【转+整理+答案】python315+道面试题

提示
自己整理的答案,很局限,如有需要改进的地方,或者有更好的答案,欢迎提出!
【合理利用 Ctrl+F 提高查找效率】
第一部分 Python基础篇(80题)
1、为什么学习Python?
# 因为python相对其他语言非常优雅简洁,有着丰富的第三方库,我感觉很强大、很方便; # 还有就是,我感觉python简单易学,生态圈庞大,例如:web开发、爬虫、人工智能等,而且未来发展趋势也很不错。
2、通过什么途径学习的Python?
# 在系里社团通过学长了解到python 根据个人情况而定…………
3、Python和Java、PHP、C、C#、C++等其他语言的对比?
# Python、PHP是解释型语言,代码运行期间逐行翻译成目标机器码,下次执行时逐行解释 # 而C、Java是编译型语言,编译后再执行。
4、简述解释型和编译型编程语言?
# 解释型:边解释边执行(python、PHP) # 编译型:编译后再执行(c、Java、C#)
5、Python解释器种类以及特点?
# CPython:C语言开发的,官方推荐,最常用 # IPython:基于CPython之上的交互式解释器,只是在交互上有增强 # JPython:Java写的解释器 # Pypy:Python写的解释器,目前执行速度最快的解释器,采用JIT技术,对Python进行动态编译 # IronPython:C#写的解释器
6、位和字节的关系?
#1字节=8位 #1byte=8bit (数据存储以字节(Byte)为单位)
7、b、B、KB、MB、GB 的关系?
1B=8bit 1KB=1024B 1MB=1024KB 1G=1024MB 1T=1024G
8、请至少列举5个 PEP8 规范(越多越好)。
#1、空格使用 a 各种右括号前不要加空格。 b 逗号、冒号、分号前不要加空格。 c 函数的左括号前不要加空格。如Func(1)。 d 序列的左括号前不要加空格。如list[2]。 e 操作符左右各加一个空格,不要为了对齐增加空格。 f 函数默认参数使用的赋值符左右省略空格。 g 不要将多句语句写在同一行,尽管使用‘;’允许。 8 if/for/while语句中,即使执行语句只有一句,也必须另起一行。 #2、代码编排 a 缩进,4个空格,而不是tab键 b 每行长度79,换行可使用反斜杠,最好使用圆括号。 c 类与类之间空两行 d 方法之间空一行
9、通过代码实现如下转换:
二进制转换成十进制:v = “0b1111011” 十进制转换成二进制:v = 18 八进制转换成十进制:v = “011” 十进制转换成八进制:v = 30 十六进制转换成十进制:v = “0x12” 十进制转换成十六进制:v = 87 ################################ v = 0b1111011 print(int(v)) v = 18 print(bin(v)) v = '011' print(int(v)) v = 30 print(oct(v)) v = 0x12 print(int(v)) v = 87 print(hex(v))
10、请编写一个函数实现将IP地址转换成一个整数。
如 10.3.9.12 转换规则为: 10 00001010 3 00000011 9 00001001 12 00001100 再将以上二进制拼接起来计算十进制结果:00001010 00000011 00001001 00001100 = ?


ip_addr = '192.168.2.10' # transfer ip to int def ip2long(ip): ip_list = ip.split('.') result = 0 for i in range(4): # 0,1,2,3 result = result + int(ip_list[i]) * 256 ** (3 - i) return result long = 3232236042 # transfer int to ip def long2ip(long): floor_list = [] yushu = long for i in reversed(range(4)): # 3,2,1,0 res = divmod(yushu, 256 ** i) floor_list.append(str(res[0])) yushu = res[1] return '.'.join(floor_list) a = long2ip(long) print(a)
11、python递归的最大层数?
Python中默认的递归层数约为998左右(会报错)
和计算机性能有关系,我的最大数字在3210 - 3220之间浮动
12、求结果:
v1 = 1 or 3 -- 1 v2 = 1 and 3 -- 3 v3 = 0 and 2 and 1 -- 0 v4 = 0 and 2 or 1 -- 1 v5 = 0 and 2 or 1 or 4 -- 1 v6 = 0 or Flase and 1 -- False ######################## and:前后为真才为真 or:有一为真就为真 优先级:()>not>and>or 同等优先级下,从左向右
13、ascii、unicode、utf-8、gbk 区别?
#Ascii: 1个字节 支持英文 #unicode :所有字符(无论中文、英文等)1个字符:4个字节 #gbk : 1个字符,英文1个字节,中文2个字节。 #utf-8 :英文1个字节,欧洲字符:2个字节, 亚洲: 3个字节。
14、字节码和机器码的区别?
- C代码被编译成机器码(二进制),在机器上直接执行。 - Cpython编译你的python源代码,生成字节码。 - 机器码快的多,字节码更易迁移,也安全。
15、三元运算规则以及应用场景?
# 三元运算符就是在赋值变量的时候,可以直接加判断,然后赋值 a = 1 b = 2 c = a if a > 1 else b # 如果a大于1的话,c=a,否则c=b
16、列举 Python2和Python3的区别?
'Print': py2--print; py3--print()函数 '编码': py2默认是ascii码; py3默认是utf-8 '字符串': py2中分ascii(8位)、unicode(16位); py3中所有字符串都是unicode字符串 'True和False': py2中是两个全局变量(1和0)可以重新赋值; py3中为两个关键字,不可重新赋值 '迭代': py2:xrange; py3:range 'Nonlocal': py3专有的(声明为非局部变量) '经典类&新式类': py2:经典类和新式类并存; py3:新式类都默认继承object 'yield': py2:yield py3:yield/yield from '文件操作': py2:readliens()读取文件的所有行,返回一个列表,包含所有行的结束符 xreadliens()返回一个生成器,循环取值 py3: 只有readlines()
17、用一行代码实现数值交换:
a = 1 b = 2 ########### a, b = b, a print(a, b)
18、Python3和Python2中 int 和 long的区别?
py3中没有long整型,统一使用int,大小和py2的long类似。
py2中int最大不能超过sys.maxint,根据不同平台大小不同;
在int类型数字后加L定义成长整型,范围比int更大。
19、xrange和range的区别?
#range产生的是一个列表,xrange产生的是生成器。 #数据较大时xrange比range好。 #Range一下把数据都返回,xrange通过yield每次返回一个。
20、文件操作时:xreadlines和readlines的区别?
# Readlines:读取文件的所有行,返回一个列表,包含所有行的结束符 # Xreadlines:返回一个生成器,循环使用和readlines基本一致 。(py2有,py3没有)
21、列举布尔值为False的常见值?
# []、{}、None、’’、()、0、False
22、字符串、列表、元组、字典每个常用的5个方法?
#Str: Split:分割 Strip:去掉两边的空格 Startwith:以什么开头 Endwith:以什么结尾 Lower:小写 Upper:大写 #List: Append:追加 Insert:插入 Reverse:反转 Index:索引 Copy:拷贝 Pop:删除指定索引处的值,不指定索引默认删除最后一个。 #Tuple: Count:查看某个元素出现的次数 Index:索引 #Dict: Get:根据key取value Items:用于循环,取出所有key和value Keys:取出所有key Values:取出所有的value Clear:清空字典 Pop:删除指定键对应的值,有返回值;
23、lambda表达式格式以及应用场景?
# 格式: 匿名函数:res = lambda x:i*x print(res(2)) # 应用场景: Filter(),map(),reduce(),sorted()函数中经常用到,它们都需要函数形参数; 一般定义调用一次。 (reduce()对参数序列中元素进行累积)
24、pass的作用?
# Pass一般用于站位语句,保持代码的完整性,不会做任何操作。
25、*arg和**kwarg作用
# 他们是一种动态传参,一般不确定需要传入几个参数时,可以使用其定义参数,然后从中取参 '*args':按照位置传参,将传入参数打包成一个‘元组’(打印参数为元组-- tuple) '**kwargs':按照关键字传参,将传入参数打包成一个‘字典’(打印参数为字典-- dict)
26、is和==的区别
==:判断某些值是否一样,比较的是值 is:比较的是内存地址(引用的内存地址不一样,唯一标识:id)
27、简述Python的深浅拷贝以及应用场景?
#浅拷贝: 不管多么复杂的数据结构,只copy对象最外层本身,该对象引用的其他对象不copy, 内存里两个变量的地址是一样的,一个改变另一个也改变。 #深拷贝: 完全复制原变量的所有数据,内存中生成一套完全一样的内容;只是值一样,内存地址不一样,一方修改另一方不受影响
28、Python垃圾回收机制?
# Python垃圾回收机制 Python垃圾回收机制,主要使用'引用计数'来跟踪和回收垃圾。 在'引用计数'的基础上,通过'标记-清除'(mark and sweep)解决容器对象可能产生的循环引用问题. 通过'分代回收'以空间换时间的方法提高垃圾回收效率。 '引用计数' PyObject是每个对象必有的内容,其中ob_refcnt就是做为引用计数。 当一个对象有新的引用时,它的ob_refcnt就会增加,当引用它的对象被删除, 它的ob_refcnt就会减少.引用计数为0时,该对象生命就结束了。 \优点:1.简单 2.实时性 \缺点:1.维护引用计数消耗资源 2.循环引用 '标记-清楚机制' 基本思路是先按需分配,等到没有空闲内存的时候从寄存器和程序栈上的引用出发, 遍历以对象为节点、以引用为边构成的图,把所有可以访问到的对象打上标记, 然后清扫一遍内存空间,把所有没标记的对象释放。 '分代技术' 分代回收的整体思想是: 将系统中的所有内存块根据其存活时间划分为不同的集合,每个集合就成为一个“代”, 垃圾收集频率随着“代”的存活时间的增大而减小,存活时间通常利用经过几次垃圾回收来度量。
29、Python的可变类型和不可变类型?
