
LSTM Networks应用于股票市场探究【附源码】

摘要:BigQuant人工智能量化投资平台上的StockRanker算法在选股方面有不俗的表现,模型在15、16年的回测收益率也很高(使用默认因子收益率就达到170%左右)。然而,StockRanker在股灾时期回撤很大(使用默认因子回撤55%),因此需要择时模型,控制StockRanker在大盘走势不好时的仓位。 LSTM(长短期记忆神经网络)是一种善于处理和预测时间序列相关数据的RNN。本文初步探究了LSTM在股票市场的应用,进而将LSTM对沪深300未来五日收益率的预测作为择时器并与StockRanker结合使用,在对回测收益率有较好保证的前提下,较为显著地降低了StockRanker的回撤。
LSTM Networks(长短期记忆神经网络)简介
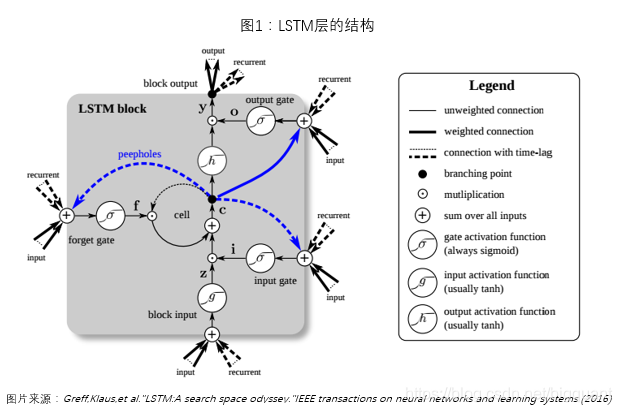
LSTM Networks是递归神经网络(RNNs)的一种,该算法由Sepp Hochreiter和Jurgen Schmidhuber在Neural Computation上首次公布。后经过人们的不断改进,LSTM的内部结构逐渐变得完善起来(图1)。在处理和预测时间序列相关的数据时会比一般的RNNs表现的更好。目前,LSTM Networks已经被广泛应用在机器人控制、文本识别及预测、语音识别、蛋白质同源检测等领域。基于LSTM Networks在这些方面的优异表现,本文旨在探究LSTM是否可以应用于股票时间序列的预测。
LSTM Networks处理股票时间序列的流程
本文使用的LSTM处理股票序列的流程如图2。本文的整体流程均在BigQuant量化投资平台上进行,构建LSTM模型使用库主要为Keras。
数据获取与处理:对于时间序列,我们通常会以[X(t-n),X(t-n+1),…,X(t-1),X(t)]这n个时刻的数据作为输入来预测(t+1)时刻的输出。对于股票来说,在t时刻会有若干个features,因此,为了丰富features以使模型更加精确,本文将n(time series)×s(features per time series)的二维向量作为输入。LSTM对于数据标准化的要求很高,因此本文所有input数据均经过z-score标准化处理。
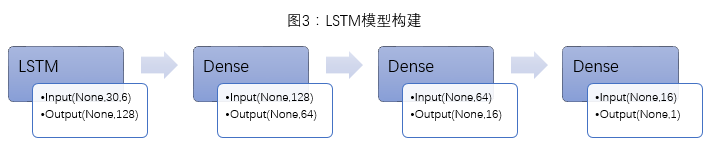
LSTM模型构建:作为循环层的一种神经网络结构,只使用LSTM并不能构建出一个完整的模型,LSTM还需要与其他神经网络层(如Dense层、卷积层等)配合使用。此外,还可以构建多层LSTM层来增加模型的复杂性。
回测:本文进行的回测分为两种,一是直接将LSTM输出结果作为做单信号在个股上进行回测,二是将LSTM的预测结果作为一种择时信号,再配合其他选股模型(如BigQuant平台的StockRanker)进行回测。

