用python写一个豆瓣短评通用爬虫(登录、爬取、可视化)
原创技术公众号:
bigsai,本文在1024发布,祝大家节日快乐,心想事成。
@
前言
在本人上的一门课中,老师对每个小组有个任务要求,介绍和完成一个小模块、工具知识的使用。然而我所在的组刚好遇到的是python爬虫的小课题。
心想这不是很简单嘛,搞啥呢?想着去搞新的时间精力可能不太够,索性自己就把豆瓣电影的评论(短评)搞一搞吧。
之前有写过哪吒那篇类似的,但今天这篇要写的像姨母般详细。本篇主要实现的是对任意一部电影短评(热门)的抓取以及可视化分析。 也就是你只要提供链接和一些基本信息,他就可以

分析
对于豆瓣爬虫,what shold we 考虑?怎么分析呢?豆瓣电影首页
这个首先的话尝试就可以啦,打开任意一部电影,这里以姜子牙为例。打开姜子牙你就会发现它是非动态渲染的页面,也就是传统的渲染方式,直接请求这个url即可获取数据。但是翻着翻着页面你就会发现:未登录用户只能访问优先的界面,登录的用户才能有权限去访问后面的页面。
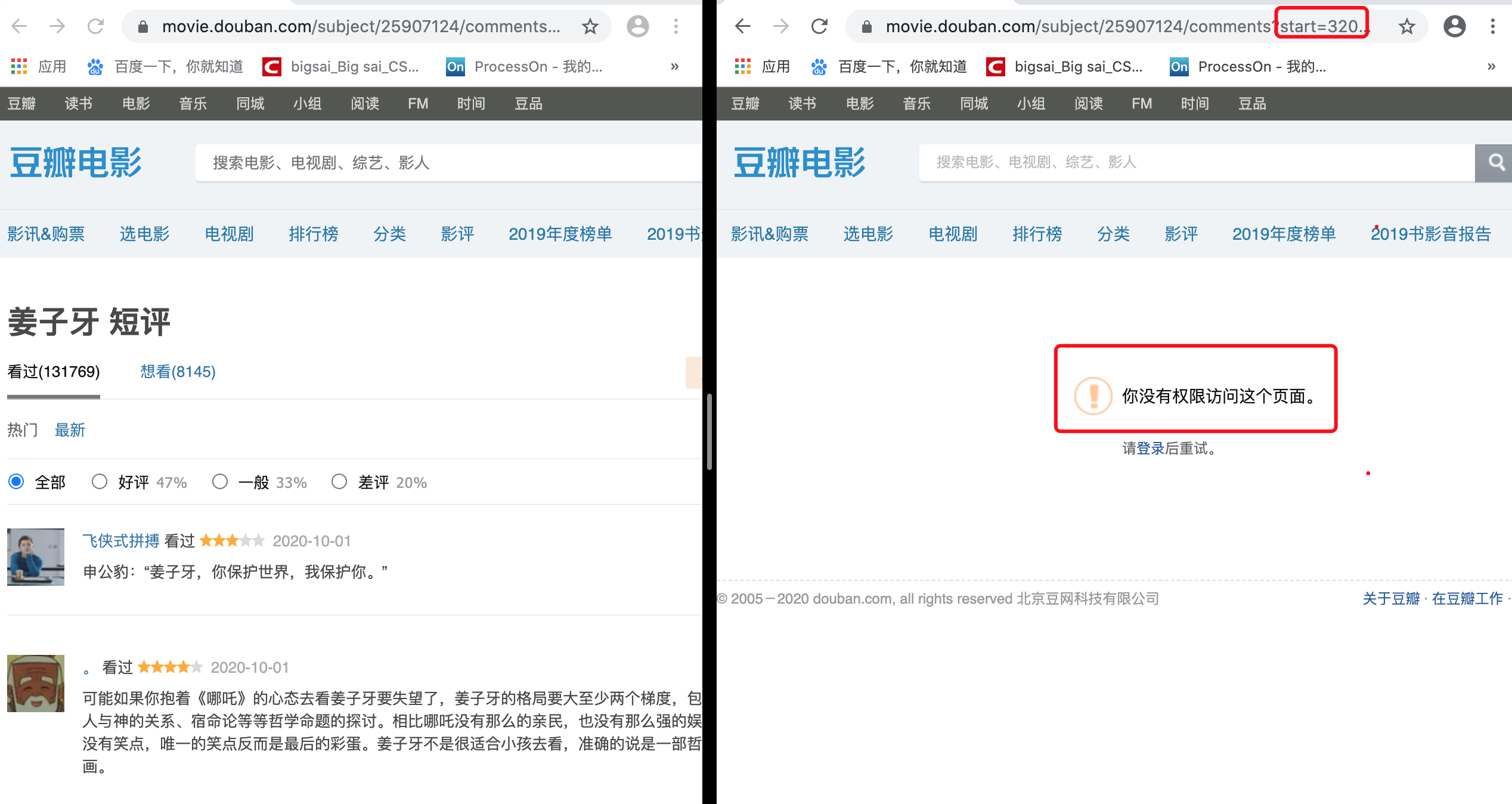
所以这个流程应该是 登录——> 爬虫——>存储——>可视化分析。
这里提一下环境和所需要的安装装,环境为python3,代码在win和linux可成功跑,如果mac和linux不能跑友字体乱码问题还请私我。其中pip用到包如下,直接用清华 镜像下载不然很慢很慢(够贴心不)。
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install xlrd -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install xlwt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install bs4 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install wordcloud -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install jieba -i https://pypi.tuna.tsinghua.edu.cn/simple
登录
进去后有个密码登录栏,我们要分析在登录的途中发生了啥,打开F12控制台是不够的,我们还要使用Fidder抓包。
打开F12控制台然后点击登录,多次试探之后发现登录接口也很简单:
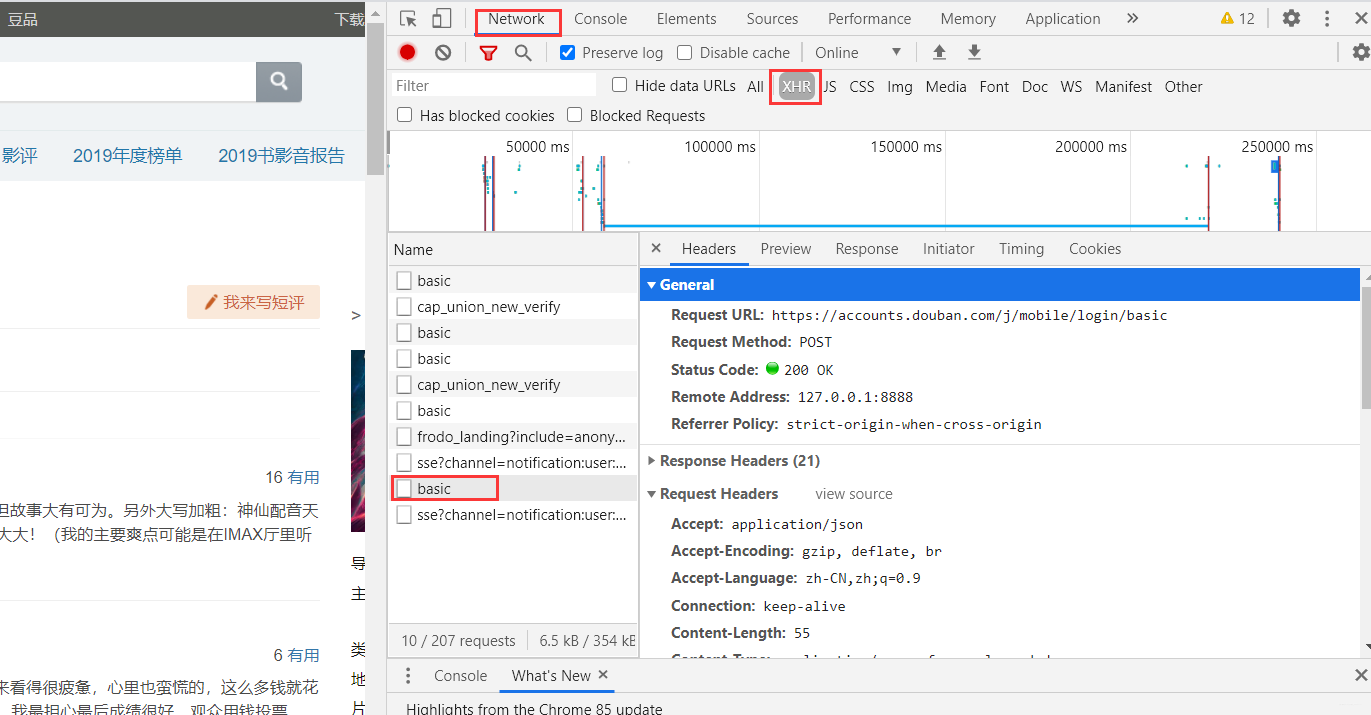
查看请求的参数发现就是普通请求,无加密,当然这里可以用fidder进行抓包,这里我简单测试了一下用错误密码进行测试。如果失败的小伙伴可以尝试手动登陆再退出这样再跑程序。
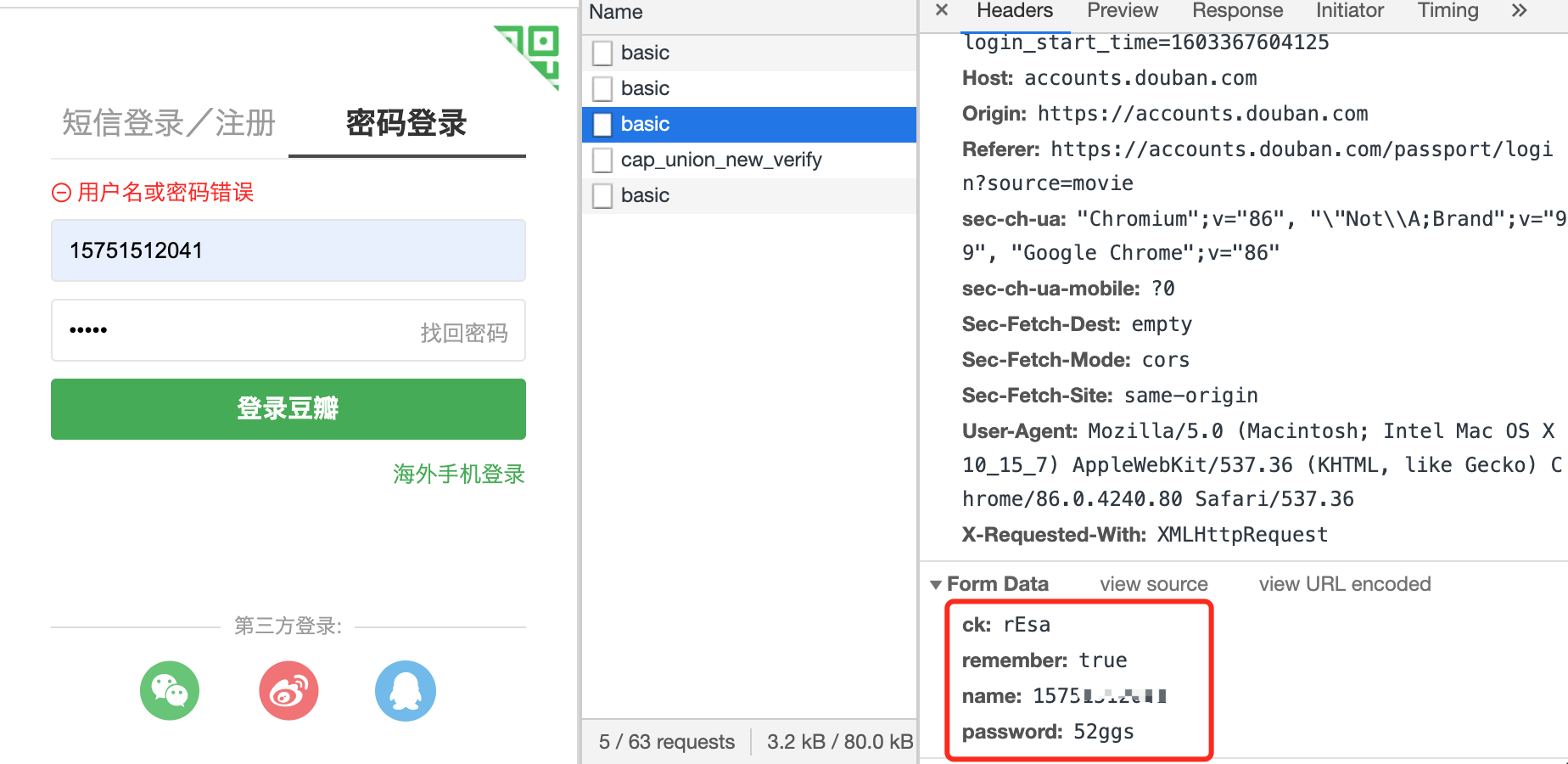
这样编写登录模块的代码:
url='https://accounts.douban.com/j/mobile/login/basic'