# 可变类型:列表、字典、集合 # 不可变类型:数字、字符串、元祖 (可变与否指内存中那块内容value)
30、求结果:
v = dict.fromkeys(['k1', 'k2'], []) # 内存中k1和k2都指向同一个[](内存地址相同),只要指向的[]发生变化,k1和k2都要改变(保持一致) v['k1'].append(666) print(v) # {'k1': [666], 'k2': [666]} v['k1'] = 777 print(v) # {'k1': 777, 'k2': [666]}
31、求结果: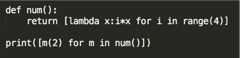
def num(): return [lambda x: i * x for i in range(4)] #返回一个列表,里面是四个函数对象 i=3 print([m(2) for m in num()])
32、列举常见的内置函数?
# map:遍历序列,为每一个序列进行操作,返回一个结果列表 l = [1, 2, 3, 4, 5, 6, 7] def pow2(x): return x * x res = map(pow2, l) print(list(res)) #[1, 4, 9, 16, 25, 36, 49] -------------------------------------------------------------- # reduce:对于序列里面的所有内容进行累计操作 from functools import reduce def add(x, y): return x+y print(reduce(add, [1,2,3,4])) #10 -------------------------------------------------------------- # filter:对序列里面的元素进行筛选,最终获取符合条件的序列。 l = [1, 2, 3, 4, 5] def is_odd(x): # 求奇数 return x % 2 == 1 print(list(filter(is_odd, l))) #[1, 3, 5] -------------------------------------------------------------- #zip用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表 a = [1,2,3] b=[4,5,6] c=[4,5,6,7,8] ziped1 = zip(a,b) print('ziped1>>>',list(ziped1)) #[(1, 4), (2, 5), (3, 6)] ziped2 = zip(a,c) print('ziped2>>>',list(ziped2)) #[(1, 4), (2, 5), (3, 6)],以短的为基准
33、filter、map、reduce的作用?
# map:遍历序列,为每一个序列进行操作,获取一个新的序列 # reduce:对于序列里面的所有内容进行累计操作 # filter:对序列里面的元素进行筛选,最终获取符合条件的序列。
34、一行代码实现9*9乘法表
print('\n'.join([' '.join(['%s*%s=%2s' % (j, i, i * j) for j in range(1, i + 1)]) for i in range(1, 10)]))
35、如何安装第三方模块?以及用过哪些第三方模块?
# a、可以在pycharm的settings里面手动下载添加第三方模块 # b、可以在cmd终端下用pip insatll 安装 # 用过的第三方模块:requests、pymysql、DBUtils等
36、至少列举8个常用模块都有那些?
re:正则
os:提供了一种方便的使用操作系统函数的方法。
sys:可供访问由解释器使用或维护的变量和与解释器进行交互的函数。
random:随机数
json:序列化
time:时间
37、re的match和search区别?
# match:从字符串起始位置开始匹配,如果没有就返回None # serch:从字符串的起始位置开始匹配,匹配到第一个符合的就不会再去匹配了
38、什么是正则的贪婪匹配?
# 匹配一个字符串没有节制,能匹配多少就匹配多少,直到匹配完为止
39、求结果: a. [ i % 2 for i in range(10) ] b. ( i % 2 for i in range(10) )
# a结果是一个列表生成式,结果是一个列表(i % 2为生成的元素): [0, 1, 0, 1, 0, 1, 0, 1, 0, 1] # b结果是一个生成器
40、求结果: a. 1 or 2 b. 1 and 2 c. 1 < (2==2) d. 1 < 2 == 2
a=1 or 2 #1 b=1 and 2 #2 c=1 < (2==2) #False d=1 < 2 == 2 #True
41、def func(a,b=[]) 这种写法有什么坑?
# 函数传参为列表陷阱,列表是可变数据类型,可能会在过程中修改里面的值
42、如何实现 “1,2,3” 变成 [‘1’,’2’,’3’] ?
a = '1,2,3' a=a.replace(',','') res = [i for i in a] print(res)
43、如何实现[‘1’,’2’,’3’]变成[1,2,3] ?
l = ['1','2','3'] res = [int(i) for i in l] print(res)
44、比较: a = [1,2,3] 和 b = [(1),(2),(3) ] 以及 b = [(1,),(2,),(3,) ] 的区别?
前两个列表内是int
最后一个列表内是元组
45、如何用一行代码生成[1,4,9,16,25,36,49,64,81,100] ?
l = [i*i for i in range(1,11)] print(l)
46、一行代码实现删除列表中重复的值 ?
l = [1,1,1,2,2,3,3,3,4,4] print(list(set(l))) # [1, 2, 3, 4]
47、如何在函数中设置一个全局变量 ?
通过global指定变量,该变量会变成全局变量
48、logging模块的作用?以及应用场景?
# 作用: 管理我们程序的执行日志,省去用print记录操作日志的操作,并且可以将标准输入输出保存到日志文件 # 场景: 爬虫爬取数据时,对爬取进行日志记录,方便分析、排错。
49、请用代码简单实现stack 。
class Stack(object): # 初始化栈 def __init__(self): self.items = [] # 判断栈是否为空 def is_empty(self): return self.items == [] # 返回栈顶 def peek(self): return self.items[len(self.items) - 1] # 返回栈大小 def size(self): return len(self.items) # 压栈 def push(self, item): self.items.append(item) # 出栈 def pop(self): return self.items.pop()
50、常用字符串格式化哪几种?
# %占位符 s = 'I am %s' %'zhugaochao' print(s) #I am zhugaochao # format格式化输出 i = "i am {}".format('zhugaochao') print(i) #i am zhugaochao
51、简述 生成器、迭代器、可迭代对象 以及应用场景?
# 装饰器: 能够在不修改原函数代码的基础上,在执行前后进行定制操作,闭包函数的一种应用 场景: - flask路由系统 - flask before_request - csrf - django内置认证 - django缓存 # 手写装饰器; import functools def wrapper(func): @functools.wraps(func) #不改变原函数属性 def inner(*args, **kwargs): 执行函数前 return func(*args, **kwargs) 执行函数后 return inner 1. 执行wapper函数,并将被装饰的函数当做参数。 wapper(index) 2. 将第一步的返回值,重新赋值给 新index = wapper(老index) @wrapper #index=wrapper(index) def index(x): return x+100 # --------------------------------------------------------------- # 生成器: 一个函数内部存在yield关键字 应用场景: - rang/xrange - redis获取值 - conn = Redis(......) - v=conn.hscan_iter() # 内部通过yield 来返回值 - stark组件中 - 前端调用后端的yield # --------------------------------------------------------------- # 迭代器: 内部有__next__和__iter__方法的对象,帮助我们向后一个一个取值,迭代器不一定是生成器 应用场景: - wtforms里面对form对象进行循环时,显示form中包含的所有字段 - 列表、字典、元组 (可以让一个对象被for循环)
52、用Python实现一个二分查找的函数。
li = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] def search(zhi,li,start=0,end=None): end = len(li) if end is None else end zj = (end - start) // 2+start if start<=end: if zhi>li[zj]: return search(3,li,start=zj+1,end=end) elif zhi<li[zj]: return search(3,li,start=start,end=zj-1) else: return zj return '找不到这个值' print(search(2,li))
53、谈谈你对闭包的理解?
# 闭包函数就是内部的函数调用外部函数的变量,常用于装饰器。 # 判断闭包函数的方法:__closure__,输出的__closure__有cell元素说明是闭包函数 # 闭包的意义与应用:延迟计算:
54、os和sys模块的作用?
# os模块负责程序与操作系统的交互,提供了访问操作系统底层的接口; # sys模块负责程序与python解释器的交互,提供了一系列的函数和变量,用于操控python运行环境
55、如何生成一个随机数?
import random print(random.random()) print(random.randint(1, 10))
56、如何使用python删除一个文件?
import os os.remove('文件名以及路径')
57、谈谈你对面向对象的理解?
#封装: 其实就是将很多数据封装到一个对象中,类似于把很多东西放到一个箱子中, 如:一个函数如果好多参数,起始就可以把参数封装到一个对象再传递。 #继承: 如果多个类中都有共同的方法,那么为了避免反复编写,就可以将方法提取到基类中实现, 让所有派生类去继承即可。 #多态: 指基类的同一个方法在不同派生类中有着不同功能。python天生支持多态。
58、Python面向对象中的继承有什么特点?
#Python3的继承机制 # 子类在调用某个方法或变量的时候,首先在自己内部查找,如果没有找到,则开始根据继承机制在父类里查找。 # 根据父类定义中的顺序,以深度优先的方式逐一查找父类! 继承参数的书写有先后顺序,写在前面的被优先继承。
59、面向对象深度优先和广度优先是什么?
# Python的类可以继承多个类,Python的类如果继承了多个类,那么其寻找方法的方式有两种 当类是经典类时,多继承情况下,会按照深度优先方式查找 当类是新式类时,多继承情况下,会按照广度优先方式查找 简单点说就是:经典类是纵向查找,新式类是横向查找 经典类和新式类的区别就是,在声明类的时候,新式类需要加上object关键字。在python3中默认全是新式类
60、面向对象中super的作用?
主要在子类继承父类的所有属性和方法时来使用
61、是否使用过functools中的函数?其作用是什么?