LSTM应用股票市场初探
之前我们做过LSTM应用于股票市场的初步探究(《基于LSTM的股票价格预测模型 》),使用方法为利用沪深300前100天的收盘价预测下一天的收盘价。从结果来看,LSTM对未来20天的预测基本上是对过去100天收盘价变化的趋势的总括,因此最终的预测结果以及回测结果都不是很理想。 之后尝试增加了features(每日Open,High,Low,Close,Amount,Volume),效果依然不是很好。
通过对结果进行分析以及阅读研究一些研报,得到的初步结论为:一是input时间跨度太长(100天的价格走势对未来一天的价格变化影响很小),而待预测数据时间跨度太短;二是收盘价(Close)是非平稳数据,LSTM对于非平稳数据的预测效果没有平稳数据好。
LSTM对沪深300未来五日收益率预测
综合以上两点,本文所使用的输入和输出为利用过去30天的数据预测将来五天的收益。
测试对象:沪深300
数据选择和处理:
-
input的时间跨度为30天,每天的features为[‘close’,‘open’,‘high’,‘low’,‘amount’,‘volume’]共6个,因此每个input为30×6的二维向量。
-
output为未来5日收益future_return_5(future_return_5>0.2,取0.2;future_return_5<-0.2,取-0.2),为使训练效果更加明显,output=future_return_5×10; features均经过标准化处理(在每个样本内每个feature标准化处理一次)。
-
训练数据:沪深300 2005-01-01至2014-12-31时间段的数据;测试数据:沪深300 2015-01-01至2017-05-01时间段数据。
-
模型构建:鉴于数据较少(训练数据约2500个,预测数据约500个),因此模型构建的相对简单。模型共四层,为一层LSTM层+三层Dense层(图3)。
-
回测:得到LSTM预测结果后,若LSTM预测值小于0,则记为-1,若大于0,记为1。
每个模型做两次回测,第一次回测(后文简称回测1)为直接以LSTM预测值在沪深300上做单:若LSTM预测值为1,买入并持有5day(若之前已持仓,则更新持有天数),若LSTM预测值为-1,若为空仓期,则继续空仓,若已持有股票,则不更新持有天数;
第二次回测(后文简称回测2)为以LSTM为择时指标,与StockRanker结合在3000只股票做单:若LSTM预测值为1,则允许StockRanker根据其排序分数买入股票,若LSTM预测值为-1,若为空仓期,则继续空仓,若已持有股票,则禁止StockRanker买入股票,根据现有股票的买入时间,5天内清仓;
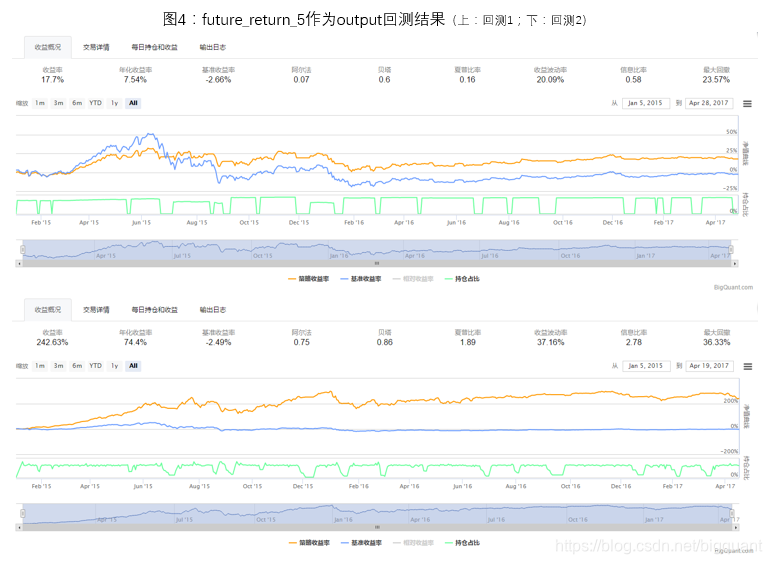
