
[量化学院]价值选股策略——基于机器学习算法
文献回顾
回顾价值策略
价值策略通俗地讲就是买入便宜股票,卖出昂贵股票,思想非常简单和直观。但是实际操作上这非常困难,因为我们没办法直接观察股票的真实价值。投资者可以从不同的视角采用不同的指标来估计股票内在价值。在股票市场中,最传统的方法就是通过会计报表的各个条目得到企业估值,我们可以从资产负债表得到市净率,从利润表得到资产收益率,从现金流量表得到现金流比率。Ma和Smith(2014)在《Sorting through the trash》中提到通过市净率、预测下期资产收益率和股价/现金流这三个指标合成一个综合的“价值”因子,可以显著提升策略表现(MA采取了三个因子Z得分的总和来合成“价值”因子),文末附实现源码,可在人工智能量化投资平台进行实现。
是否可以对公允价值进行建模?
虽然有很多种企业估值方法,2017年8月J.P.Morgan发表了文章《Value Strategies based on Machine Learning》,提出了一种通过大量股票特征来预测公司市净率的统计建模方法。换句话说,作者是通过预测公司市净率,然后与实际市净率进行比较来得到“公允价值”,以便发现哪些被“错误定价”的股票,识别出哪些股票被高估,哪些股票被低估,然后开发出买入低估股票,卖出高估股票的策略。
为什么要预测市净率?
首先,市净率本身就是公司估值的一个常用指标,并被Ma和Smith实践证明是企业价值很好的一个度量。其次,市净率这样的指标来自于财务指标,而财务指标通常很长一段时间才发生变化,因此比较稳定。最后,机器学习、深度学习策略被怀疑的很大一个原因就是行情数据信噪比低,因此财务数据信噪比较高,建模更有效。
价值选股策略
我们在11月介绍过J.P.Morgan关于机器学习进行股票策略开发的最新文章《Value Strategies based on Machine Learning》(基于机器学习的价值投资策略)。与常规算法预测目标不同,该文选择股票“公允价值”作为预测目标。作者选择37个股票特征作为输入数据,使用由惩罚回归(LASSO),梯度提升(XGBoost)和线性回归3个模型组成的组合模型,以MSCI国家指数中股票为投资标的,预测股票下个月的“公允价值”——市净率。以预测市净率与当前市净率之差作为“错误定价”的判断依据选股,买入被低估的股票,卖出被高估的股票。然后,作者发现使用毛利润与资产之比(Gross-Profit-to-Assets,GP/A)而不是净资产收益率(ROE)作为衡量盈利能力的标准,在需买入的低估值股票中,保留前40%GP/A的股票;在需卖出的高估值股票中,保留后40%GP/A的股票,能够在价值策略的基础上有所改善。最后,作者通过选择RavenPack新闻情绪数据作为交易策略的补充,建立情绪型号: 选取时间相关性(“Relevance”)数值在70以上的事件,求取月份情绪值。通过计算不同情绪值阈值对组合效果进行验证,发现移除买入组合中情绪值小于-0.3的股票,移除卖出组合中情绪大于0.3的股票的交易策略能进一步改善价值策略。
研究计划
我们希望能够将J.P.Morgan的价值策略运用在中国A股市场,验证该策略的有效性。策略思路和J.P.Morgan一致,通过大量的股票特征来预测市净率因子,然后根据预测出来的市净率因子与实际市净率之差作为股票“错误定价”的依据,然后买入被低估的股票,卖出高估的股票。
数据和算法
数据获取
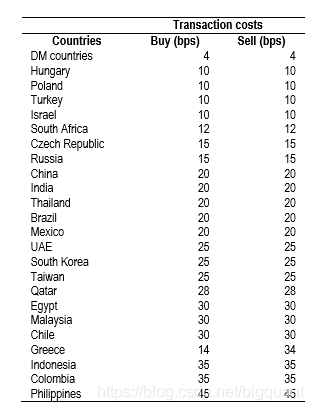
Morgan选股池是来自于39个国家的2000只股票(见下表),但本文的选股池是全A股市场,目前已经超过3000只股票。我们获取2010年1月1日至2018年1月1日的全A市场所有股票数据,其中样本内数据为2010年1月1日至2015年1月1日,样本外数据为2015年1月1日至2018年1月1日。样本外的数据段即为回测的区间段。
特征确定
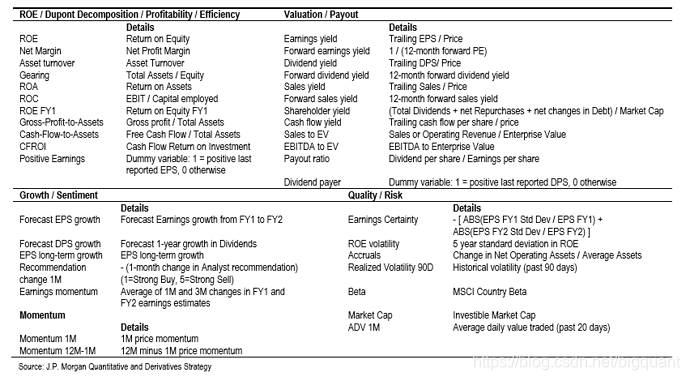
Morgan的原文中共有37个股票特征,这些特征主要反映了公司的盈利能力、运营效率、财务质量、成长性。见图1。
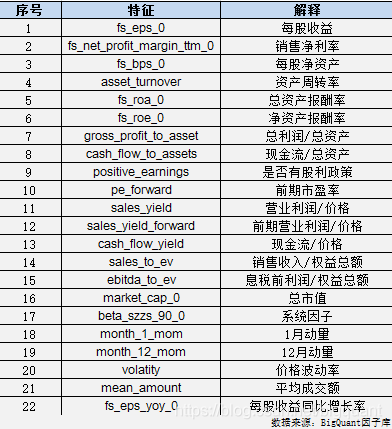
A股的财务报表和美股存在一些差异,我们选取了共22个股票特征来预测公司市净率。见图2。
数据标注