header={'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',
'Referer': 'https://accounts.douban.com/passport/login_popup?login_source=anony',
'Origin': 'https://accounts.douban.com',
'content-Type':'application/x-www-form-urlencoded',
'x-requested-with':'XMLHttpRequest',
'accept':'application/json',
'accept-encoding':'gzip, deflate, br',
'accept-language':'zh-CN,zh;q=0.9',
'connection': 'keep-alive'
,'Host': 'accounts.douban.com'
}
data={
'ck':'',
'name':'',
'password':'',
'remember':'false',
'ticket':''
}
def login(username,password):
global data
data['name']=username
data['password']=password
data=urllib.parse.urlencode(data)
print(data)
req=requests.post(url,headers=header,data=data,verify=False)
cookies = requests.utils.dict_from_cookiejar(req.cookies)
print(cookies)
return cookies
这块高清之后,整个执行流程大概为:
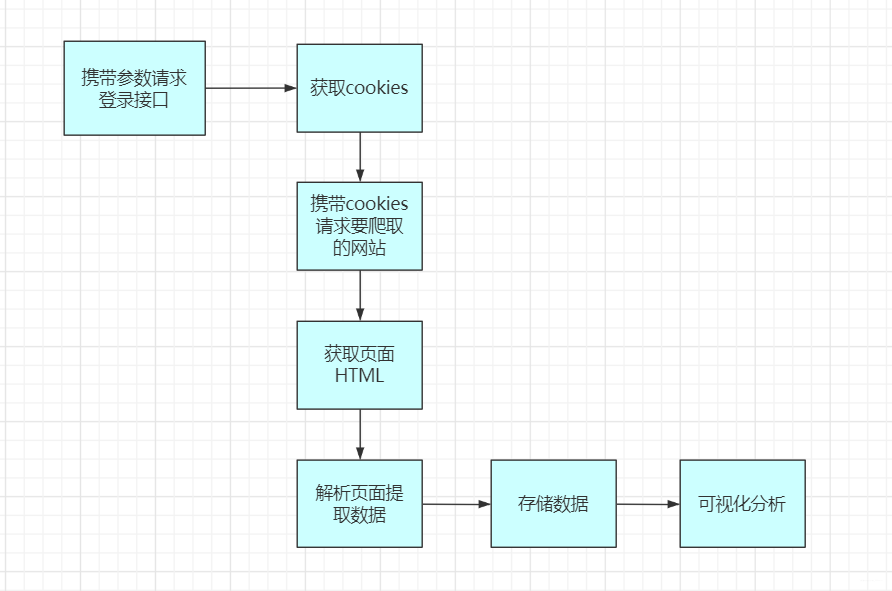
爬取
成功登录之后,我们就可以携带登录的信息访问网站为所欲为的爬取信息了。虽然它是传统交互方式,但是每当你切换页面时候会发现有个ajax请求。
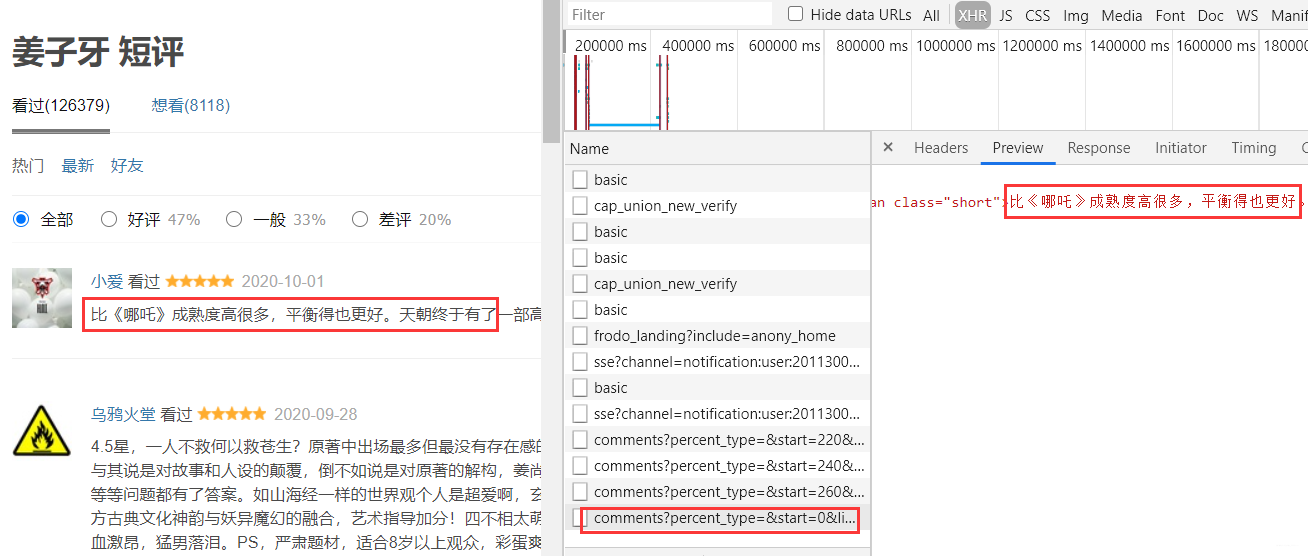
这部分接口我们可以直接拿到评论部分的数据,就不需要请求整个页面然后提取这部分的内容了。而这部分的url规律和之前分析的也是一样,只有一个start表示当前的条数在变化,所以直接拼凑url就行。
也就是用逻辑拼凑url一直到不能正确操作为止。
https://movie.douban.com/subject/25907124/comments?percent_type=&start=0&其他参数省略
https://movie.douban.com/subject/25907124/comments?percent_type=&start=20&其他参数省略
https://movie.douban.com/subject/25907124/comments?percent_type=&start=40&其他参数省略
对于每个url访问之后如何提取信息呢?