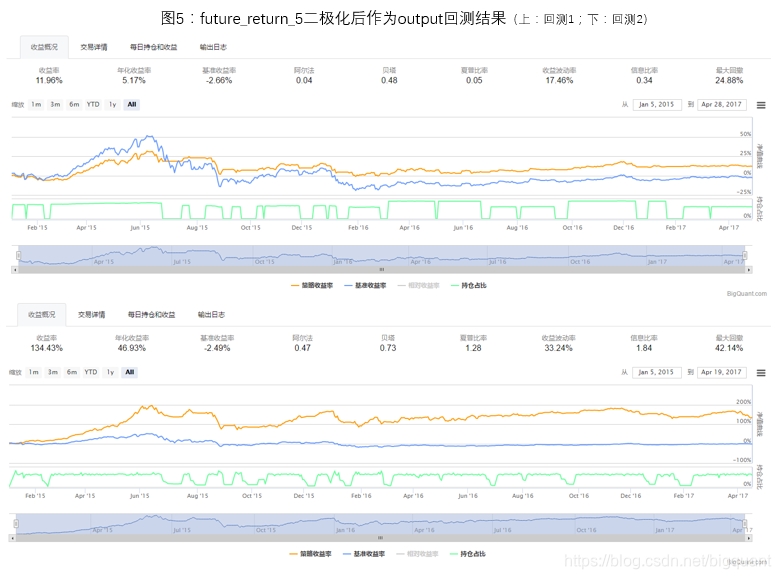
1)future_return_5是否二极化处理比较
对于future_return_5的处理分为两种情况,一种为直接将future_return_5作为output进行模型训练,二是将future_return_5二极化(future_return_5>0,取1;future_return_5<=0,取-1),然后将二极化后的数据作为output进行模型训练。
两种处理方法的回测情况如图4,图5。由于模型每次初始化权重不一样,每次预测和回测结果会有一些差别,但经过多次回测统计,直接将future_return_5作为output进行模型训练是一个更好的选择。在本文接下来的讨论中,将会直接将future_return_5作为output进行模型训练。
2)在权重上施加正则项探究
神经网络的过拟合:在训练神经网络过程中,“过拟合”是一项尽量要避免的事。神经网络“死记”训练数据。过拟合意味着模型在训练数据的表现会很好,但对于训练以外的预测则效果很差。原因通常为模型“死记”训练数据及其噪声,从而导致模型过于复杂。本文使用的沪深300的数据量不是太多,因此防止模型过拟合就尤为重要。
训练LSTM模型时,在参数层面上有两个十分重要的参数可以控制模型的过拟合:Dropout参数和在权重上施加正则项。Dropout是指在每次输入时随机丢弃一些features,从而提高模型的鲁棒性。它的出发点是通过不停去改变网络的结构,使神经网络记住的不是训练数据本身,而是能学出一些规律性的东西。正则项则是通过在计算损失函数时增加一项L2范数,使一些权重的值趋近于0,避免模型对每个feature强行适应与拟合,从而提高鲁棒性,也有因子选择的效果;(若希望在数学层面了解正则项更多知识,参考《机器学习中防止过拟合的处理方法》 。在1)的模型训练中,我们加入了Dropout参数来避免过拟合。接下来我们尝试额外在权重上施加正则项来测试模型的表现。
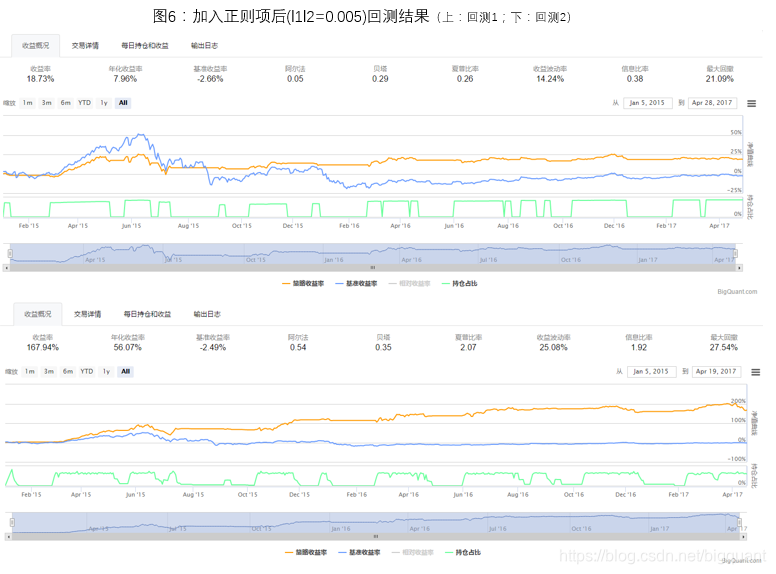
回测结果如图6,加入正则项之后回测1和回测2的最大回撤均有下降,说明加入正则项后确实减轻了模型的过拟合。比较加入正则项前后回测1的持仓情况,可以看到加入正则化后空仓期更长,做单次数减少(19/17),可以理解为:加入正则项之后,模型会变得更加保守。
正则项的问题:经过试验,对于一个LSTM模型来说,正则项的参数十分重要,调参也需要长时间尝试,不合适的参数选择会造成模型的预测值偏正分布(大部分预测值大于0)或偏负分布,从而导致预测结果不准确,而较好的正则参数会使模型泛化性非常好(图6所用参数训练出来的模型的预测值属于轻度偏正分布)。本文之后的讨论仍会基于未加权重正则项的LSTM模型。
3)双输入模型探究
