
过拟合详解:监督学习中不准确的“常识”
导语:本文为Mehmet Süzen撰写文章的译文,稍有删改。文章清晰地阐释和区分过度拟合及过度拟合等概念,对于本领域学习者正确理解专业术语多有帮助。正如作者在原文末所指出的:对待简单的概念,我们也应抱着积极求学的态度,了解其成立的基础。
前言
大多数从业者对”过拟合“这一概念存在误解。在数据科学界,始终存在一种类似于民间说法的观点:
“利用交叉验证可以防止过拟合。在样本外对模型进行验证,如果不存在泛化误差,则模型不存在过拟合”
这个说法显然是不对的:交叉验证并不能阻止模型过拟合。样本外的良好预测性能并不能保证模型不存在过拟合。在这个说法中,前部分说的概念其实是“过度训练”。不幸的是,这种快速传播的说法不仅仅在业界传播还在一些学术论文中出现。这是专业术语上的一种混淆,我们觉得有必要澄清“过拟合”这个专业术语的概念。
在本文,我们会给出直观的解释:为什么模型验证即获取最小的泛化误差与过拟合的检测不能在一个模型上同时得到解决。在明确一些概念介绍后,我们会举例说明,以帮助大家理解过度拟合,过度训练和典型的最终模型的建立步骤。
监督学习需要满足的条件:
数学最基本的任务之一是找到函数的解法:如果将其限制在n维实数域,则方程和答案均出于Rn。假设数据集中有p个数据点,分别命名为 xi,这些是方程的部分解。建模的目的是为了找到数据集的解,这意味着我们需要找到m个未知参数,a∈Rm。以数学的表达方式而言,构建一个方程:f(x,a)。这个方程被称为回归方程,插值方程或者监督学习方程,取决于你阅读的文献。这是反问题的一种形式,虽然我们不知道参数,但我们有部分变量的信息。最主要的问题在于不适定性,是指解答不适定,实际存在很多可以解释样本的函数f(x,a)。对于方程f(x,a)=0,需要满足两个要求:
-
普适性:模型验证,模型不能仅在样本集中使用
-
最小复杂度:模型选择,模型应该满足奥卡姆剃刀原理。
模型的普适性可以用拟合优度来衡量,表明模型能够在怎样的程度上解释样本。为达到最小复杂度,模型之间需要相互比较。
迄今为止,我们还未统一检测普适性并选择最佳模型的方法,需要数据科学家或者量化从业者通过个人经验进行判断。
模型验证
验证模型普适性的一个方法是提出可以衡量模型对于样本集的解释的度量标准。模型验证的主要目标为估计模型误差。比如,均方根误差(RMDS)是一个可以使用的度量标准。如果RMSD很低,表明拟合效果好,理想情况下RMDS应该接近于0。但如果我们只用样本集去衡量,不足以证明模型具有普适性,需要使用样本外数据进行检测参数 a a a。进一步,改进的方法是使用交叉验证,将样本集分为 k k k部分,我们可以获得 k k k个RMDS的平均值,如图1所示。
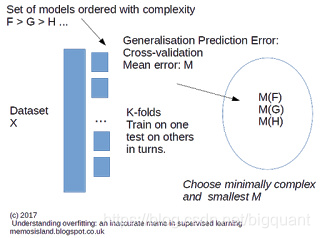
图 1 : 监 督 学 习 的 模 型 验 证 和 分 类 示 意 图1 :监督学习的模型验证和分类示意 图1:监督学习的模型验证和分类示意
模型选择:过拟合检测
当考虑满足“最小模型复杂度”时,过拟合是需要进行考虑的因素。多个模型进行比较来判断是否过拟合。Douglas Hawkins在他经典论文The Problem of Overfitting 中写道:
模型的过拟合常见的担忧,过拟合很难被辨识,因为它不是一个绝对的问题,需要比较才能得出。如果两个模型拟合优度相同但其中一个模型更加复杂,那么这个模型就过拟合了。
关键因素是“复杂模型”的含义是什么?我们如何定量确定“模型的复杂度”?不幸的是,这是没有确定的方法。大家公认的方法是:当一个模型有更多参数的时候,模型也就更加复杂。但是这个说法也是非正式的,通常也不准确。我们可以求助于复杂度的不同衡量方式,例如,函数 f 1 ( a , x ) = a x f_1(a,x)=ax f1(a,x)=ax和 f 2 ( a , x ) = a x 2 f_2(a,x)=ax^2 f2(a,x)=ax2,两个函数有相同的参数数量,但是 f 2 f_2 f2更加复杂,因为函数是非线性的。关于如何判定复杂度,这里有很多可以讨论的,但本文不做进一步介绍。为了下面的范例演示,我们认为模型参数越多,非线性度越强,则模型越复杂。