在装饰器中,会用到;functools.wraps()主要在装饰器中用来装饰函数 Stark上下文管理源码中,走到视图阶段时有用到functools中的偏函数,request = LocalProxy(partial(_lookup_req_object, 'request'))
62、列举面向对象中带爽下划线的特殊方法,如:__new__、__init__
# __getattr__ CBV django配置文件 wtforms中的Form()示例化中 将"_fields中的数据封装到From类中" # __mro__ wtform中 FormMeta中继承类的优先级 # __dict__ 是用来存储对象属性的一个字典,其键为属性名,值为属性的值 # __new__ 实例化但是没有给当前对象 wtforms,字段实例化时返回:不是StringField,而是UnboundField est frawork many=Turn 中的序列化 # __call__ flask 请求的入口app.run() 字段生成标签时:字段.__str__ => 字段.__call__ => 插件.__call__ # __iter__ 循环对象是,自定义__iter__ wtforms中BaseForm中循环所有字段时定义了__iter__ # -metaclass 作用:用于指定当前类使用哪个类来创建 场景:在类创建之前定制操作 示例:wtforms中,对字段进行排序。
63、如何判断是函数还是方法
# 看他的调用者是谁,如果是类,需要传入参数self,这时就是一个函数; # 如果调用者是对象,不需要传入参数值self,这时是一个方法。 (FunctionType/MethodType)
64、静态方法和类方法区别?
Classmethod必须有一个指向类对象的引用作为第一个参数; @classmethod def class_func(cls): """ 定义类方法,至少有一个cls参数 """ print('类方法') --------------------------------------------------------- Staticmethod可以没有任何参数。 @staticmethod def static_func(): """ 定义静态方法 ,无默认参数""" print('静态方法')
65、列举面向对象中的特殊成员以及应用场景
1. __doc__:表示类的描述信息。 2.__module__:表示当前操作的对象在那个模块; 3.__class__:表示当前操作的对象的类是什么。 4.__init__:构造方法,通过类创建对象时,自动触发执行。 5.__call__:对象后面加括号,触发执行。 6.__dict__:类或对象中的所有成员。 7.__str__:如果一个类中定义了__str__方法,那么在打印对象时,默认输出该方法的返回值。 class Foo: def __str__(self): return 'aaa' obj = Foo() print(obj) # 输出:aaa 8.__getitem__、__setitem__、__delitem__:用于索引操作,如字典。以上分别表示获取、设置、删除数据。 9.__iter__:用于迭代器,之所以列表、字典、元组可以进行for循环,是因为类型内部定义了 __iter__。
66、1、2、3、4、5 能组成多少个互不相同且无重复的三位数
import itertools print(len(list(itertools.permutations('12345',3)))) #60个
67、什么是反射?以及应用场景?
反射就是以字符串的方式导入模块,以字符串的方式执行函数 # 应用场景: rest framework里面的CBV
68、metaclass作用?以及应用场景?
类的metaclass
默认是type。我们也可以指定类的metaclass值。
参考:点击查看
69、用尽量多的方法实现单例模式。
# 单例模式 '''单例模式是一种常用的软件设计模式。在它的核心结构中只包含一个被称为单例类的特殊类。 通过单例模式可以保证系统中一个类只有一个实例而且该实例易于外界访问,从而方便对实例个数的控制并节约系统资源。 如果希望在系统中某个类的对象只能存在一个,单例模式是最好的解决方案。''' # 1、使用__new__方法 class Singleton(object): def __new__(cls, *args, **kw): if not hasattr(cls, '_instance'): orig = super(Singleton, cls) cls._instance = orig.__new__(cls, *args, **kw) return cls._instance class MyClass(Singleton): a = 1 # 2、共享属性 # 创建实例时把所有实例的__dict__指向同一个字典,这样它们具有相同的属性和方法. class Borg(object): _state = {} def __new__(cls, *args, **kw): ob = super(Borg, cls).__new__(cls, *args, **kw) ob.__dict__ = cls._state return ob class MyClass2(Borg): a = 1 # 3、装饰器版本 def singleton(cls, *args, **kw): instances = {} def getinstance(): if cls not in instances: instances[cls] = cls(*args, **kw) return instances[cls] return getinstance @singleton class MyClass: ... # 4、import方法 # 作为python的模块是天然的单例模式 # mysingleton.py class My_Singleton(object): def foo(self): pass my_singleton = My_Singleton() # to use from mysingleton import my_singleton my_singleton.foo()
70、装饰器的写法以及应用场景。
import functools def wrapper(func): @functools.wraps(func) def inner(*args, **kwargs): print('我是装饰器') return func return inner @wrapper def index(): print('我是被装饰函数') return None index() # 应用场景 - 高阶函数 - 闭包 - 装饰器 - functools.wraps(func)
71、异常处理写法以及如何主动抛出异常(应用场景)
while True: try: x = int(input("Please enter a number: ")) break except ValueError: print("Oops! That was no valid number. Try again ") # raise主动抛出一个异常 参考:点击查看
72、什么是面向对象的mro
MRO:方法解析顺序
它定义了 Python 中多继承存在的情况下,解释器查找继承关系的具体顺序
73、isinstance作用以及应用场景?
# 来判断一个对象是否是一个已知的类型。 # 使用isinstance函数还可以来判断'类实例变量'属于哪一个类产生的。
74、写代码并实现:
Given an array of integers, return indices of the two numbers such that they add up to a specific target.You may assume that each input would have exactly one solution, and you may not use the same element twice.Example: Given nums = [2, 7, 11, 15], target = 9, Because nums[0] + nums[1] = 2 + 7 = 9, return [0, 1]
'''Given an array of integers, return indices of the two numbers such that they add up to a specific target.You may assume that each input would have exactly one solution, and you may not use the same element twice. Example: Given nums = [2, 7, 11, 15], target = 9, Because nums[0] + nums[1] = 2 + 7 = 9, return [0, 1]''' class Solution: def twoSum(self, nums, target): """ :type nums: List[int] :type target: int :rtype: List[int] """ # 用len()方法取得nums列表长度 n = len(nums) # x从0到n取值(不包括n) for x in range(n): a = target - nums[x] # 用in关键字查询nums列表中是否有a if a in nums: # 用index函数取得a的值在nums列表中的索引 y = nums.index(a) # 假如x=y,那么就跳过,否则返回x,y if x == y: continue else: return x, y break else: continue
75、json序列化时,可以处理的数据类型有哪些?如何定制支持datetime类型?
# 可序列化数据类型: 字典、列表、数字、字符串、元组;如果是元组,自动转成列表(再转回去的话也是列表) # 自定义时间序列化转换器 import json from json import JSONEncoder from datetime import datetime class ComplexEncoder(JSONEncoder): def default(self, obj): if isinstance(obj, datetime): return obj.strftime('%Y-%m-%d %H:%M:%S') else: return super(ComplexEncoder,self).default(obj) d = { 'name':'alex','data':datetime.now()} print(json.dumps(d,cls=ComplexEncoder)) # {"name": "alex", "data": "2018-05-18 19:52:05"}
76、json序列化时,默认遇到中文会转换成unicode,如果想要保留中文怎么办?
import json a=json.dumps({"xxx":"你好"},ensure_ascii=False) print(a) #{"xxx": "你好"}
77、什么是断言?应用场景?
#条件成立则继续往下,否则抛出异常; #一般用于:满足某个条件之后,才能执行,否则应该抛出异常。 '应用场景':rest framework中GenericAPIView类里,要设置queryset,否则断言错误
78、有用过with statement吗?它的好处是什么?
with语句适用于对资源进行访问的场合,确保不管使用过程中是否发生异常都会执行必要的“清理”操作,
释放资源,比如文件使用后自动关闭、线程中锁的自动获取和释放等。
79、使用代码实现查看列举目录下的所有文件。
import os path = os.listdir('.') #查看列举目录下的所有文件。 # path = os.listdir(os.getcwd()) print(path)
80、简述 yield和yield from关键字。
1、yield使用 1)函数中使用yield,可以使函数变成生成器。一个函数如果是生成一个数组,就必须把数据存储在内存中,如果使用生成器,则在调用的时候才生成数据,可以节省内存。 2)生成器方法调用时,不会立即执行。需要调用next()或者使用for循环来执行。 2、yield from的使用 1)为了让生成器(带yield函数),能简易的在其他函数中直接调用,就产生了yield from。 参考:点击查看
第二部分 网络编程和并发(34题)
1、简述 OSI 七层协议。
物理层:主要基于电器特性发送高低电压(1、0),设备有集线器、中继器、双绞线等,单位:bit
数据链路层:定义了电信号的分组方式,设备:交换机、网卡、网桥,单位:帧
网络层:主要功能是将网络地址翻译成对应屋里地址,设备:路由
传输层:建立端口之间的通信,tcp、udp协议
会话层:建立客户端与服务端连接
表示层:对来自应用层的命令和数据进行解释,按照一定格式传给会话层。如编码、数据格式转换、加密解密、压缩解压
应用层:规定应用程序的数据格式
2、什么是C/S和B/S架构?
#C/S架构: client端与server端的服务架构 #B/S架构: 隶属于C/S架构,Broswer端(网页端)与server端; 优点:统一了所有应用的入口,方便、轻量级
3、简述 三次握手、四次挥手的流程。
#三次握手: 1.客户端(Client)向服务端(Server)发送一次请求 2.服务端确认并回复客户端 3.客户端检验确认请求,建立连接 #四次挥手: 1.客户端向服务端发一次请求 2.服务端回复客户端(断开客户端-->服务端) 3.服务端再次向客户端发请求(告诉客户端可以断开了) 4.客户端确认请求,连接断开
4、什么是arp协议?
#ARP(地址解析协议) 其主要用作将IP地址翻译为以太网的MAC地址 #在局域网中,网络中实际传输的是“帧”,帧里面是有目标主机的MAC地址的。 #在以太网中,一个主机要和另一个主机进行直接通信,必须要知道目标主机的MAC地址。 #所谓“地址解析”就是主机在发送帧前将目标IP地址转换成目标MAC地址的过程。 #ARP协议的基本功能就是通过目标设备的IP地址,查询目标设备的MAC地址,以保证通信的顺利进行。
5、TCP和UDP的区别?