本文实验的目的是预测市净率来实现“公允价值”的建模,因此预测的重点是市净率,于是在训练集数据标注中,我们采取下一期的市净率数据作为标注依据。这样建模的直观意义是,我们希望找到24个股票特征与代表企业价值的市净率的内在关系,然后能够在样本外根据公司的24个特征预测市净率,挖掘出哪些公司可能被低估。
模型选择
本文选择以XGBoost算法建模,该算法全称为eXtreme Gradient Boosting,是在GBDT的基础上对boosting算法进行的改进,内部决策树使用的是回归树,该算法适用于分类和回归,主要优点是:速度快,效果好,能处理大规模数据,支持多种语言和自定义损失函数。仅在2015年,在Kaggle竞赛中获胜的29个算法中,有17个使用了XGBoost库,而作为对比,近年大热的深度神经网络方法,这一数据则是11个。在KDDCup 2015 竞赛中,排名前十的队伍全部使用了XGBoost库。XGBoost不仅学习效果很好,而且速度也很快,相比梯度提升算法在另一个常用机器学习库scikit-learn中的实现,XGBoost的性能经常有十倍以上的提升。
特征预处理
和Morgan思想一致,本文也是预测一年之后的市净率。鉴于国内A股公司最迟在次年4月最后一天发布上一年财务报表,因此我们以次年5月第一个交易日为月份T,预测T+12月份的市净率数据。本文会对24个股票特征数据进行去极值和横截面标准化处理。“公允价值”被定义为T+12月市净率减去T期市净率,为了保证数据的可比性,参照了Morgan的处理方法——也对“公允价值”进行了横截面标准化处理以便发现哪些是低估股票,哪些是高估股票。
训练和预测
模型训练
我们将训练集内80%的数据拿来训练模型,剩下数据拿来验证模型。为了防止机器学习算法XGBoost对训练数据过拟合,我们模型超参数采取了常规设置。其中比较重要的几个参数为:树的最大深度(max_depth设置为3),学习速率(eta设置为0.1),提升树的数量(n_estimators设置为100),因为我们想预测市净率的具体数值,所以采用回归算法(objective设置为reg:linear),预测连续性变量,迭代数量(num_round设置为100)。
模型预测
当我们训练出XGBoost模型后,根据样本外(2015年1月1日至2018年1月1日包含24个特征的股票数据,直接将该模型用来预测该时间区间上的股票市净率数据。
公允价值
“公允价值”的计算为预测市净率数据和实际市净率之差,具体计算公式为:
![Sj,t=E[PBj,t+1]−PBj,tσj,t](https://img-blog.csdnimg.cn/20181219183736115.png)
因为在训练集数据标注时,我们采取的是T+12月的市净率数据,因此预测市净率即为T+12月的市净率数据,实际市净率为T月市净率,为了便于股票之间的“公允价值”可以比较,我们对“公允价值”进行标准化——将预测市净率与实际市净率之差再除以过去12个月市净率的标准差。
回测交易
我们根据预测的“公允价值”进行选股,“公允价值”越高的股票越值得投资。和Morgan选股处理一样,选股时有两个过滤条件,首先,不买入流通市值最小的10%的股票,其次,不买入过去一个月平均成交金额最低的10%的股票。
我们根据预测的“公允价值”进行选股,“公允价值”越高的股票越值得投资。和Morgan选股处理一样,选股时有两个过滤条件,首先,不买入流通市值最小的10%的股票,其次,不买入过去一个月平均成交金额最低的10%的股票。
因为是通过年报出来之后的5月第一个交易日预测下一年的市净率数据来计算“公允价值”选股,因此调仓周期为1年。持有一年之后,再根据新的选股结果进行调仓。回测结果如下:
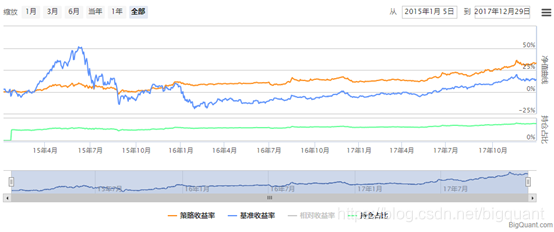
策略年化收益10.27%,最大回撤为11.54%,年化波动率为9.22%。Morgan测试结果年化收益3.2%,最大回撤为6.7%,年化波动率为3.6%。相比之下,中国市场的价值投资策略收益更高、风险也更高。
参考文献
- 《Value Strategies based on Machine Learning》
- 《Big Data and AI Strategies》
- 《XGBoost 入门系列第一讲》
- XGBboost Python API

 浙公网安备 33010602011771号
浙公网安备 33010602011771号