全国行政区划代码
爬取国家统计局统计用区划代码和城乡划分代码 2023 版
⚠️链接失效,原因如下
还好我
备份了数据且增加了坐标系等内容,需要的可以联系我!
| 项目 | 明细 |
|---|---|
| 提交时间 | 2024-11-13 |
| 主题 | 行政区划查询失效 |
| 咨询内容 | 行政区划查询页面失效 提示404,最新查询行政区划的页面在哪? 失效链接 http://www.stats.gov.cn/sj/tjbz/tjyqhdmhcxhfdm/2023/index.html |
| 答复内容 | 您好!根据国务院批复同意的《关于统计上划分城乡的规定》(国函〔2008〕60号)及国家统计局印发的《统计用区划代码和城乡划分代码编制规则》(国统字〔2009〕91号),统计用区划代码和城乡划分代码是开展各项普查、全面统计、抽样调查、专项调查等统计工作的基础,属于工作中使用的内部资料,不适用于向全社会公开。根据国家统计局政府信息公开相关要求,自2024年10月起,国家统计局继续公开《关于统计上划分城乡的规定》《统计用区划代码和城乡划分代码编制规则》等统计标准方法,不再公开具体相关代码。 另外,行政区划由民政部负责,建议您咨询该部门。感谢您对统计工作的关注和支持! |
| 答复单位 | 国家统计局统计资料管理中心 |
| 答复时间 | 2024-11-14 |
| 办理状态 | 已办结 |
python 实现
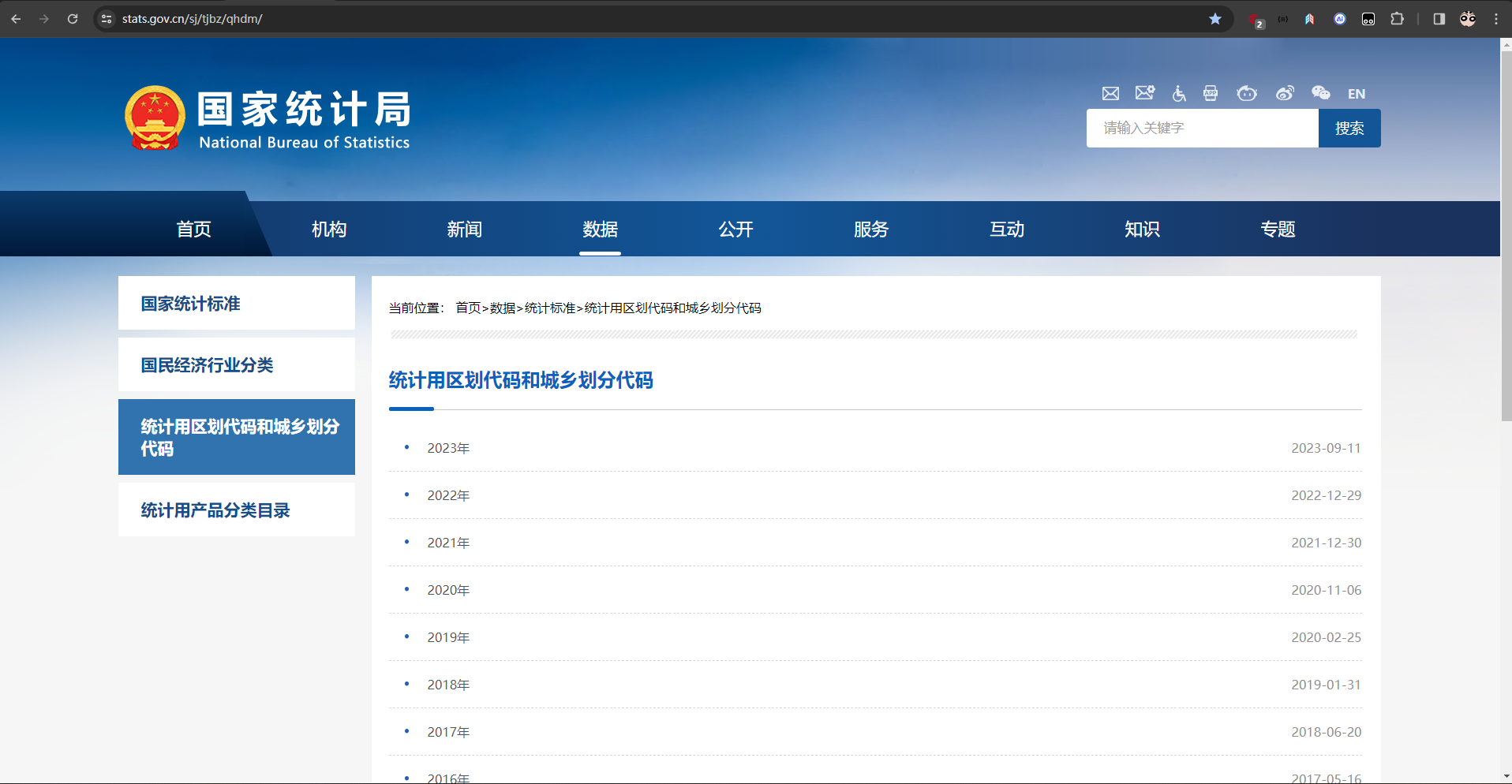
一、打开国家统计局官网
https://www.stats.gov.cn/sj/tjbz/qhdm/
二、分析每一级URL找到规律
省级:https://www.stats.gov.cn/sj/tjbz/tjyqhdmhcxhfdm/2023/index.html
地市级:https://www.stats.gov.cn/sj/tjbz/tjyqhdmhcxhfdm/2023/61.html 61为陕西编码
区县级:https://www.stats.gov.cn/sj/tjbz/tjyqhdmhcxhfdm/2023/61/6101.html
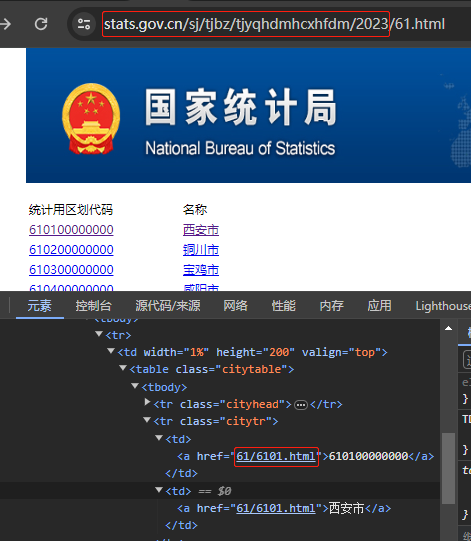
找到规律 当前路径+href 路径即可跳入下一级
打码
import json
import time
import requests
from bs4 import BeautifulSoup
main_url = "https://www.stats.gov.cn/sj/tjbz/tjyqhdmhcxhfdm/2023"
class area_code:
name = ""
code = ""
url = ""
child = []
urban_rural_type = 0
lng = 0
lat = 0
def __init__(self, name, code, url, child, urban_rural_type=0):
self.name = name
self.code = code
self.url = url
self.child = child
self.urban_rural_type = urban_rural_type
self.lng = 0
self.lat = 0