#TCP协议:面向连接 - 通信之前先三次握手 - 断开之前先四次握手 - 必须先启动服务端,再启动客户端-->连接服务端 - 安全、可靠、面向连接(不会丢包) #UDP协议:无连接 - 传输速度快 - 先启动哪一端都可以 - 不面向连接,不能保证数据的完整性(如:QQ聊天)
6、什么是局域网和广域网?
局域网和广域网是按规模大小而划分的两种计算机网络。 #范围在几千米以内的计算机网络统称为局域网(LAN、私网、内网); #而连接的范围超过10千米的,则称为广域网,因特网(Intenet)就是目前最大的广域网(WAN、公网、外网)。
7、为何基于tcp协议的通信比基于udp协议的通信更可靠?
因为TCP是面向连接的
通信之前先三次握手,通过握手,确保连接成功之后再通信
断开之前先四次挥手;双方互相确认之后再断开连接,这样一来保证了数据的安全、可靠,避免丢包
8、什么是socket?简述基于tcp协议的套接字通信流程。
#服务端: 创建套接字 绑定IP和端口 监听 accept等待连接 通信(收recv、发send) #客户端: 创建套接字 绑定IP和端口 链接服务器 通信(收revc、发send)
9、什么是粘包? socket 中造成粘包的原因是什么? 哪些情况会发生粘包现象?
粘包:数据粘在一起,主要因为:接收方不知道消息之间的界限,不知道一次性提取多少字节的数据造成的
数据量比较小,时间间隔比较短,就合并成了一个包,这是底层的一个优化算法(Nagle算法)
10、IO多路复用的作用?
# IO多路复用分为时间上的复用和空间上的复用, # 空间上的复用是指将内存分为几部分,每一部分放一个程序,这样同一时间内存中就有多道程序; # 时间上的复用是指多个程序需要在一个cpu上运行,不同的程序轮流使用cpu, # 当某个程序运行的时间过长或者遇到I/O阻塞,操作系统会把cpu分配给下一个程序, # 保证cpu处于高使用率,实现伪并发。
11、什么是防火墙以及作用?
# 什么是防火墙? 防火墙是一个分离器,一个限制器,也是一个分析器, 有效地监控了内部网和Internet之间的任何活动,保证了内部网络的安全。 # 作用 防火墙可通过监测、限制、更改跨越防火墙的数据流, 尽可能地对外部屏蔽网络内部的信息、结构和运行状况,以此来实现网络的安全保护。
12、select、poll、epoll 模型的区别?
# select本质上是通过设置或者检查存放fd标志位的数据结构来进行下一步处理。这样所带来的缺点是: # 1.单个进程可监视的fd数量被限制 # 2.需要维护一个用来存放大量fd的数据结构 # 这样会使得用户空间和内核空间在传递该结构时复制开销大 # 3.对socket进行扫描时是线性扫描 # poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间, # 它没有最大连接数的限制,原因是它是基于链表来存储的但是同样有一个缺点: # 大量的fd的数组被整体复制于用户态和内核地址空间之间,而不管这样的复制是不是有意义。 # epoll支持水平触发和边缘触发,最大的特点在于边缘触发, # 它只告诉进程哪些fd刚刚变为就需态,并且只会通知一次。
13、简述 进程、线程、协程的区别 以及应用场景?
# 进程 进程拥有自己独立的堆和栈,既不共享堆,亦不共享栈,进程由操作系统调度。 # 线程 线程拥有自己独立的栈和共享的堆,共享堆,不共享栈,线程亦由操作系统调度 # 协程和线程的区别 协程避免了无意义的调度,由此可以提高性能;但同时协程也失去了线程使用多CPU的能力。
14、GIL锁是什么鬼?
# GIL 线程全局锁(Global Interpreter Lock),即Python为了保证线程安全而采取的独立线程运行的限制,说白了就是一个核只能在同一时间运行一个线程. 对于io密集型任务,python的多线程起到作用,但对于cpu密集型任务, python的多线程几乎占不到任何优势,还有可能因为争夺资源而变慢。 解决办法就是多进程和下面的协程(协程也只是单CPU,但是能减小切换代价提升性能).
15、Python中如何使用线程池和进程池?
进程池:就是在一个进程内控制一定个数的线程
基于concurent.future模块的进程池和线程池 (他们的同步执行和异步执行是一样的)
参考:点击查看
16、threading.local的作用?
a.threading.local 作用:为每个线程开辟一块空间进行数据存储。 问题:自己通过字典创建一个类似于threading.local的东西。 storage = { 4740: {val: 0}, 4732: {val: 1}, 4731: {val: 3}, } b.自定义Local对象 作用:为每个线程(协程) 开辟一块空间进行数据存储。 try: from greenlet import getcurrent as get_ident except Exception as e: from threading import get_ident from threading import Thread import time class Local(object): def __init__(self): object.__setattr__(self, 'storage', {}) def __setattr__(self, k, v): ident = get_ident() if ident in self.storage: self.storage[ident][k] = v else: self.storage[ident] = {k: v} def __getattr__(self, k): ident = get_ident() return self.storage[ident][k] obj = Local() def task(arg): obj.val = arg obj.xxx = arg print(obj.val) for i in range(10): t = Thread(target=task, args=(i,)) t.start()
17、进程之间如何进行通信?
# 进程间通讯有多种方式,包括信号,管道,消息队列,信号量,共享内存,socket等
18、什么是并发和并行?
# 并发:同一时刻只能处理一个任务,但一个时段内可以对多个任务进行交替处理(一个处理器同时处理多个任务) # 并行:同一时刻可以处理多个任务(多个处理器或者是多核的处理器同时处理多个不同的任务) # 类比:并发是一个人同时吃三个馒头,而并行是三个人同时吃三个馒头。
19、进程锁和线程锁的作用?
线程锁: 大家都不陌生,主要用来给方法、代码块加锁。当某个方法或者代码块使用锁时,那么在同一时刻至多仅有有一个线程在执行该段代码。当有多个线程访问同一对象的加锁方法 / 代码块时,同一时间只有一个线程在执行,其余线程必须要等待当前线程执行完之后才能执行该代码段。但是,其余线程是可以访问该对象中的非加锁代码块的。
进程锁: 也是为了控制同一操作系统中多个进程访问一个共享资源,只是因为程序的独立性,各个进程是无法控制其他进程对资源的访问的,但是可以使用本地系统的信号量控制(操作系统基本知识)。
分布式锁: 当多个进程不在同一个系统之中时,使用分布式锁控制多个进程对资源的访问。
参考:点击查看
20、解释什么是异步非阻塞?
'非阻塞': 遇到IO阻塞不等待(setblooking=False),(可能会报错->捕捉异常) - sk=socket.socket() - sk.setblooking(False) '异步': 回调(ajax),当达到某个指定状态之后,自动调用特定函数
21、路由器和交换机的区别?
'交换机' 用于在同一网络内数据快速传输转发,工作在数据链路层; 通过MAC寻址,不能动态划分子网; 只能在一条网络通路中运行,不能动态分配。 '路由器' 是一个网关设备,内部局域网到公网的一个关卡; 工作在网络层; 通过IP寻址,可以划分子网; 可以在多条网络通道中运行,可以动态分配IP地址。 '简单说' 交换机就是把一根网线变成多根网线; 路由器就是把一个网络变成多个网络; 如果不上外网,只是局域网,交换机即可; 如果上外网,并且给网络划分不同网段,就必须用路由器。
22、什么是域名解析?
# 在网上,所有的地址都是ip地址,但这些ip地址太难记了,所以就出现了域名(比如http://baidu.com)。 # 而域名解析就是将域名,转换为ip地址的这样一种行为。 # 例如:访问www.baidu.com,实质是把域名解析成IP。
23、如何修改本地hosts文件?
'hosts': Hosts就是将一些常用的网址域名与其对应的IP地址建立一个关联“数据库” 可以用来屏蔽一些网站,或者指定一些网站(修改hostsFQ) '修改': # windows: 位置:C:\Windows\System32\drivers\etc 也可以通过第三方软件,我用的火绒,可以直接进行编辑hosts # linux: 位置:/etc/hosts 修改:vi /etc/hosts
24、生产者消费者模型应用场景及优势?
# 处理数据比较消耗时间,线程独占,生产数据不需要即时的反馈等。
25、什么是cdn?
# 用户获取数据时,不需要直接从源站获取,通过CDN对于数据的分发, # 用户可以从一个较优的服务器获取数据,从而达到快速访问,并减少源站负载压力的目的。
26、LVS是什么及作用?
# LVS即Linux虚拟服务器,是一个虚拟的四层交换器集群系统, # 根据目标地址和目标端口实现用户请求转发,本身不产生流量,只做用户请求转发。
27、Nginx是什么及作用?
28、keepalived是什么及作用?
Keepalived是Linux下一个轻量级别的高可用解决方案。
高可用,其实两种不同的含义:广义来讲,是指整个系统的高可用行,狭义的来讲就是之主机的冗余和接管,
参考:点击查看
29、haproxy是什么以及作用?
HAProxy提供高可用性、负载均衡以及基于TCP和HTTP应用的代 理,支持虚拟主机,它是免费、快速并且可靠的一种解决方案。
HAProxy特别适用于那些负载特大的web站点,这些站点通常又需要会话保持或七层处理。HAProxy运行在当前的硬件上,
完全可以支持数以万计的并发连接。并且它的运行模式使得它可以很简单安全的整合进您当前的架中,
同时可以保护你的web服务器不被暴露到网络上。
参考:点击查看
30、什么是负载均衡?