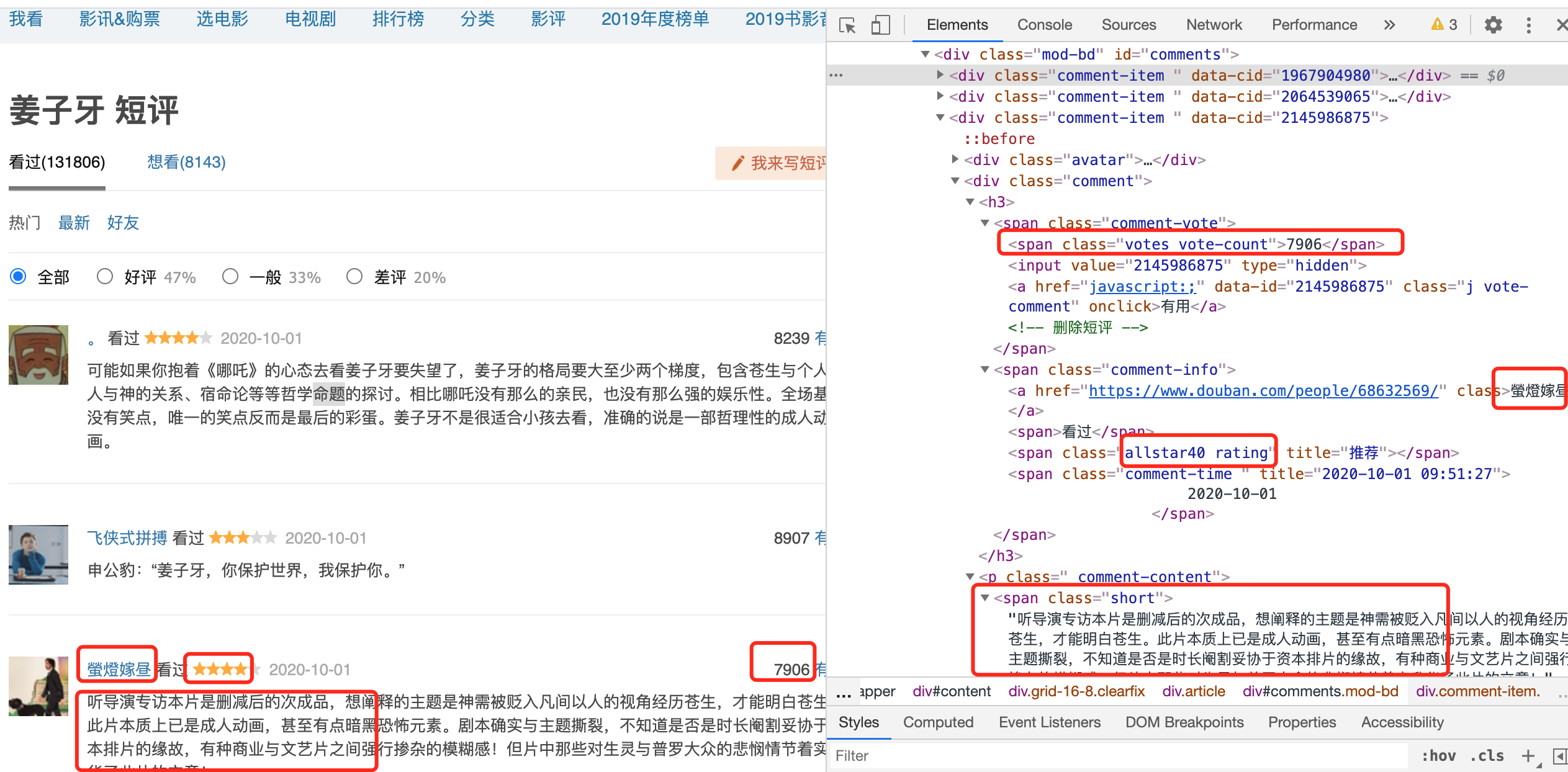
我们根据css选择器进行筛选数据,因为每个评论他们的样式相同,在html中就很像一个列表中的元素一样。
再观察我们刚刚那个ajax接口返回的数据刚好是下面红色区域块,所以我们直接根据class搜素分成若干小组进行曹祖就可以。

在具体的实现上,我们使用requests发送请求获取结果,使用BeautifulSoup去解析html格式文件。
而我们所需要的数据也很容易分析对应部分。
实现的代码为:
import requests
from bs4 import BeautifulSoup
url='https://movie.douban.com/subject/25907124/comments?percent_type=&start=0&limit=20&status=P&sort=new_score&comments_only=1&ck=C7di'
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',
}
req = requests.get(url,headers=header,verify=False)
res = req.json() # 返回的结果是一个json
res = res['html']
soup = BeautifulSoup(res, 'lxml')
node = soup.select('.comment-item')
for va in node:
name = va.a.get('title')
star = va.select_one('.comment-info').select('span')[1].get('class')[0][-2]
comment = va.select_one('.short').text
votes=va.select_one('.votes').text
print(name, star,votes, comment)
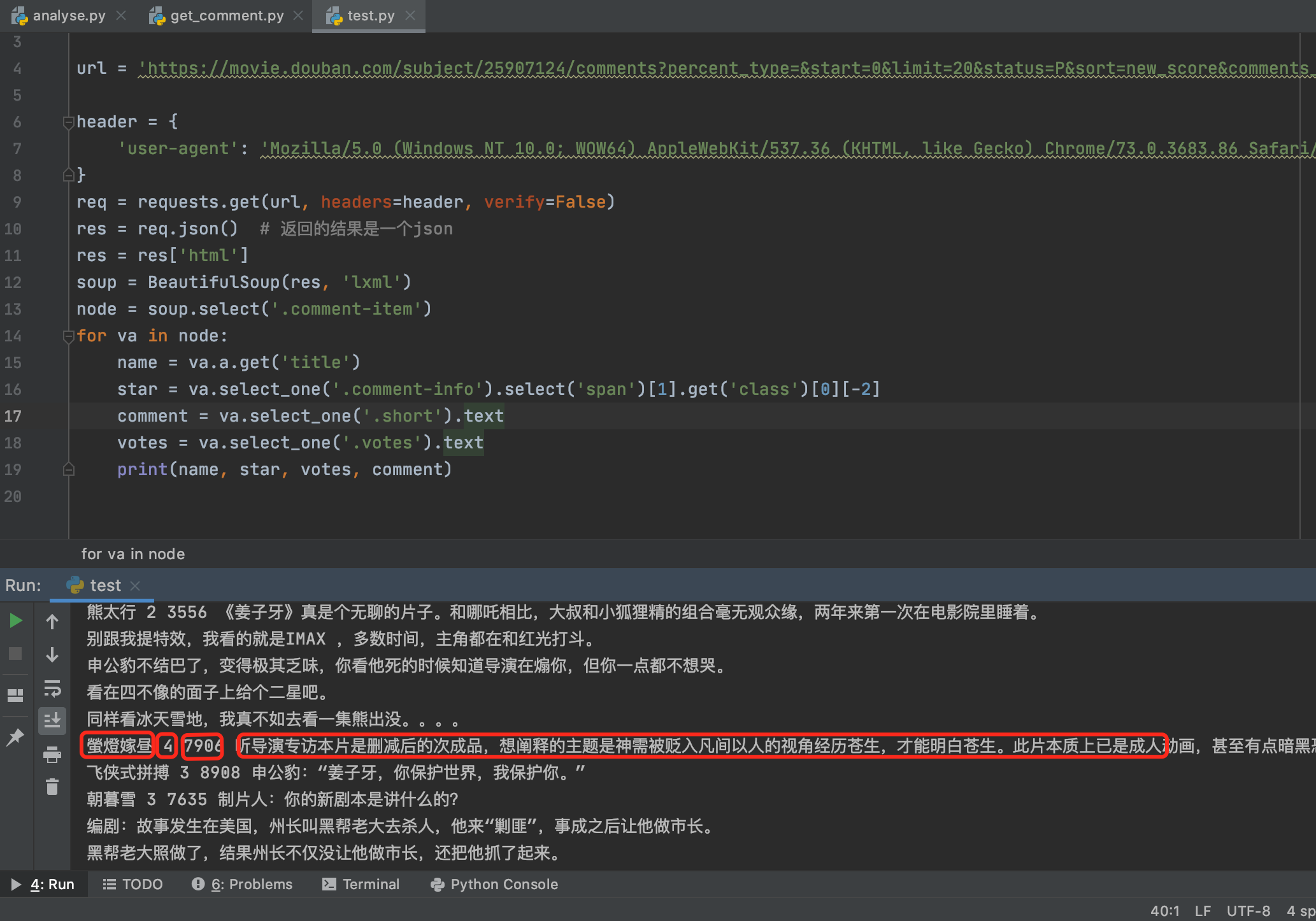
这个测试的执行结果为:
储存
数据爬取完就要考虑存储,我们将数据储存到cvs中。
使用xlwt将数据写入excel文件中,xlwt基本应用实例:
import xlwt
#创建可写的workbook对象
workbook = xlwt.Workbook(encoding='utf-8')
#创建工作表sheet
worksheet = workbook.add_sheet('sheet1')
#往表中写内容,第一个参数 行,第二个参数列,第三个参数内容
worksheet.write(0, 0, 'bigsai')
#保存表为test.xlsx
workbook.save('test.xlsx')
使用xlrd读取excel文件中,本案例xlrd基本应用实例:
import xlrd
#读取名称为test.xls文件
workbook = xlrd.open_workbook('test.xls')