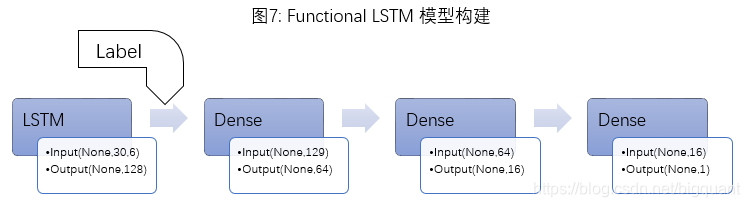
除了传统的Sequential Model(一输入,一输出)外,本文还尝试构建了Functional Model(支持多输入,多输出)。前面提到的features处理方法丢失了一项重要的信息:价格的高低。相同的input处在3000点和6000点时的future_return_5可能有很大不同。因此,本文尝试构建了"二输入一输出"的Functional Model:标准化后的features作为input输入LSTM层,LSTM层的输出结果和一个指标-label(label=np.round(close/500))作为input输入后面的Dense层,最终输出仍为future_return_5(图7)。
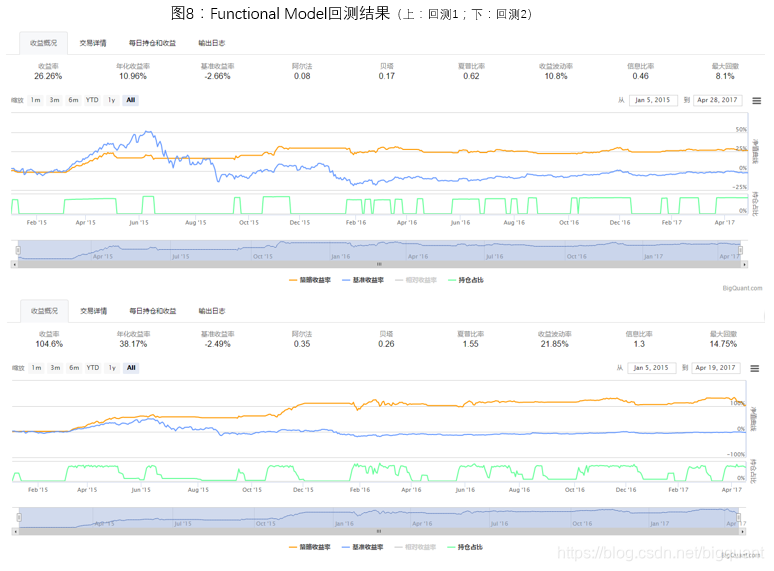
回测结果如图8。由回测结果可以看出,加入指示标后的LSTM模型收益率相对下降,但是回撤更小。LSTM预测值小于0的时间段覆盖了沪深300上大多数大幅下跌的时间段,虽然也错误地将一些震荡或上涨趋势划归为下跌趋势。或许这是不可避免的,俗话说高风险高回报,风险低那么回报也不会非常高,高回报和低风险往往不可兼得。
结论与展望
本文通过探究性地应用LSTM对沪深300未来五日收益率进行预测,初步说明了LSTM Networks是可以用在股票市场上的。
由于LSTM更适用于处理个股/指数,因此,将LSTM作为择时模型与其他选股模型配合使用效果较好。利用LSTM模型对沪深300数据进行预测并将结果作为择时信号,可以显著改善stockranker选股模型在回测阶段的回撤。
展望:由于个股数据量较少,LSTM模型的可扩展程度和复杂度受到很大制约,features的选择也受到限制(若input的features太多,而data较少的话,会使一部分features不能发挥出应有的作用,也极易造成过拟合)。将来我们希望能在个股/指数的小时或分钟数据上测试LSTM的性能。另外,将探究LSTM模型能否将属于一个行业的所有股票data一起处理也是一个可选的方向。
说明:由于每次训练LSTM模型权重更新情况不同以及Dropout的随机性,LSTM模型的每次训练训练结果都会有差异。
附:
提示:由于LSTM涉及参数众多,目前我们还不能保证LSTM模型的稳定性,本文所附回测结果均为多次训练模型后选取的较为理想的情况,目的是说明LSTM是可以应用于股票市场的以及将其作为择时模型是可能的。本文所述以及提供的代码仅供探究及讨论,若要形成一个在股票市场比较实用的LSTM模型,还需要在features选择、模型构建、模型参数选择以及调优等方面花费大量精力。
源代码:
实现平台: BigQuant——人工智能量化投资平台

 浙公网安备 33010602011771号
浙公网安备 33010602011771号