负载均衡有两方面的含义: # 首先,大量的并发访问或数据流量分担到多台节点设备上分别处理,减少用户等待响应的时间; # 其次,单个重负载的运算分担到多台节点设备上做并行处理,每个节点设备处理结束后, 将结果汇总,返回给用户,系统处理能力得到大幅度提高。
31、什么是rpc及应用场景?
RPC 的全称是 Remote Procedure Call 是一种进程间通信方式。
它允许程序调用另一个地址空间(通常是共享网络的另一台机器上)的过程或函数,而不用程序员显式编码这个远程调用的细节。
即程序员无论是调用本地的还是远程的,本质上编写的调用代码基本相同
(例如QQ远程操作)
参考:点击查看
32、简述 asynio模块的作用和应用场景。
asyncio是Python 3.4版本引入的标准库,直接内置了对异步IO的支持。
asyncio的异步操作,需要在coroutine中通过yield from完成。
参考:点击查看
33、简述 gevent模块的作用和应用场景。
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,
在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。
Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
参考:点击查看
34、twisted框架的使用和应用?
Twisted是一个事件驱动型的网络模型。
时间驱动模型编程是一种范式,这里程序的执行流由外部决定。
特点是:包含一个事件循环,当外部事件发生时,使用回调机制来触发相应的处理。
参考:点击查看
第三部分 数据库和缓存(46题)
1、列举常见的关系型数据库和非关系型都有那些?
'关系型': # sqllite、db2、oracle、access、SQLserver、MySQL # 注意:sql语句通用,需要有表结构 '非关系型': # mongodb、redis、memcache # 非关系型数据库是key-value存储的,没有表结构。
2、MySQL常见数据库引擎及比较?
'Myisam': # 支持全文索引 # 查询速度相对较快 # 支持表锁 # 表锁:select * from tb for update;(锁:for update) 'InnoDB': # 支持事务 # 支持行锁、表锁 # 表锁:select * from tb for update;(锁:for update) # 行锁: select id ,name from tb where id=2 for update;(锁:for update)
3、简述数据三大范式?
# 数据库的三大特性: '实体':表 '属性':表中的数据(字段) '关系':表与表之间的关系 ---------------------------------------------------- # 数据库设计三大范式: '第一范式(1NF)' 数据表中的每一列(每个字段),必须是不可拆分的最小单元 也就是确保每一列的原子性。 '第二范式(2NF)' 满足第一范式后(1NF),要求表中的所有列,都必须依赖于主键, 而不能有任何一列 与主键没有关系,也就是说一个表只描述一件事。 '第三范式(3NF)' 必须先满足第二范式(2NF) 要求:表中每一列只与主键直接相关而不是间接相关(表中每一列只能依赖于主键)
4、什么是事务?MySQL如何支持事务?
'什么是事务' 事务由一个或多个sql语句组成一个整体; 在事务中的操作,要么都执行修改,要么都不执行, 只有在该事务中所有的语句都执行成功才会将修改加入到数据库中,否则回滚到上一步。 'Mysql实现事务' InnoDB支持事务,MyISAM不支持 # 启动事务: # start transaction; # update from account set money=money-100 where name='a'; # update from account set money=money+100 where name='b'; # commit; 'start transaction 手动开启事务,commit 手动关闭事务'
5、数据库五大约束
'数据库五大约束' 1.primary KEY:设置主键约束; 2.UNIQUE:设置唯一性约束,不能有重复值; 3.DEFAULT 默认值约束 4.NOT NULL:设置非空约束,该字段不能为空; 5.FOREIGN key :设置外键约束。
6、简述数据库设计中一对多和多对多的应用场景?
# 一对一关系示例: 一个学生对应一个学生档案材料,或者每个人都有唯一的身份证编号。 # 一对多关系示例:(下拉单选) 一个学生只属于一个班,但是一个班级有多名学生。 # 多对多关系示例:(下拉多选) 一个学生可以选择多门课,一门课也有多名学生。
7、如何基于数据库实现商城商品计数器?
参考:点击查看
8、常见SQL(必备)
详见:点击查看
9、简述触发器、函数、视图、存储过程?
'触发器': 对数据库某个表进行【增、删、改】前后,自定义的一些SQL操作 '函数': 在SQL语句中使用的函数 #例如:select sleep(2) 聚合函数:max、sam、min、avg 时间格式化:date_format 字符串拼接:concat 自定制函数:(触发函数通过 select) '视图': 对某些表进行SQL查询,将结果实时显示出来(是虚拟表),只能查询不能更新 '存储过程': 将提前定义好的SQL语句保存到数据库中并命名;以后在代码中调用时直接通过名称即可 参数类型:in、out、inout
10、MySQL索引种类
'主键索引(单列)': primary key 加速查找+约束:不能重复、不能为空 '普通索引(单列)': 加速查找 '唯一索引(单列)': unique 加速查找+约束:不能重复 '联合索引(多列)': 查询时根据多列进行查询(最左前缀) '联合唯一索引(多列)': 遵循最左前缀规则(命中索引) # 其他词语 1、索引合并:利用多个单列索引查询 2、覆盖索引:在索引表中就能将想要的数据查询到
11、索引在什么情况下遵循最左前缀的规则?
你可以认为联合索引是闯关游戏的设计 例如你这个联合索引是state/city/zipCode 那么state就是第一关 city是第二关, zipCode就是第三关 你必须匹配了第一关,才能匹配第二关,匹配了第一关和第二关,才能匹配第三关 你不能直接到第二关的 索引的格式就是第一层是state,第二层才是city 参考:点击查看
12、主键和外键的区别?
'主键' 唯一标识一条记录 用来保证数据的完整性 主键只能有一个 '外键' 表的外键是另一个表的主键,外键可以有重复的,可以是空值 用来和其他表建立联系用的 一个表可以有多个外键 '索引' 该字段没有重复值,但可以有一个空值 提高查询速度 一个表可以有多个唯一索引
13、MySQL常见的函数?
'当前时间' select now(); '时间格式化' select DATE_FORMAT(NOW(), '%Y(年)-%m(月)-%d(日) %H(时):%i(分):%s(秒)') '日期加减' select DATE_ADD(DATE, INTERVAL expr unit) select DATE_ADD(NOW(), INTERVAL 1 DAY) #当前日期加一天 \expr:正数(加)、负数(减) \unit:支持毫秒microsecond、秒second、小时hour、天day、周week、年year '类型转换' cast( expr AS TYPE) select CAST(123 AS CHAR) '字符串拼接' concat(str1,str2,……) select concat('hello','2','world') --> hellow2world '聚合函数' avg() #平均值 count() #返回指定列/行的个数 min() #最小值 max() #最大值 sum() #求和 group_concat() #返回属于一组的列值,连接组合而成的结果 '数学函数' abs() #绝对值 bin() #二进制 rand() #随机数
14、列举 创建索引但是无法命中索引的8种情况。
#使用'like ‘%xx’' select * from tb1 where name like '%cn'; #使用'函数' select * from tb1 where reverse(name)='zgc'; #使用'or' select * from tb1 where nid=1 or email='zgc@gmial.com'; 特别的:当or条件中有未建立索引的列才失效,一下会走索引 # select * from tb1 where nid=1 or name='zgc'; # select * from tb1 where nid=1 or email='zgc@gmial.com' and name='zgc'; #'类型不一致' 如果列是字符串类型,传入条件是必须用引号引起来,不然则可能会无法命中 select * from tb1 where name=666; #含有'!= ' select * from tb1 where name != 'zgc'; 特别的:如果是主键,还是会走索引 # select * from tb1 where nid != 123; #含有'>' select * from tb1 where name > 'zgc'; 特别的:如果是主键或者索引是整数类型,则还是会走索引 # select * from tb1 where nid > 123; # select * from tb1 where name > 123; #含有'order by' select email from tb1 order by name desc; 当根据索引排序时,选择的映射如果不是索引,则不走索引 特别的:如果对主键排序,则还是走索引: # select * from tb1 order by nid desc; #组合索引最左前缀 如果组合索引为:(name,email) name and email #使用索引 name #使用索引 email #不使用索引
15、如何开启慢日志查询?
'可以通过修改配置文件开启' slow_query_log=ON #是否开启慢日志记录 long_query_time=2 #时间限制,超过此时间,则记录 slow_query_log_file=/usr/slow.log #日志文件 long_queries_not_using_indexes=ON #是否记录使用索引的搜索
16、数据库导入导出命令(结构+数据)?
#导出: mysqldump --no-defaults -uroot -p 数据库名字 > 导出路径 '--no-defaults':解决“unknown option --no-beep”报错 #导入: 1、mysqldump -uroot -p 数据库名称 < 路径 2、进入数据库; source + 要导入数据库文件路径
17、数据库优化方案?
1、创建数据表时把固定长度的放在前面 2、将固定数据放入内存:choice字段(django中用到,1,2,3对应相应内容) 3、char不可变,varchar可变 4、联合索引遵循最左前缀(从最左侧开始检索) 5、避免使用 select * 6、读写分离: #利用数据库的主从分离:主,用于删除、修改、更新;从,用于查 #实现:两台服务器同步数据 \原生SQL:select * from db.tb \ORM:model.User.object.all().using('default') \路由:db router 7、分库 # 当数据库中的表太多,将某些表分到不同数据库,例如:1W张表时 # 代价:连表查询跨数据库,代码变多 8、分表 # 水平分表:将某些列拆分到另一张表,例如:博客+博客详情 # 垂直分表:将某些历史信息,分到另外一张表中,例如:支付宝账单 9、加缓存 # 利用redis、memcache(常用数据放到缓存里,提高取数据速度) # 缓存不够可能会造成雪崩现象 10、如果只想获取一条数据 select * from tb where name = 'zgc' limit 1;
18、char和varchar的区别?
