第三周:简单数据分布
正态分布
简介
正态分布又名高斯分布它以数学天才 Carl Friedrich Gauss 命名正态分布又名高斯分布,越简单的模型越是常用,因为它们能够被很好的解释和理解。
正态分布非常简单,这就是它是如此的常用的原因。因此,理解正态分布非常有必要。
什么是概率分布
首先介绍一下相关概念:
如果我们想精确预测一个变量的值,那么我们首先要做的就是理解该变量的潜在特性。
首先我们要知道该变量的可能取值,还要知道这些值是连续的还是离散的。简单来讲,如果我们要预测一个骰子的取值,那么第一步就是明白它的取值是1 到 6(离散)。
第二步就是确定每个可能取值(事件)发生的概率。如果某个取值永远都不会出现,那么该值的概率就是 0 。事件的概率越大,该事件越容易出现。
在实际操作中,我们可以大量重复进行某个实验,并记录该实验对应的输出变量的结果。我们可以将这些取值分为不同的集合类,在每一类中,我们记录属于该类结果的次数。
例如:
我们可以投10000次骰子,每次都有6种可能的取值,我们可以将类别数设为6,然后我们就可以开始对每一类出现的次数进行计数了。
我们可以画出上述结果的曲线,该曲线就是概率分布曲线。目标变量每个取值的可能性就由其概率分布决定。
一旦我们知道了变量的概率分布,我们就可以开始估计事件出现的概率了,我们甚至可以使用一些概率公式。至此,我们就可更好的理解变量的特性了。
概率分布取决于样本的一些特征,例如平均值,标准偏差,偏度和峰度。如果将所有概率值求和,那么求和结果将会是100%;
世界上存在着很多不同的概率分布,而最广泛使用的就是正态分布了。
初遇正态分布
我们可以画出正态分布的概率分布曲线,可以看到该曲线是一个钟型的曲线。如果变量的均值,模和中值相等,那么该变量就呈现正态分布。
如下图所示,为正态分布的概率分布曲线:

什么是正态分布
正态分布只依赖于数据集的两个特征:样本的均值和方差。
为何如此多的变量都大致服从正态分布
这个现象可以由如下定理解释:
当在大量随机变量上重复很多次实验时,它们的分布总和将非常接近正态分布。

如上图所示,该钟形曲线有均值为 100,标准差为1:
均值是曲线的中心。这是曲线的最高点,因为大多数点都是均值。曲线两侧的点数相等。
曲线的中心具有最多的点数。曲线下的总面积是变量所有取值的总概率。因此总曲线面积为 100%
更进一步,如下图所示:

约 68.2% 的点在 -1 到 1 个标准偏差范围内。 约 95.5% 的点在 -2 到 2 个标准偏差范围内。 约 99.7% 的点在 -3 至 3 个标准偏差范围内。
正态分布函数

正态分布是钟形曲线,其中mean = mode = median。
使用 Python 探索变量的概率分布
最简单的方法是使用pandas中的df.hist(bins=10):
import pandas as pd df = pd.read_csv('test.csv') df.hist(bins=10) #Make a histogram of the DataFrame.
变量服从正态分布意味着什么
A x B 是正态分布A + B 是正态分布
样本不服从正态分布怎么办
计算平均值计算标准偏差对于每个 x,使用以下方法计算 Z:

2. 使用 Boxcox 变换
我们可以使用 SciPy 包将数据转换为正态分布:
scipy.stats.boxcox(x, lmbda=None, alpha=None)
3. 使用 Yeo-Johnson 变换
另外,我们可以使用 yeo-johnson 变换。
Python 的 sci-kit learn 库提供了相应的功能:
sklearn.preprocessing.PowerTransformer(method=’yeojohnson’,standardize=True, copy=True)
正态分布的问题
二项分布式
概念
二项分布是一种具有广泛用途的离散型随机变量的概率分布,它是由贝努里始创的,所以又叫贝努里分布。
二项分布是指统计变量中只有性质不同的两项群体的概率分布。所谓两项群体是按两种不同性质划分的统计变量,是二项试验的结果。
即各个变量都可归为两个不同性质中的一个,两个观测值是对立的。因而两项分布又可说是两个对立事件的概率分布。
二项分布的解析
二项分布用符号b(x.n.p),表示在n次试验中有x次成功,成功的概率为p。
二项分布的概率函数可写作:
b(x.n.p)=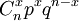
式中x=0、1、2、3.....n为正整数
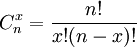
两项分布中含有两个参数n与p,当它们的值已知时,便可计算出分布列中各概率的值。
例1 掷硬币试验。有10个硬币掷一次,或1个硬币掷十次。问五次正面向上的概率是多少?
解:根据题意n=10,p=q=1/2,x=5
b(5、l0、1/2) = 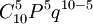
= 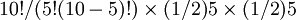
= 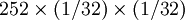
= 0.24609
所以五次正面向上的概率为0.24609
例2 此题若问五次及五次以上正面向上的概率是多少?
解:此题要求出五次及五次以上正面向上的概率之和。正面有五次、六次、七次、八次、九次、十次。依公式5—10应为:
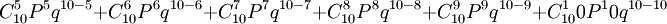
= 252/1024+210/1024+120/1024+45/1024+10/1024+1/1024
= 638/1024
= 0.623
五次及五次以上正面向上的概率为0.623
参考:https://wiki.mbalib.com/wiki/%E4%BA%8C%E9%A1%B9%E5%88%86%E5%B8%83
泊松分布
什么是泊松分布
Poisson分布(法语:loi de Poisson,英语:Poisson distribution,译名有泊松分布、普阿松分布、卜瓦松分布、布瓦松分布、布阿松分布、波以松分布、卜氏分配等),
是一种统计与概率学里常见到的离散机率分布(discrete probability distribution),由法国数学家西莫恩·德尼·泊松(Siméon-Denis Poisson)在1838年时发表。
泊松分布函数
泊松分布的概率质量函数为:
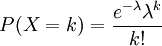
泊松分布的参数λ是单位时间(或单位面积)内随机事件的平均发生率。
泊松分布适合于描述单位时间内随机事件发生的次数。
如某一服务设施在一定时间内到达的人数,电话交换机接到呼叫的次数,汽车站台的候客人数,机器出现的故障数,自然灾害发生的次数等等。
若随机变量X取0和一切正整数值,在n次独立试验中出现的次数x恰为k次的概率P(X=k)=(k=0,1,...,n),式中λ是一个大于0的参数,此概率分布称为泊松分布。
它的期望值为E(x)=λ,方差为D(x) = λ。当n很大,且在一次试验中出现的概率P很小时,泊松分布近似二项分布。
参考:https://wiki.mbalib.com/wiki/%E6%B3%8A%E6%9D%BE%E5%88%86%E5%B8%83
均匀分布
在概率论和统计学中,均匀分布也叫矩形分布,它是对称概率分布,在相同长度间隔的分布概率是等可能的。
均匀分布由两个参数a和b定义,它们是数轴上的最小值和最大值,通常缩写为U(a,b)。
概率密度函数
分布函数
卡方分布
卡方分布 (χ2分布)是概率论与统计学中常用的一种概率分布。
k 个独立的标准正态分布变量的平方和服从自由度为k 的卡方分布。卡方分布常用于假设检验和置信区间的计算。
数学定义
若k 个随机变量Z1、……、Zk 相互独立,且数学期望为0、方差为 1(即服从标准正态分布),则随机变量X
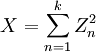
被称为服从自由度为 k 的卡方分布,记作
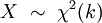
卡方分布特征
卡方分布的概率密度函数为:
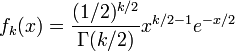
其中x≥0, 当x≤0时fk(x) = 0。这里Γ代表Gamma 函数。

参考:https://wiki.mbalib.com/wiki/%E5%8D%A1%E6%96%B9%E5%88%86%E5%B8%83
beta(贝塔)分布
用一句话来说,beta分布可以看作一个概率的概率分布,当你不知道一个东西的具体概率是多少时,它可以给出了所有概率出现的可能性大小。
举一个简单的例子:
熟悉棒球运动的都知道有一个指标就是棒球击球率(batting average),就是用一个运动员击中的球数除以击球的总数,
我们一般认为0.266是正常水平的击球率,而如果击球率高达0.3就被认为是非常优秀的。
现在有一个棒球运动员,我们希望能够预测他在这一赛季中的棒球击球率是多少。 你可能就会直接计算棒球击球率,用击中的数除以击球数,但是如果这个棒球运动员只打了一次,而且还命中了,那么他就击球率就是100%了,
这显然是不合理的,因为根据棒球的历史信息,我们知道这个击球率应该是0.215到0.36之间才对啊。 对于这个问题,我们可以用一个二项分布表示(一系列成功或失败),一个最好的方法来表示这些经验(在统计中称为先验信息)就是用beta分布,
这表示在我们没有看到这个运动员打球之前,我们就有了一个大概的范围。beta分布的定义域是(0,1)这就跟概率的范围是一样的。
接下来我们将这些先验信息转换为beta分布的参数,我们知道一个击球率应该是平均0.27左右,
而他的范围是0.21到0.35,那么根据这个信息,我们可以取α=81,β=219

之所以取这两个参数是因为:
- beta分布的均值是
- 从图中可以看到这个分布主要落在了(0.2,0.35)间,这是从经验中得出的合理的范围。

在这个例子里,我们的x轴就表示各个击球率的取值,x对应的y值就是这个击球率所对应的概率。也就是说beta分布可以看作一个概率的概率分布。
参考:http://www.360doc.com/content/16/1228/10/38911980_618347839.shtml

 浙公网安备 33010602011771号
浙公网安备 33010602011771号