pandas删除包含指定内容的行
Outline
处理数据时,遇到文件中包含一些不需要的数据(行),需要把这些不符合要求的行给删除掉。
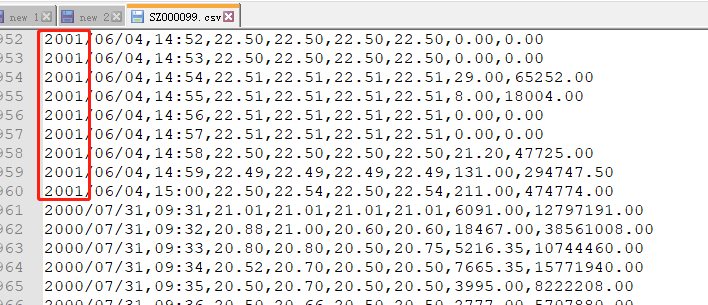
例如:该数据中应该都是2000年的数据,但是包含了一些2001年的数据,所以需要把2001年的数据给删除掉。
筛选出指定行
找到所有包含2000年的数据:
source_df[(source_df['date'].map(lambda d: d.split('/')[0])).isin([‘2000’])] # source_df 为读取的csv文件对象
根据pandas中取反操作:”~“, 取出所有不包含2000年的数据:
source_df[~(source_df['date'].map(lambda d: d.split('/')[0])).isin([year])]
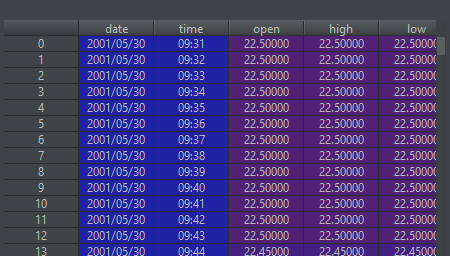
删除不合法数据
source_df.drop(source_df[~(source_df['date'].map(lambda d:d.split('/')[0])).isin([year])].index) # 根据 drop和index 删除包含2001的数据
删除后DataFrame中就只包含2000年的数据


 浙公网安备 33010602011771号
浙公网安备 33010602011771号