#char类型:定长不可变 存入字符长度大于设置长度时报错; 存入字符串长度小于设置长度时,用空格填充以达到设置字符串长度; 简单粗暴,浪费空间,存取速度快。 #varchar类型:可变 存储数据真实内容,不使用空格填充; 会在真实数据前加1-2Bytes的前缀,用来表示真实数据的bytes字节数; 边长、精准、节省空间、存取速度慢。
19、简述MySQL的执行计划?
# explain + SQL语句 # SQL在数据库中执行时的表现情况,通常用于SQL性能分析,优化等场景。 'explain select * from rbac_userinfo where id=1;'
20、在对name做了唯一索引前提下,简述以下区别:
select * from tb where name = ‘小明’ select * from tb where name = ‘小明’ limit 1 ------------------------------------------------------------- 没做唯一索引的话,前者查询会全表扫描,效率低些 limit 1,只要找到对应一条数据,就不继续往下扫描. 然而 name 字段添加唯一索引了,加不加limit 1,意义都不大;
21、1000w条数据,使用limit offset 分页时,为什么越往后翻越慢?如何解决?
# 例如: #limit 100000,20; 从第十万条开始往后取二十条, #limit 20 offset 100000; limit后面是取20条数据,offset后面是从第10W条数据开始读 因为当一个数据库表过于庞大,LIMIT offset, length中的offset值过大,则SQL查询语句会非常缓慢 -------------------------------------------------------------------------- '优化一' 先查看主键,再分页: select * from tb where id in (select id from tb where limit 10 offset 30) -------------------------------------------------------------------------- '优化二' 记录当前页,数据、ID、最大值和最小值(用于where查询) 在翻页时,根据条件进行筛选,筛选完毕后,再根据 limit offset 查询 select * from(select * from tb where id > 2222) as B limit 10 offset 0; \如果用户自己修改页码,也可能导致变慢,此时可以对 url 页码进行加密,例如rest framework -------------------------------------------------------------------------- '优化三' 可以按照当前业务需求,看是否可以设置只允许看前200页; 一般情况下,没人会咔咔看个几十上百页的;
22、什么是索引合并?
# 索引合并访问方法可以在查询中对一个表使用多个索引,对它们同时扫描,并且合并结果。 # 此访问方法合并来自单个表的索引扫描; 它不会将扫描合并到多个表中。
23、什么是覆盖索引?
# 解释一: 就是select的数据列只用从索引中就能够取得,不必从数据表中读取,换句话说查询列要被所使用的索引覆盖。 # 解释二: 索引是高效找到行的一个方法,当能通过检索索引就可以读取想要的数据,那就不需要再到数据表中读取行了。 如果一个索引包含了(或覆盖了)满足查询语句中字段与条件的数据就叫做覆盖索引。 # 注意:MySQL只能使用B-Tree索引做覆盖索引
24、简述数据库读写分离?
#利用数据库的主从分离:主,用于删除、修改、更新;从,用于查 #实现:两台服务器同步数据(减轻服务器的压力) 原生SQL: select * from db.tb ORM:model.User.object.all().using('default') 路由:db router
25、简述数据库分库分表?(水平、垂直)
# 1、分库 当数据库中的表太多,将某些表分到不同数据库,例如:1W张表时 代价:连表查询跨数据库,代码变多 # 2、分表 水平分表:将某些列拆分到另一张表,例如:博客+博客详情 垂直分表:将某些历史信息,分到另外一张表中,例如:支付宝账单
26、redis和memcached比较?
# 1.存储容量: memcached超过内存比例会抹掉前面的数据,而redis会存储在磁盘 # 2.支持数据类型: memcached只支持string; redis支持更多;如:hash、list、集合、有序集合 # 3.持久化: redis支持数据持久化,可以将内存中的数据保持在磁盘中,memcached无 # 4.主从: 即master-slave模式的数据备份(主从)。 # 5.特性 Redis在很多方面具备数据库的特征,或者说就是一个数据库系统 Memcached只是简单的K/V缓存
27、redis中数据库默认是多少个db 及作用?
#redis默认有16个db,db0~db15(可以通过配置文件支持更多,无上限) #并且每个数据库的数据是隔离的不能共享 #可以随时使用SELECT命令更换数据库:redis> SELECT 1 # 注意: 多个数据库之间并不是完全隔离的 比如FLUSHALL命令可以清空一个Redis实例中所有数据库中的数据。
28、python操作redis的模块?
参考:点击查看
29、如果redis中的某个列表中的数据量非常大,如果实现循环显示每一个值?
# 通过scan_iter分片取,减少内存压力 scan_iter(match=None, count=None)增量式迭代获取redis里匹配的的值 # match,匹配指定key # count,每次分片最少获取个数 r = redis.Redis(connection_pool=pool) for key in r.scan_iter(match='PREFIX_*', count=100000): print(key)
30、redis如何实现主从复制?以及数据同步机制?
# 实现主从复制 '创建6379和6380配置文件' redis.conf:6379为默认配置文件,作为Master服务配置; redis_6380.conf:6380为同步配置,作为Slave服务配置; '配置slaveof同步指令' 在Slave对应的conf配置文件中,添加以下内容: slaveof 127.0.0.1 6379 # 数据同步步骤: (1)Slave服务器连接到Master服务器. (2)Slave服务器发送同步(SYCN)命令. (3)Master服务器备份数据库到文件. (4)Master服务器把备份文件传输给Slave服务器. (5)Slave服务器把备份文件数据导入到数据库中.
31、redis中的sentinel的作用?
# 帮助我们自动在主从之间进行切换(哨兵) # 检测主从中 主是否挂掉,且超过一半的sentinel检测到挂了之后才进行进行切换。 # 如果主修复好了,再次启动时候,会变成从。
32、如何实现redis集群?
#基于【分片】来完成。 - 集群是将你的数据拆分到多个Redis实例的过程 - 可以使用很多电脑的内存总和来支持更大的数据库。 - 没有分片,你就被局限于单机能支持的内存容量。 #redis将所有能放置数据的地方创建了 16384 个哈希槽。 #如果设置集群的话,就可以为每个实例分配哈希槽: - 192.168.1.20【0-5000】 - 192.168.1.21【5001-10000】 - 192.168.1.22【10001-16384】 #以后想要在redis中写值时:set k1 123 - 将k1通过crc16的算法转换成一个数字,然后再将该数字和16384求余, - 如果得到的余数 3000,那么就将该值写入到 192.168.1.20 实例中。 #集群方案: - redis cluster:官方提供的集群方案。 - codis:豌豆荚技术团队。 - tweproxy:Twiter技术团队。
33、redis中默认有多少个哈希槽?
#redis中默认有 16384 个哈希槽。
34、简述redis的有哪几种持久化策略及比较?
#RDB:每隔一段时间对redis进行一次持久化。 - 缺点:数据不完整 - 优点:速度快 #AOF:把所有命令保存起来,如果想重新生成到redis,那么就要把命令重新执行一次。 - 缺点:速度慢,文件比较大 - 优点:数据完整
35、列举redis支持的过期策略。
# 数据集(server.db[i].expires) a、voltile-lru: #从已设置过期时间的数据集中,挑选最近频率最少数据淘汰 b、volatile-ttl: #从已设置过期时间的数据集中,挑选将要过期的数据淘汰 c、volatile-random:#从已设置过期时间的数据集中,任意选择数据淘汰 d、allkeys-lru: #从数据集中,挑选最近最少使用的数据淘汰 e、allkeys-random: #从数据集中,任意选择数据淘汰 f、no-enviction(驱逐):#禁止驱逐数据
36、MySQL 里有 2000w 数据,redis 中只存 20w 的数据,如何保证 redis 中都是热点数据?
# 限定Redis占用的内存,根据自身数据淘汰策略,淘汰冷数据,把热数据加载到内存。 # 计算一下 20W 数据大约占用的内存,然后设置一下Redis内存限制即可。
37、写代码,基于redis的列表实现 先进先出、后进先出队列、优先级队列。???????????????????
38、如何基于redis实现消息队列?
# 通过发布订阅模式的PUB、SUB实现消息队列 # 发布者发布消息到频道了,频道就是一个消息队列。 # 发布者: import redis conn = redis.Redis(host='127.0.0.1',port=6379) conn.publish('104.9MH', "hahahahahaha") # 订阅者: import redis conn = redis.Redis(host='127.0.0.1',port=6379) pub = conn.pubsub() pub.subscribe('104.9MH') while True: msg= pub.parse_response() print(msg) 对了,redis 做消息队列不合适 业务上避免过度复用一个redis,用它做缓存、做计算,还做任务队列,压力太大,不好。
39、如何基于redis实现发布和订阅?以及发布订阅和消息队列的区别?
# 发布和订阅,只要有任务就所有订阅者每人一份。 发布者: #发布一次 import redis conn = redis.Redis(host='127.0.0.1',port=6379) conn.publish('104.9MH', "hahahahahaha") 订阅者: #'while True'一直在接收 import redis conn = redis.Redis(host='127.0.0.1',port=6379) pub = conn.pubsub() pub.subscribe('104.9MH') while True: msg= pub.parse_response() print(msg)
40、什么是codis及作用?
Codis 是一个分布式 Redis 解决方案, 对于上层的应用来说, 连接到 Codis-Proxy(redis代理服务)和连接原生的 Redis-Server 没有明显的区别, 上层应用可以像使用单机的 Redis 一样使用, Codis 底层会处理请求的转发, 不停机的数据迁移等工作, 所有后边的一切事情, 对于前面的客户端来说是透明的, 可以简单的认为后边连接的是一个内存无限大的 Redis 服务.