# 获取第一张表
table = workbook.sheets()[0] # 打开第1张表
# 每一行是个元组
nrows = table.nrows
for i in range(nrows):
print(table.row_values(i))#输出每一行
到这里,我们对登录模块+爬取模块+存储模块就可把数据存到本地了,具体整合的代码为:
import requests
from bs4 import BeautifulSoup
import urllib.parse
import xlwt
import xlrd
# 账号密码
def login(username, password):
url = 'https://accounts.douban.com/j/mobile/login/basic'
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',
'Referer': 'https://accounts.douban.com/passport/login_popup?login_source=anony',
'Origin': 'https://accounts.douban.com',
'content-Type': 'application/x-www-form-urlencoded',
'x-requested-with': 'XMLHttpRequest',
'accept': 'application/json',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'connection': 'keep-alive'
, 'Host': 'accounts.douban.com'
}
# 登陆需要携带的参数
data = {
'ck' : '',
'name': '',
'password': '',
'remember': 'false',
'ticket': ''
}
data['name'] = username
data['password'] = password
data = urllib.parse.urlencode(data)
print(data)
req = requests.post(url, headers=header, data=data, verify=False)
cookies = requests.utils.dict_from_cookiejar(req.cookies)
print(cookies)
return cookies
def getcomment(cookies, mvid): # 参数为登录成功的cookies(后台可通过cookies识别用户,电影的id)
start = 0
w = xlwt.Workbook(encoding='ascii') # #创建可写的workbook对象
ws = w.add_sheet('sheet1') # 创建工作表sheet
index = 1 # 表示行的意思,在xls文件中写入对应的行数
while True:
# 模拟浏览器头发送请求
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',
}
# try catch 尝试,一旦有错误说明执行完成,没错误继续进行
try:
# 拼凑url 每次star加20
url = 'https://movie.douban.com/subject/' + str(mvid) + '/comments?start=' + str(
start) + '&limit=20&sort=new_score&status=P&comments_only=1'
start += 20
# 发送请求
req = requests.get(url, cookies=cookies, headers=header)
# 返回的结果是个json字符串 通过req.json()方法获取数据
res = req.json()
res = res['html'] # 需要的数据在`html`键下
soup = BeautifulSoup(res, 'lxml') # 把这个结构化html创建一个BeautifulSoup对象用来提取信息
node = soup.select('.comment-item') # 每组class 均为comment-item 这样分成20条记录(每个url有20个评论)
for va in node: # 遍历评论
name = va.a.get('title') # 获取评论者名称
star = va.select_one('.comment-info').select('span')[1].get('class')[0][-2] # 星数好评
votes = va.select_one('.votes').text # 投票数
comment = va.select_one('.short').text # 评论文本
print(name, star, votes, comment)
ws.write(index, 0, index) # 第index行,第0列写入 index
ws.write(index, 1, name) # 第index行,第1列写入 评论者
ws.write(index, 2, star) # 第index行,第2列写入 评星
ws.write(index, 3, votes) # 第index行,第3列写入 投票数
ws.write(index, 4, comment) # 第index行,第4列写入 评论内容
index += 1
except Exception as e: # 有异常退出
print(e)
break
w.save('test.xls') # 保存为test.xls文件
if __name__ == '__main__':
username = input('输入账号:')
password = input('输入密码:')
cookies = login(username, password)
mvid = input('电影的id为:')
getcomment(cookies, mvid)
执行之后成功存储数据:

可视化分析
我们要对评分进行统计、词频统计。还有就是生成词云展示。而对应的就是matplotlib、WordCloud库。
实现的逻辑思路:读取xls的文件,将评论使用分词处理统计词频,统计出现最多的词语制作成直方图和词语。将评星🌟数量做成饼图展示一下,主要代码均有注释,具体的代码为:
其中代码为:
import matplotlib.pyplot as plt
import matplotlib
import jieba
import jieba.analyse
import xlwt
import xlrd
from wordcloud import WordCloud
import numpy as np
from collections import Counter
# 设置字体 有的linux字体有问题
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
# 类似comment 为评论的一些数据 [ ['1','名称','star星','赞同数','评论内容'] ,['2','名称','star星','赞同数','评论内容'] ]元组
def anylasescore(comment):
score = [0, 0, 0, 0, 0, 0] # 分别对应0 1 2 3 4 5分出现的次数
count = 0 # 评分总次数
for va in comment: # 遍历每条评论的数据 ['1','名称','star星','赞同数','评论内容']
try:
score[int(va[2])] += 1 # 第3列 为star星 要强制转换成int格式
count += 1
except Exception as e:
continue
print(score)
label = '1分', '2分', '3分', '4分', '5分'
color = 'blue', 'orange', 'yellow', 'green', 'red' # 各类别颜色
size = [0, 0, 0, 0, 0] # 一个百分比数字 合起来为100
explode = [0, 0, 0, 0, 0] # explode :(每一块)离开中心距离;
for i in range(1, 5): # 计算
size[i] = score[i] * 100 / count
explode[i] = score[i] / count / 10
pie = plt.pie(size, colors=color, explode=explode, labels=label, shadow=True, autopct='%1.1f%%')
for font in pie[1]:
font.set_size(8)
for digit in pie[2]:
digit.set_size(8)
plt.axis('equal') # 该行代码使饼图长宽相等
plt.title(u'各个评分占比', fontsize=12) # 标题
plt.legend(loc=0, bbox_to_anchor=(0.82, 1)) # 图例