# 爬取全国统计用区划代码和城乡划分代码
# pip install beautifulsoup4
def get_code(suffix_url="index.html"):
_province_url = "{}/{}".format(main_url, suffix_url)
response = requests.get(_province_url)
response.encoding = "utf-8"
_html = response.text
_soup = BeautifulSoup(_html, "html.parser")
_province_code = {}
for a in _soup.find_all("a"):
if a.get("href") and a.get("href").endswith(".html"):
_province_code[a.text] = a.get("href")
return _province_code
def get_child_code(_url, _parent_url=None, _retry=3):
"""
输出 [{name:"呼和浩特市", code:"150100000000", url:"15/1501.html"},{name:"包头市", code:"150200000000", url:"15/1502.html"}]
:param _parent_url: 父级url
:param _retry: 重试次数
:param _url: 当前url
:return:
"""
_city_code = []
if _parent_url is not None and len(_parent_url) > 0:
# 截取最后一个"/"之前的字符串
_parent_path = _parent_url.rsplit("/", 1)[0]
_req_url = "{}/{}".format(_parent_path, _url)
else:
_req_url = "{}/{}".format(main_url, _url)
try:
response = requests.get(_req_url)
except Exception as e:
if _retry > 0:
time.sleep(1)
print("请求出错:{},第{}次重试".format(e, 4 - _retry))
return get_child_code(_url, _parent_url, _retry - 1)
else:
raise e
response.encoding = "utf-8"
_html = response.text
_soup = BeautifulSoup(_html, "html.parser")
# class_="citytr" or class_="towntr" or class_="countytr" or class_="villagetr"
for tr in _soup.find_all("tr", class_=["citytr", "towntr", "countytr"]):
_tds = tr.find_all("td")
print("开始处理 - {}".format(_tds[1].text))
_child_url = ""