范例操作
上文已经直观地介绍为什么模型验证与过拟合判定不能同时完成的原因。在接受上文假设后,我们开始构造样本集和模型,以直观说明。
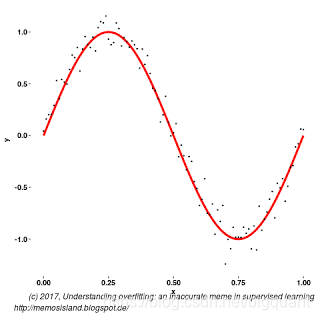
一般步骤为构建一个样本集,由某个模型生成,并将模型作为标准。然后利用样本集生成其他模型,我们构建如下形式的模型,但再添加一些高斯噪音:
f ( x ) = s i n ( 2 π x ) + N ( 0 , 0.1 ) f(x)= sin(2\pi x) + \mathcal{N}(0,0.1) f(x)=sin(2πx)+N(0,0.1)
g
(
x
)
=
a
0
+
a
1
x
+
a
2
x
2
+
a
3
x
3
g(x) = a_{0} + a_{1} x + a_{2} x^{2} + a_{3} x^{3}
g(x)=a0+a1x+a2x2+a3x3
和
h
(
x
)
=
b
0
+
b
1
x
+
b
2
x
2
+
b
3
x
3
+
b
4
x
4
+
b
5
x
5
+
b
6
x
6
.
h(x) = b_{0} + b_{1} x + b_{2} x^{2} + b_{3} x^{3} + b_{4} x^{4} + b_{5} x^{5} + b_{6} x^{6}.
h(x)=b0+b1x+b2x2+b3x3+b4x4+b5x5+b6x6.
过度训练
过度训练是指模型的拟合优度随着某一客观变量偏离最佳值而下降。比如,神经网络中的训练集样本大小。观察 g ( x ) g(x) g(x)训练结果,存在一个最佳的训练样本数量,使样本外数据的拟合优度最佳。
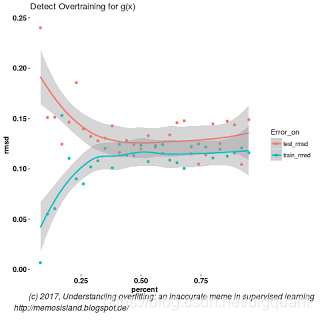
图 3 : 当 g ( x ) 的 训 练 样 本 集 数 量 超 过 40 图3:当g(x)的训练样本集数量超过40%产生过度训练 图3:当g(x)的训练样本集数量超过40
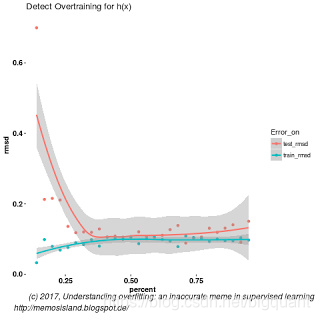
低泛化误差的过拟合
计算10倍交叉验证 g ( x ) g(x) g(x)和 f ( x ) f(x) f(x)的均方根误差,分别是0.13和0.12,结果显示:更加复杂的模型得到的拟合优度与相对简单的模型是一致的。我们不能通过均方根误差来或者是过度训练的曲线来判断过拟合,如图4。模型之间需要被比较,参考图3与图4曲线与均方根误差值。
选择使用哪个模型?
我们找到了具有良好拟合优度的最低复杂度的模型,但是我们应该采用哪个模型进行使用呢?在模型选择部分我们找到构造了模型,既然 g ( x ) g(x) g(x)和 h ( x ) h(x) h(x)具有相同拟合优度,那我们显然应该选择 g ( x ) g(x) g(x),并在图3中显示的最佳数量样本上进行训练。
结论
如本文实例所示,良好的拟合优度并不能保证模型没有过拟合,当人们谈论到”过拟合“时,他们说的往往是”过度训练“。
深度学习是一门实践学科,只有不断做实验才能有所进步。BigQuant人工智能量化投资平台 集成了众多深度学习/机器学习开源框架,包括TensorFlow、Keras、XGBoost、Theano、Caffe等,可以直接在BigQuant上开启你的深度学习之旅!
原文链接:《过拟合详解:监督学习中不准确的“常识” 》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号