41、什么是twemproxy及作用?
# 什么是Twemproxy 是Twtter开源的一个 Redis 和 Memcache 代理服务器, 主要用于管理 Redis 和 Memcached 集群,减少与Cache服务器直接连接的数量。 他的后端是多台REDIS或memcached所以也可以被称为分布式中间件。 # 作用 通过代理的方式减少缓存服务器的连接数。 自动在多台缓存服务器间共享数据。 通过配置的方式禁用失败的结点。 运行在多个实例上,客户端可以连接到首个可用的代理服务器。 支持请求的流式与批处理,因而能够降低来回的消耗。
42、写代码实现redis事务操作。
import redis pool = redis.ConnectionPool(host='10.211.55.4', port=6379) conn = redis.Redis(connection_pool=pool) # pipe = r.pipeline(transaction=False) pipe = conn.pipeline(transaction=True) # 开始事务 pipe.multi() pipe.set('name', 'zgc') pipe.set('role', 'haha') pipe.lpush('roless', 'haha') # 提交 pipe.execute() '注意':咨询是否当前分布式redis是否支持事务
43、redis中的watch的命令的作用?
# 用于监视一个或多个key # 如果在事务执行之前这个/些key被其他命令改动,那么事务将被打断
44、基于redis如何实现商城商品数量计数器?
'通过redis的watch实现' import redis conn = redis.Redis(host='127.0.0.1',port=6379) # conn.set('count',1000) val = conn.get('count') print(val) with conn.pipeline(transaction=True) as pipe: # 先监视,自己的值没有被修改过 conn.watch('count') # 事务开始 pipe.multi() old_count = conn.get('count') count = int(old_count) print('现在剩余的商品有:%s',count) input("问媳妇让不让买?") pipe.set('count', count - 1) # 执行,把所有命令一次性推送过去 pipe.execute() 数据库的锁
45、简述redis分布式锁和redlock的实现机制。
# redis分布式锁? # 不是单机操作,又多了一/多台机器 # redis内部是单进程、单线程,是数据安全的(只有自己的线程在操作数据) ---------------------------------------------------------------- #A、B、C,三个实例(主) 1、来了一个'隔壁老王'要操作,且不想让别人操作,so,加锁; 加锁:'隔壁老王'自己生成一个随机字符串,设置到A、B、C里(xxx=666) 2、来了一个'邻居老李'要操作A、B、C,一读发现里面有字符串,擦,被加锁了,不能操作了,等着吧~ 3、'隔壁老王'解决完问题,不用锁了,把A、B、C里的key:'xxx'删掉;完成解锁 4、'邻居老李'现在可以访问,可以加锁了 # 问题: 1、如果'隔壁老王'加锁后突然挂了,就没人解锁,就死锁了,其他人干看着没法用咋办? 2、如果'隔壁老王'去给A、B、C加锁的过程中,刚加到A,'邻居老李'就去操作C了,加锁成功or失败? 3、如果'隔壁老王'去给A、B、C加锁时,C突然挂了,这次加锁是成功还是失败? 4、如果'隔壁老王'去给A、B、C加锁时,超时时间为5秒,加一个锁耗时3秒,此次加锁能成功吗? # 解决 1、安全起见,让'隔壁老王'加锁时设置超时时间,超时的话就会自动解锁(删除key:'xxx') 2、加锁程度达到(1/2)+1个就表示加锁成功,即使没有给全部实例加锁; 3、加锁程度达到(1/2)+1个就表示加锁成功,即使没有给全部实例加锁; 4、不能成功,锁还没加完就过期,没有意义了,应该合理设置过期时间 # 注意 使用需要安装redlock-py ---------------------------------------------------------------- from redlock import Redlock dlm = Redlock( [ {"host": "localhost", "port": 6379, "db": 0}, {"host": "localhost", "port": 6379, "db": 0}, {"host": "localhost", "port": 6379, "db": 0}, ] ) # 加锁,acquire my_lock = dlm.lock("my_resource_name",10000) if my_lock: # 进行操作 # 解锁,release dlm.unlock(my_lock) else: print('获取锁失败') #通过sever.eval(self.unlock_script)执行一个lua脚本,用来删除加锁时的key
46、什么是一致性哈希?Python中是否有相应模块?
# 一致性哈希 一致性hash算法(DHT)可以通过减少影响范围的方式,解决增减服务器导致的数据散列问题,从而解决了分布式环境下负载均衡问题; 如果存在热点数据,可以通过增添节点的方式,对热点区间进行划分,将压力分配至其他服务器,重新达到负载均衡的状态。 # 模块:hash_ring
47、如何高效的找到redis中所有以zhugc开头的key?
redis 有一个keys命令。 # 语法:KEYS pattern # 说明:返回与指定模式相匹配的所用的keys。 该命令所支持的匹配模式如下: 1、?:用于匹配单个字符。例如,h?llo可以匹配hello、hallo和hxllo等; 2、*:用于匹配零个或者多个字符。例如,h*llo可以匹配hllo和heeeello等; 2、[]:可以用来指定模式的选择区间。例如h[ae]llo可以匹配hello和hallo,但是不能匹配hillo。同时,可以使用“/”符号来转义特殊的字符 # 注意 KEYS 的速度非常快,但如果数据太大,内存可能会崩掉, 如果需要从一个数据集中查找特定的key,最好还是用Redis的集合结构(set)来代替。
48、悲观锁和乐观锁的区别?
# 悲观锁 从数据开始更改时就将数据锁住,直到更改完成才释放; 会造成访问数据库时间较长,并发性不好,特别是长事务。 # 乐观锁 直到修改完成,准备提交修改到数据库时才会锁住数据,完成更改后释放; 相对悲观锁,在现实中使用较多。
第四部分 前端、框架和其他(155题)
1、谈谈你对http协议的认识。
# 通过/r/n分割 # 请求头请求体之间:/r/n/r/n # 无状态 # 短连接
2、谈谈你对websocket协议的认识。
# a.什么是websocket? 是给浏览器新建的一套协议 协议规定:创建连接后不断开 通过'\r\n'分割,让客户端和服务端创建连接后不断开、验证+数据加密 # b.本质: # 就是一个创建连接后不断开的socket # 当连接成功后: - 客户端(浏览器)会自动向服务端发送消息 - 服务端接收后,会对该数据加密:base64(sha1(swk+magic_string)) - 构造响应头 - 发送给客户端 # 建立双工通道,进行收发数据 # c.框架中是如何使用websocket的? django:channel flask:gevent-websocket tornado:内置 # d.websocket的优缺点 优点:代码简单,不再重复创建连接 缺点:兼容性没有长轮询好,如IE会有不兼容
3、什么是magic string ?
websocket里面的 # 客户端向服务端发送消息时,会有一个'sec-websocket-key'和'magic string'的随机字符串(魔法字符串) # 服务端接收到消息后会把他们连接成一个新的key串,进行编码、加密,确保信息的安全性
4、如何创建响应式布局?
# a.可以通过引用Bootstrap实现 # b.通过看Bootstrap源码文件,可知其本质就是通过CSS实现的 <style> /*浏览器窗口宽度大于768,背景色变为 green*/ @media (min-width: 768px) { .pg-header{ background-color: green; } } /*浏览器窗口宽度大于992,背景色变为 pink*/ @media (min-width: 992px) { .pg-header{ background-color: pink; } } </style> </head> <body> <div class="pg-header"></div> </body>
5、你曾经使用过哪些前端框架?
# Jquery、Vue、Bootstrap、
6、什么是ajax请求?并使用jQuery和XMLHttpRequest对象实现一个ajax请求。
1.没用ajax:浏览器访问服务器请求,用户看得到(页面刷新也就等同于重新发请求,刷新看得到,也就等同于请求看得到)。等请求完,页面刷新,新内容出现,用户看到新内容。 2.用ajax:浏览器访问服务器请求,用户看不到,是悄悄进行。等请求完,页面不刷新,新内容也会出现,用户看到新内容。 参考:点击查看
7、如何在前端实现轮询?
# 轮询是在特定的的时间间隔(如每1秒),由浏览器对服务器发出HTTP request, # 然后由服务器返回最新的数据给客户端的浏览器。 var xhr = new XMLHttpRequest(); setInterval(function(){ xhr.open('GET','/user'); xhr.onreadystatechange = function(){ }; xhr.send(); },1000)
8、如何在前端实现长轮询?
# ajax实现:在发送ajax后,服务器端会阻塞请求直到有数据传递或超时才返回。 # 客户端JavaScript响应处理函数会在处理完服务器返回的信息后,再次发出请求,重新建立连接。 function ajax(){ var xhr = new XMLHttpRequest(); xhr.open('GET','/user'); xhr.onreadystatechange = function(){ ajax(); }; xhr.send(); }
9、vuex的作用?
1.不同组件之间共享状态,可以进行状态的修改和读取。 2.可以理解为是一个全局对象,所有页面都可以访问 3.还有比较重要的单一状态树管理,让数据的修改脉络更加清晰,便于定位问题。 # 比如用户做了一些加减的操作、三个页面都要用、可以用传参、但是很麻烦、这种时候用vuex就简单一些
10、vue中的路由的拦截器的作用?
# 统一处理所有http请求和响应时,可以用axios的拦截器。 # 通过配置http response inteceptor,当后端接口返回401 Unauthorized(未授权),让用户重新登录。 # so可以用来做登录拦截验证
11、axios的作用?
