
利用数组去重
-
awk基本格式说明:
- awk 'pattern{action}'
- awk 'pattern' # 省略action,默认action为
- awk '1' # 等于 awk '1{print}'
- pattern等于0是,条件为假,不会执行后面省略的{action}; 非0为真
- var++形式:先读取var变量值,再对var值加1
-
示例1:
-
数据:
1 2 3
1 2 3
1 2 4
1 2 5 -
脚本:
awk '!a[$3]++' -
解读:
- awk处理第一行时,先读取a[$3]的值再自增1,a[$3]初始值为空(0),即awk '!0',亦即awk '1',即awk '1{print}', 打印当前行记录
- awk处理第二行时,先读取a[$3]的值再自增1,a[$3]当前值为1,即awk '!1',亦即awk '0',即awk '0{print}', 不执行默认action
- 以此类推,最后可以实现只对$3第一次出现的行进行打印,达到去除$3重复行的目的。
-
-
示例2:
-
脚本:
awk '!($3 in a){a[$3];print}' data -
解读:
- 跟示例2的作用一样,如果$3的值不在a[$3]数组的下标中,就把$3存入数组下标中,并打印
- 执行到第二行时,$3的值是3,已经存在于数组a的下标中,则不会执行后面的{action},达到去重的目的
-
-
示例3:
-
数据:
May 6 23:45:04 387 282 105
May 6 23:45:14 391 283 108
May 6 23:45:25 392 285 105
May 6 23:45:35 385 284 101
May 6 23:45:45 391 296 95
May 6 23:45:55 390 292 97
May 6 23:50:07 370 277 92
May 6 23:50:17 369 276 93
May 6 23:50:28 375 282 93
May 6 23:50:38 373 282 91
May 6 23:50:48 370 283 87
May 6 23:50:58 370 285 85
May 6 23:55:00 344 266 78
May 6 23:55:10 348 268 80
May 6 23:55:21 349 271 78
May 6 23:55:31 342 264 77
May 6 23:55:41 348 272 76
May 6 23:55:51 351 274 77 -
期望结果: 提取每5分钟间隔秒数最小的行
![]()
-
脚本:
awk -F: '$2%5==0 && !a[$1,$2]++' data -
解读:
- 以冒号为分割,$2即为分钟数,对5取模,只有0分和5分的时候余数等于0,满足条件,并且把$1 $2放入数组里,!a[$1,$2]++ 剔除该分数内重复的行
-
-
示例4:
-
data:
IP ADDRESS = 192.168.2.236 ;
IP ADDRESS = 192.168.2.236 ;
IP ADDRESS = 192.168.2.235 ;
IP ADDRESS = 192.168.2.236 ;
IP ADDRESS = 192.168.2.234 ;
IP ADDRESS = 192.168.2.236 ;
-
脚本:
awk 'NF&&!a[$0]++' data -
解读:
- 文件本身里有空格,空格也算是一行内容,怎么排除这个空行?
- NF作为pattern时可以判断该行是否为空行的条件
-
输出结果:
![]()
-
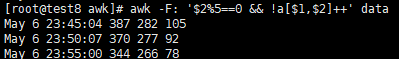

*** 你必须十分努力,才能看起来毫不费力 ***

 浙公网安备 33010602011771号
浙公网安备 33010602011771号