Pycharm中断点调试(debug)scrapy
OutLine
一般写好一个 scrapy 项目,启动方式大多会在命令行里执行:
scrapy crawl “spider-name” (后面有参数就跟参数)
但这么启动不方便去断点调试,不便于快速定位问题、解决问题。
So 记录下自己在pycharm中断点调试的过程。(下文中图片可能看不清,点击即可查看大图)
配置Pycharm
既然想用pycharm断点调试,理应把你的操作都框在pycharm里;
因为 `scrapy crawl 爬虫name` 这种启动方式本质上是走的你Python环境里scrapy库(package)中cmdline.py
(Lib\site-packages\scrapy\cmdline.py)
现在要把这个启动入口放在pycharm里启动;
配置如下:
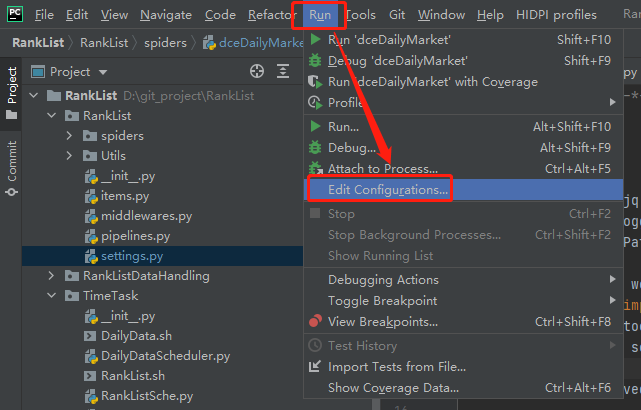
Step1
点击:`Run->Edit Configurations`
Step2
增加一个 `python` 配置项目:
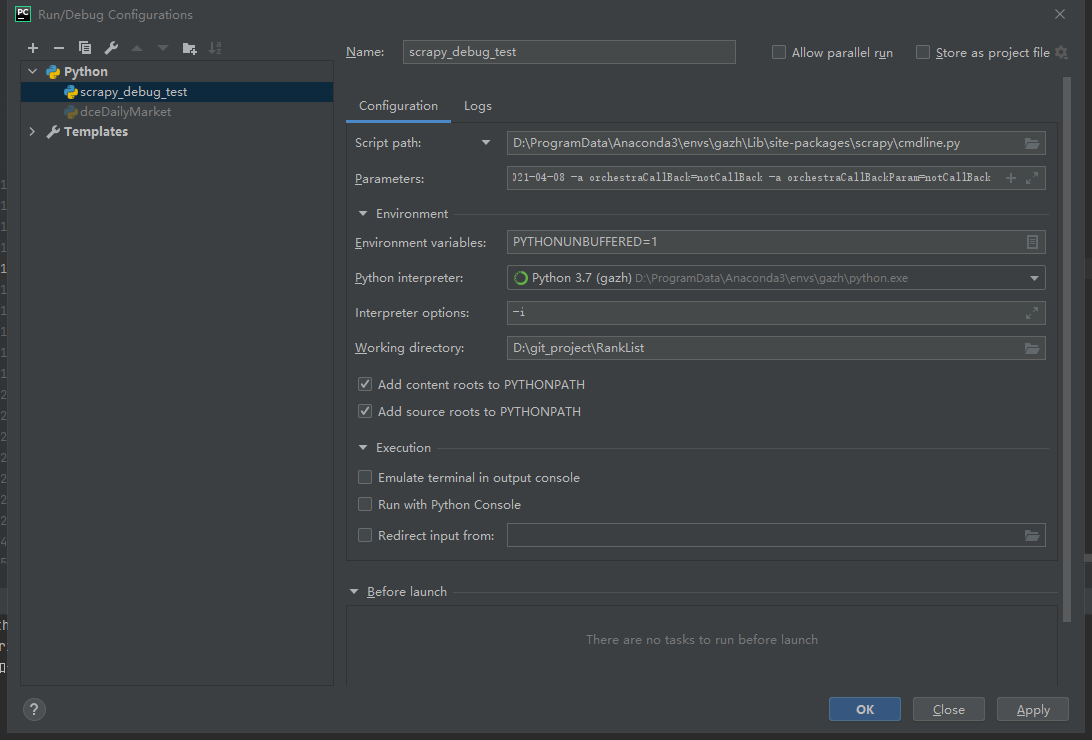
# Name:配置项目的名称 # Script path:scrapy package中的cmdline.py文件路径 # Parameters:启动scrapy爬虫所需参数(也就是传参) # Python Interpreter:选择所用的Python环境(我用的自己创建的anaconda虚拟环境,找cmdline.py文件时也是在虚拟环境中的site-packages找到,这点要注意) # Working directory:你scrapy爬虫项目根目录 其余的选项用默认的就行
Parameters 示例:
crawl dceDailyMarket -a curDay=2021-04-08 -a orchestraCallBack=notCallBack -a orchestraCallBackParam=notCallBack
这是我所用的参数(传的参数),也即:crawl 爬虫名字(代码里的name变量对应的)-a 参数=参数值 -a 参数=参数值 -a 参数=参数值
配置好后点击 ok ,你的pycharm右上方运行工具栏那里,就会有你刚配的这个启动项;
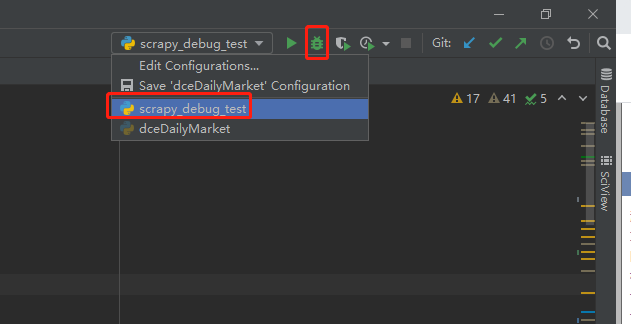
Step3
在需要调试的代码处加断点,然后点击debug按钮;
代码走到断点处,就会停下来,然后就可以愉快的进行debug了~~
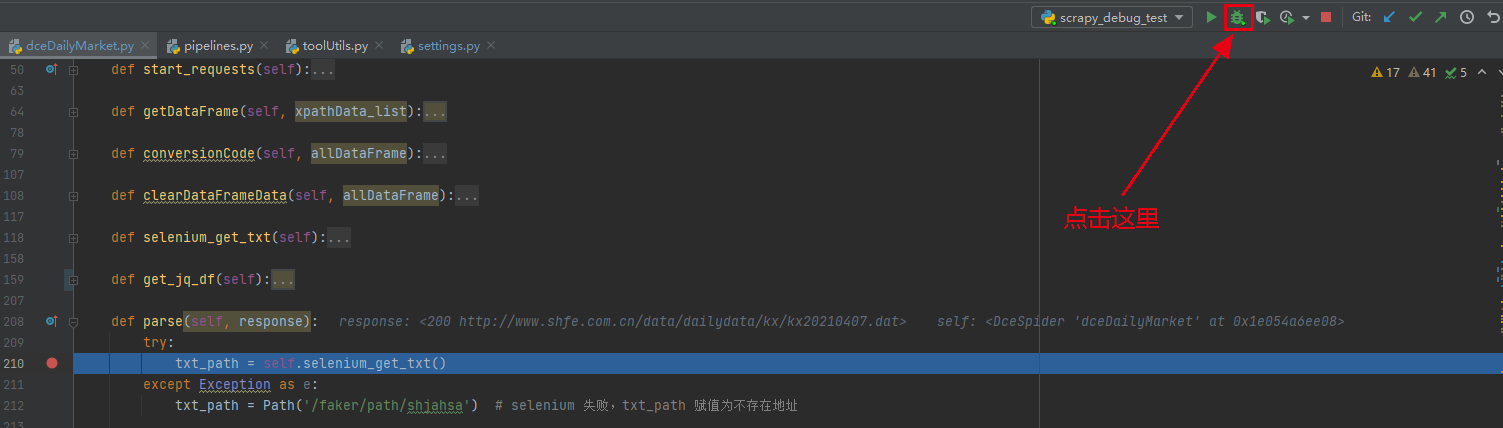
Step4
跨文件断点调试
上面截图,dceDailyMarket.py 是我的具体爬虫代码文件
代码执行过程中会走 pipline.py 里的代码,想看里面具体怎么走的?
只需要在 pipline.py 里对应处加断点:

代码中可能还会引用 toolUtils.py 中的方法
如果想 debug 里面的代码,只需要在 toolUtils.py 里加断点即可
这样就可以实时看到想看的信息(变量、对象、报错等……)
END
这样一来,就可以像调试一份普通Python代码那样easy了。
便于快速定位问题、解决问题、提高效率、节省时间~
对了,还有一种方法,可以起到同样效果:
from scrapy import cmdline cmdline.execute() # 感兴趣的可以去了解下这种方式,我没去具体操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号