# 设置legend的字体大小
leg = plt.gca().get_legend()
ltext = leg.get_texts()
plt.setp(ltext, fontsize=6)
plt.savefig("score.png")
# 显示图
plt.show()
def getzhifang(map): # 直方图二维,需要x和y两个坐标
x = []
y = []
for k, v in map.most_common(15): # 获取前15个最大数值
x.append(k)
y.append(v)
Xi = np.array(x) # 转成numpy的坐标
Yi = np.array(y)
width = 0.6
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.figure(figsize=(8, 6)) # 指定图像比例: 8:6
plt.bar(Xi, Yi, width, color='blue', label='热门词频统计', alpha=0.8, )
plt.xlabel("词频")
plt.ylabel("次数")
plt.savefig('zhifang.png')
plt.show()
return
def getciyun_most(map): # 获取词云
# 一个存对应中文单词,一个存对应次数
x = []
y = []
for k, v in map.most_common(300): # 在前300个常用词语中
x.append(k)
y.append(v)
xi = x[0:150] # 截取前150个
xi = ' '.join(xi) # 以空格 ` `将其分割为固定格式(词云需要)
print(xi)
# backgroud_Image = plt.imread('') # 如果需要个性化词云
# 词云大小,字体等基本设置
wc = WordCloud(background_color="white",
width=1500, height=1200,
# min_font_size=40,
# mask=backgroud_Image,
font_path="simhei.ttf",
max_font_size=150, # 设置字体最大值
random_state=50, # 设置有多少种随机生成状态,即有多少种配色方案
) # 字体这里有个坑,一定要设这个参数。否则会显示一堆小方框wc.font_path="simhei.ttf" # 黑体
# wc.font_path="simhei.ttf"
my_wordcloud = wc.generate(xi) #需要放入词云的单词 ,这里前150个单词
plt.imshow(my_wordcloud) # 展示
my_wordcloud.to_file("img.jpg") # 保存
xi = ' '.join(x[150:300]) # 再次获取后150个单词再保存一张词云
my_wordcloud = wc.generate(xi)