# axios是vue-resource后出现的Vue请求数据的插件 # 可以做的事情: 从浏览器中创建 XMLHttpRequest 从 node.js 发出 http 请求 支持 Promise API 拦截请求和响应 转换请求和响应数据 取消请求 自动转换JSON数据 客户端支持防止 CSRF/XSRF
12、列举vue的常见指令。
# 1、v-if指令:判断指令,根据表达式值得真假来插入或删除相应的值。 # 2、v-show指令: # 条件渲染指令,无论返回的布尔值是true还是false,元素都会存在html中, # false的元素会隐藏在html中,并不会删除. # 3、v-else指令:配合v-if或v-else使用。 # 4、v-for指令:循环指令,相当于遍历。 # 5、v-bind:给DOM绑定元素属性。 # 6、v-on指令:监听DOM事件。
13、简述jsonp及实现原理?
# 原理: 1、先在客户端注册一个callback, 然后把callback的名字传给服务器。 2、此时,服务器先生成 json 数据。 3、然后以 javascript 语法的方式,生成一个function , function 名字就是传递上来的参数 jsonp. 4、最后将 json 数据直接以入参的方式,放置到 function 中,这样就生成了一段 js 语法的文档,返回给客户端。 客户端浏览器,解析script标签,并执行返回的 javascript 文档,此时数据作为参数, 传入到了客户端预先定义好的 callback 函数里.(动态执行回调函数) # 注意 # JSON 是一种数据格式 # JSONP 是一种数据调用的方式
14、是什么cors ?
# 跨域资源共享(Cross-Origin Resource Sharing) # 其本质是设置响应头,使得浏览器允许跨域请求。 # 简单请求(一次请求) 1、请求方式:HEAD、GET、POST 2、请求头信息: Accept Accept-Language Content-Language Last-Event-ID Content-Type 对应的值是以下三个中的任意一个 application/x-www-form-urlencoded multipart/form-data text/plain # 非简单请求(两次请求) 在发送真正的请求之前,会默认发送一个'options'请求,做'预检',预检成功后才发送真正的请求 # 预检: 如果复杂请求是PUT等请求,则服务端需要设置允许某请求,否则“预检”不通过 Access-Control-Request-Method 如果复杂请求设置了请求头,则服务端需要设置允许某请求头,否则“预检”不通过 Access-Control-Request-Headers
15、列举Http请求中常见的请求方式?
# http请求方法有8种: 'GET' 'POST' 'HEAD' 'OPTIONS' 'PUT' 'DELETE' 'TRACE' 'CONNECT'
16、列举Http请求中的状态码?
# 2开头(成功) 200:请求成功 202:已接受请求,尚未处理 204:请求成功,且不需返回内容 # 3开头(重定向) 301:永久重定向 302:临时重定向 # 4开头(客户端错误) 400(Bad Request):请求的语义或是参数有错 403(Forbidden):服务器拒绝了请求(csrf) 404(Not Found):找不到页面(资源) # 5开头(服务器错误) 500:服务器遇到错误,无法完成请求 502:网关错误,一般是服务器压力过大导致连接超时 503:服务器宕机
17、列举Http请求中常见的请求头?
# 常见请求头: User-Agent、Referer、Host、Cookie、Connection、Accept
18、看图写结果:
看图写结果:
看图写结果:
看图写结果:
看图写结果:
看图写结果:
django、flask、tornado框架的比较?
什么是wsgi?
django请求的生命周期?
列举django的内置组件?
列举django中间件的5个方法?以及django中间件的应用场景?
简述什么是FBV和CBV?
django的request对象是在什么时候创建的?
如何给CBV的程序添加装饰器?
列举django orm 中所有的方法(QuerySet对象的所有方法)
only和defer的区别?
select_related和prefetch_related的区别?
filter和exclude的区别?
列举django orm中三种能写sql语句的方法。
django orm 中如何设置读写分离?
F和Q的作用?
values和values_list的区别?
如何使用django orm批量创建数据?
django的Form和ModeForm的作用?
django的Form组件中,如果字段中包含choices参数,请使用两种方式实现数据源实时更新。
django的Model中的ForeignKey字段中的on_delete参数有什么作用?
django中csrf的实现机制?
django如何实现websocket?
基于django使用ajax发送post请求时,都可以使用哪种方法携带csrf token?
django中如何实现orm表中添加数据时创建一条日志记录。
django缓存如何设置?
django的缓存能使用redis吗?如果可以的话,如何配置?
django路由系统中name的作用?
django的模板中filter和simple_tag的区别?
django-debug-toolbar的作用?
django中如何实现单元测试?
解释orm中 db first 和 code first的含义?
django中如何根据数据库表生成model中的类?
使用orm和原生sql的优缺点?
简述MVC和MTV
django的contenttype组件的作用?
谈谈你对restfull 规范的认识?
接口的幂等性是什么意思?
什么是RPC?
Http和Https的区别?
为什么要使用django rest framework框架?
django rest framework框架中都有那些组件?
django rest framework框架中的视图都可以继承哪些类?
简述 django rest framework框架的认证流程。
django rest framework如何实现的用户访问频率控制?
Flask框架的优势?
Flask框架依赖组件?
Flask蓝图的作用?
列举使用过的Flask第三方组件?
简述Flask上下文管理流程?
Flask中的g的作用?
Flask中上下文管理主要涉及到了那些相关的类?并描述类主要作用?
为什么要Flask把Local对象中的的值stack 维护成一个列表?
Flask中多app应用是怎么完成?
在Flask中实现WebSocket需要什么组件?
wtforms组件的作用?
Flask框架默认session处理机制?
解释Flask框架中的Local对象和threading.local对象的区别?
Flask中 blinker 是什么?
SQLAlchemy中的 session和scoped_session 的区别?
SQLAlchemy如何执行原生SQL?
ORM的实现原理?
DBUtils模块的作用?
以下SQLAlchemy的字段是否正确?如果不正确请更正:
1
2
3
4
5
6
7
8
9
10
11
from datetime import datetime
from sqlalchemy.ext.declarative
import declarative_base
from sqlalchemy import Column, Integer, String, DateTime
Base = declarative_base()
class UserInfo(Base):
__tablename__ = 'userinfo'
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(64), unique=True)
ctime = Column(DateTime, default=datetime.now())
SQLAchemy中如何为表设置引擎和字符编码?
SQLAchemy中如何设置联合唯一索引?
简述Tornado框架的特点。
简述Tornado框架中Future对象的作用?
Tornado框架中如何编写WebSocket程序?
Tornado中静态文件是如何处理的? 如: <link href="{{static_url("commons.css")}}" rel="stylesheet" />
Tornado操作MySQL使用的模块?
Tornado操作redis使用的模块?
简述Tornado框架的适用场景?
git常见命令作用:
简述以下git中stash命令作用以及相关其他命令。
git 中 merge 和 rebase命令 的区别。
公司如何基于git做的协同开发?
如何基于git实现代码review?
git如何实现v1.0 、v2.0 等版本的管理?
什么是gitlab?
github和gitlab的区别?
如何为github上牛逼的开源项目贡献代码?
git中 .gitignore文件的作用?
什么是敏捷开发?
简述 jenkins 工具的作用?
公司如何实现代码发布?
简述 RabbitMQ、Kafka、ZeroMQ的区别?
RabbitMQ如何在消费者获取任务后未处理完前就挂掉时,保证数据不丢失?
RabbitMQ如何对消息做持久化?
RabbitMQ如何控制消息被消费的顺序?
以下RabbitMQ的exchange type分别代表什么意思?如:fanout、direct、topic。
简述 celery 是什么以及应用场景?
简述celery运行机制。
celery如何实现定时任务?
简述 celery多任务结构目录?
celery中装饰器 @app.task 和 @shared_task的区别?
简述 requests模块的作用及基本使用?
简述 beautifulsoup模块的作用及基本使用?
简述 seleninu模块的作用及基本使用?
scrapy框架中各组件的工作流程?
在scrapy框架中如何设置代理(两种方法)?
scrapy框架中如何实现大文件的下载?
scrapy中如何实现限速?
scrapy中如何实现暂定爬虫?
scrapy中如何进行自定制命令?
scrapy中如何实现的记录爬虫的深度?
scrapy中的pipelines工作原理?
scrapy的pipelines如何丢弃一个item对象?
简述scrapy中爬虫中间件和下载中间件的作用?
scrapy-redis组件的作用?
scrapy-redis组件中如何实现的任务的去重?
scrapy-redis的调度器如何实现任务的深度优先和广度优先?
简述 vitualenv 及应用场景?
简述 pipreqs 及应用场景?
在Python中使用过什么代码检查工具?
简述 saltstack、ansible、fabric、puppet工具的作用?
# Saltstack是一个服务器集中管理中心平台,可以帮助管理员轻松的对若干台服务器进行统一操作。 # 类似的工具还有Ansible,Puppet,func等等。相比于这些工具,salt的特点在于其用python实现,支持各种操作系统类型,采取了C/S架构,部署方便简单, 且可扩展性很强。 # SaltStack 采用 C/S模式,server端就是salt的master,client端就是minion,minion与master之间通过ZeroMQ消息队列通信 # minion上线后先与master端联系,把自己的pub key发过去,这时master端通过salt-key -L命令就会看到minion的key,接受该minion-key后,也就是master与minion已经互信
B Tree和B+ Tree的区别?
请列举常见排序并通过代码实现任意三种。
请列举常见查找并通过代码实现任意三种。
请列举你熟悉的设计模式?
有没有刷过leetcode?
列举熟悉的的Linux命令。
公司线上服务器是什么系统?
解释 PV、UV 的含义?
解释 QPS的含义?
uwsgi和wsgi的区别?
supervisor的作用?
什么是反向代理?
简述SSH的整个过程。
有问题都去那些找解决方案?
是否有关注什么技术类的公众号?
最近在研究什么新技术?
是否了解过领域驱动模型?
题目出处:https://www.cnblogs.com/wupeiqi/p/9078770.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号