if _tds[0].find("a") is not None and _tds[0].find("a").get("href") is not None:
_child_url = _tds[0].find("a").get("href")
if _child_url.endswith(".html"):
_child = get_child_code(_child_url, _req_url)
_city_code.append(area_code(_tds[1].text, _tds[0].text, _child_url, _child))
else:
_city_code.append(area_code(_tds[1].text, _tds[0].text, _child_url, []))
for tr in _soup.find_all("tr", class_=["villagetr"]):
_tds = tr.find_all("td")
code = _tds[0].text
urban_rural_type = _tds[1].text
name = _tds[2].text
_city_code.append(area_code(name, code, "", [], urban_rural_type))
return _city_code
def get_province_list():
"""
# 获取省份、直辖市、自治区代码
:return:
"""
province_map = get_code()
_province_list = []
for _name, _url in province_map.items():
_province_list.append(area_code(_name, _url.split(".")[0], _url, []))
return _province_list
if __name__ == '__main__':
province_list = get_province_list()
# 获取市级代码
for province in province_list:
print("开始处理 - {}".format(province.name))
city_code = get_child_code(province.url)
province.child = city_code
# 输出到文件json
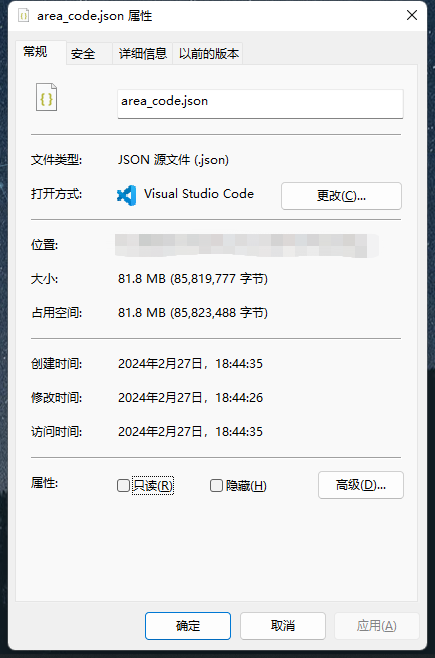
with open("area_code.json", "w", encoding="utf-8") as f:
f.write(json.dumps(province_list, default=lambda obj: obj.__dict__, ensure_ascii=False))
缺陷
- json格式太大了,建议直接入库或者生成csv
- 不支持退出续爬,后续完善....
本文来自博客园,作者:bigroc,转载请注明原文链接:https://www.cnblogs.com/bigroc/p/18037559
blog:http://www.bigroc.cn 博客园:https://www.cnblogs.com/bigroc
 浙公网安备 33010602011771号
浙公网安备 33010602011771号