my_wordcloud.to_file("img2.jpg")
plt.axis("off")
def anylaseword(comment):
# 这个过滤词,有些词语没意义需要过滤掉
list = ['这个', '一个', '不少', '起来', '没有', '就是', '不是', '那个', '还是', '剧情', '这样', '那样', '这种', '那种', '故事', '人物', '什么']
print(list)
commnetstr = '' # 评论的字符串
c = Counter() # python一种数据集合,用来存储字典
index = 0
for va in comment:
seg_list = jieba.cut(va[4], cut_all=False) ## jieba分词
index += 1
for x in seg_list:
if len(x) > 1 and x != '\r\n': # 不是单个字 并且不是特殊符号
try:
c[x] += 1 # 这个单词的次数加一
except:
continue
commnetstr += va[4]
for (k, v) in c.most_common(): # 过滤掉次数小于5的单词
if v < 5 or k in list:
c.pop(k)
continue
# print(k,v)
print(len(c), c)
getzhifang(c) # 用这个数据进行画直方图
getciyun_most(c) # 词云
# print(commnetstr)
def anylase():
data = xlrd.open_workbook('test.xls') # 打开xls文件
table = data.sheets()[0] # 打开第i张表
nrows = table.nrows # 若干列的一个集合
comment = []
for i in range(nrows):
comment.append(table.row_values(i)) # 将该列数据添加到元组中
# print(comment)
anylasescore(comment)
anylaseword(comment)
if __name__ == '__main__':
anylase()
我们再来查看一下执行的效果:
这里我选了姜子牙和千与千寻 电影的一些数据,两个电影评分比例对比为:
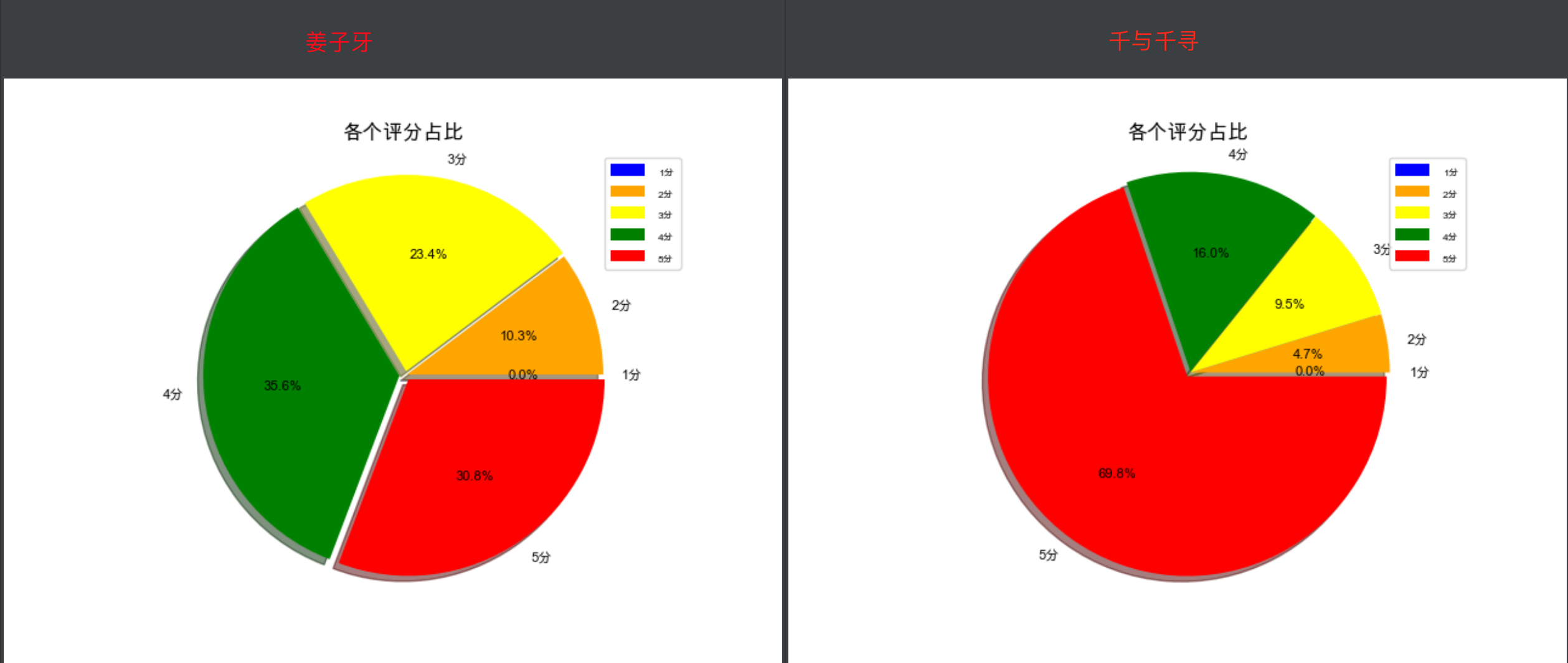
从评分可以看出明显千与千寻好评度更高,大部分人愿意给他五分。基本算是最好看的动漫之一了,再来看看直方图的词谱:
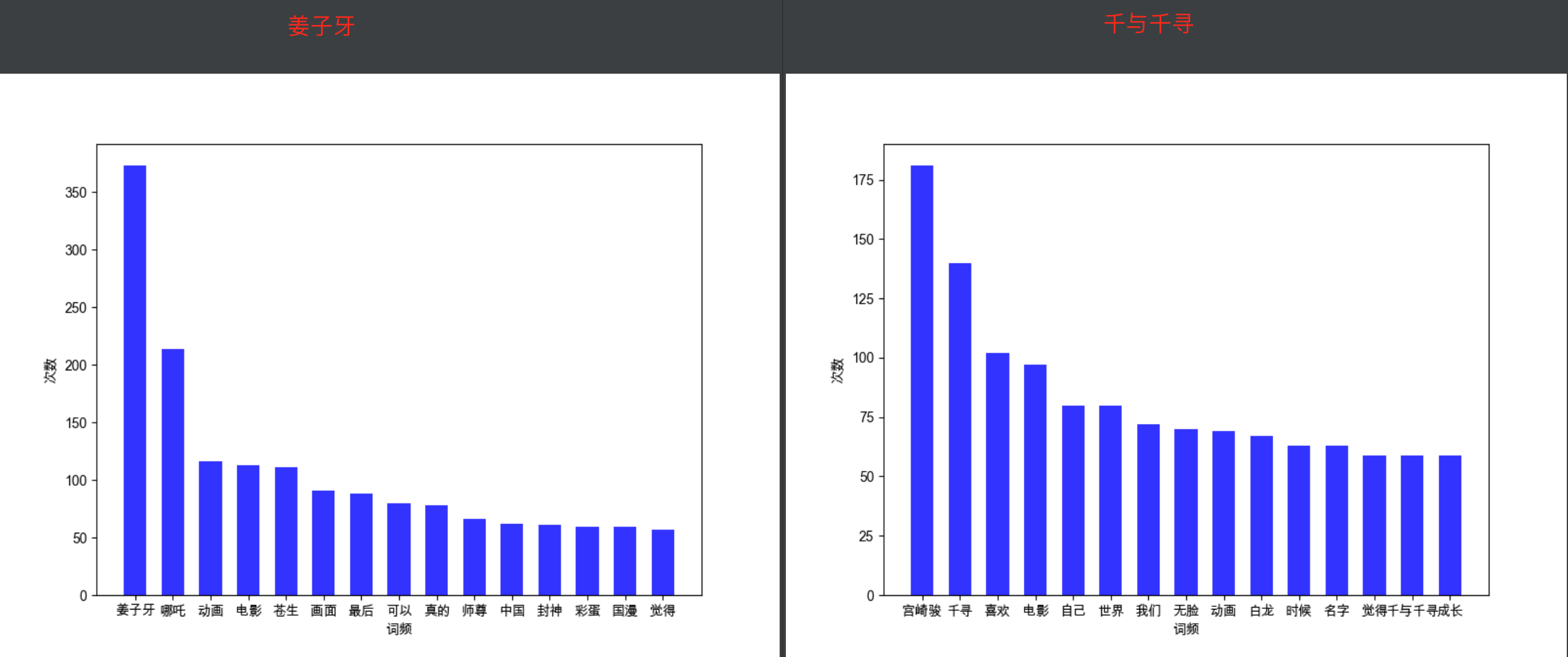
很明显千与千寻的作者更出名,并且有很大的影响力,以至于大家纷纷提起他。再看看两者词云图:

宫崎骏、白龙、婆婆,真的是满满的回忆,好了不说了,有啥想说的欢迎讨论!
如果感觉不错,点赞、一键三连 原创公众号:bigsai,分享知识和干货!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号