案一:
空字符串覆盖文件内容,是删除文件的一种优雅方式。
echo "" > info.log
方案二:
echo 不管用的特列情况,使用如下步骤。
- (1)du -sh * # 查看文件的使用情况;
- (2)du -h --max-depth=1 [文件目录]| sort -nr # 查找占用磁盘的文件目录的大文件,删除日志(优雅使用 echo "" > xx.log),发现磁盘使用率仍未下降;
- (3)lsof | grep delete # 发现有文件句柄并未释放的大文件,导致磁盘使用率未下降,文件已经 deleted 了,但是进程还未结束,所以直接kill;
- (4)kill -9 [pid] # kill 这个进程(这个要根据线上实际情况来看是否可以被 kill,最好优雅关闭进程),最后查看 df -h 恢复正常。
06 小结
du 常用的组合命令是与sort、head一起使用,排序找出最大的那批文件。在遇到磁盘溢满问题的时,可以与 find 命令合用找出最大的那一批文件删掉。与 sort 排序统计时使用具体的-m、-k参数,而不是用-h,否则会导致统计不准确。因为 sort -n 是根据数字大小,而不是单位进行统计。还有生产环境删除大文件的一些操作套路。
「不甩锅的码农」原创,转载请注明来源,未经授权禁止商业用途!同名 GZH 请关注!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~