
HMM 理论基础及金融市场的应用
贝叶斯定理到贝叶斯网
贝叶斯公式
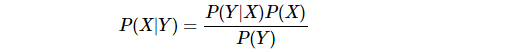
上面是我们耳熟能详的贝叶斯公式,为什么要从这个基本公式讲起呢?原因在于现代统计模型和概率模型的灵魂便是条件分布,而条件分布的理论基础便是这个简单的贝叶斯公式。
单纯讲数学未免太枯燥,我们用简单的例子来说明这个概念。比如我们有只股票S,简单起见,它只有两种状态{U,D},U和D分别表示上涨和下跌。如果我们想知道它每天上涨和下跌的概率,只需要简单得统计历史中上涨和下跌的天数就好了,看如下示意图
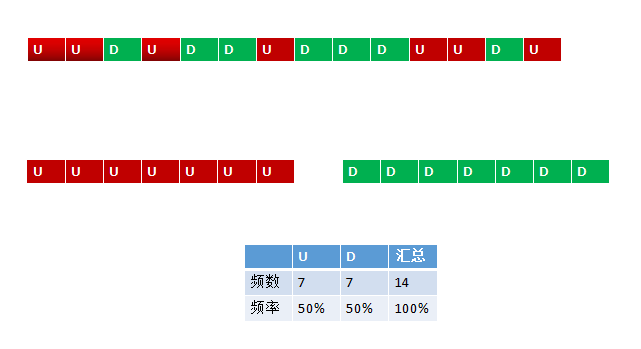
这个便是我们关于任意一天股票S涨跌X的后验分布:
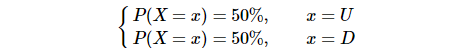
有些读者也许觉得不满意,这根本就是完全随机嘛,为什么不把昨天的涨跌数据算进去呢?当然可以,只不过这次我们要重新搜集事件样本,原来我们默认每天的涨跌作为一个事件并对其进行频数统计,现在我们要把两个连续的涨跌定义为一个事件。
下面的第一个是频数表格,行表示前一天的状态,即条件,列表示今天的状态,当我们把每一行的数据进行0-1正规化,便得到了我们右边的条件概率二联表,而我们对这个概率的计算方式正好就是贝叶斯公式:

这时候,我们的条件概率分布为:
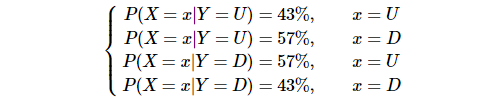
留意的读者会发现,我们的表格变成二维的了。当然,我们还可以继续扩展,比如把前一天的价格也考虑进去,我们的条件概率表变成三维的了,读者可以类比正方体(二维正好是四个方块构成的正方形)。
第一层表格代表前天价格上涨的情况,第二层表代表前天价格下跌的情况:

所以,大家可以看到,随着我们条件信息的增多,我们需要表示条件概率分布的复杂度也在呈现指数上升。在我们的例子里,复杂度为
2
n
2^n
2n,其中
n
n
n为条件信息的数量。
在这里的复杂度,我们可以理解为需要表示或存储条件概率分布的空间复杂度,也可以理解为我们需要估计的参数的数量。
这里我们还要再对比一下连续分布函数,对于条件连续分布,它的复杂性更多地不是空间复杂度,而是分析复杂度,超过一定的复杂度,很可能我们的理论框架和工具就很难处理了,或者没有必要。
贝叶斯网
在这里,基于我们的目的,我们暂且把贝叶斯网看成是一种对概率分布的建模工具或者可视化表述,下面举了一些例子:
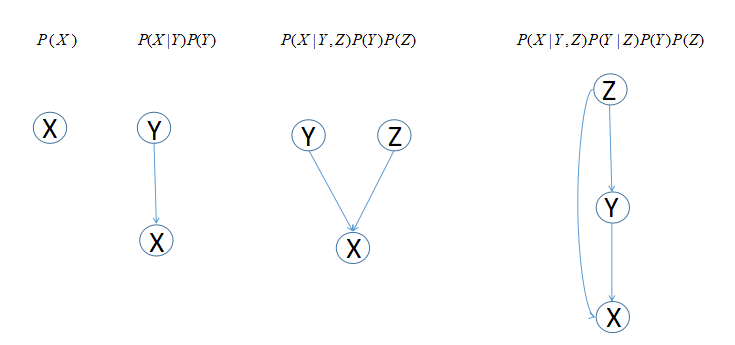
大家可以从上总结出一些规律,单变量分布代表“起始”节点,即没有进入箭头,只有出去的箭头。条件分布中的条件变量代表父节点,随机变量代表子节点。这样我们就发现,貌似所有的联合概率分布都可以用DAG(有向无环图)来表示。
那我们来尝试用DAG来表示一个序列(5个随机变量)的联合概率分布:

这个DAG一共有10条边,如果增加到6个随机变量,就有15条边,同理类推,n个随机变量就有
n
(
n
−
1
)
2
\frac{n(n-1)}{2}
2n(n−1)条边。而长度超过100的随机序列很正常,那将需要4950条边才能完整表述我们的联合概率分布,这里每一条边都代表一个我们需要建模的概率分布!
为了减少问题的复杂性,我们通过概率独立性和条件独立来解决这个问题。
隐含马尔科夫模型

没错,这个DAG就是隐含马尔科夫模型,我们只需要引入下面两个假设就能得到:
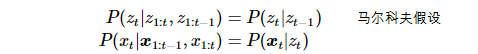
于是有联合概率分布:
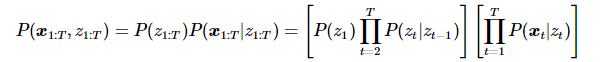
对于类似HMM的这类时序模型temporal models,有几个概念我们要总结一下:
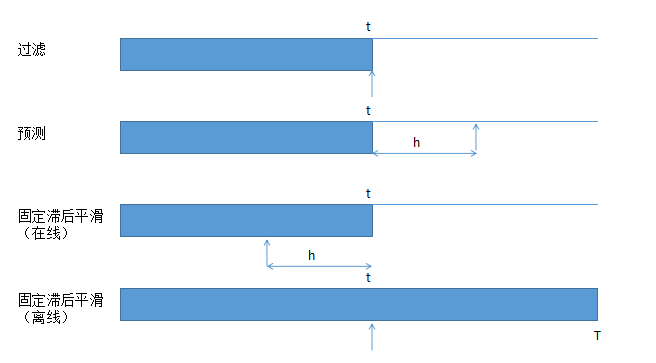
Filtering
Filtering相当于在线计算
P
(
z
t
∣
x
1
:
t
)
P(z_{t} | \boldsymbol{x}_{1:t})
P(zt∣x1:t)。Filtering我不知道正确的中文学名是什么,是滤波还是过滤,欢迎大家告诉我。
filtering其实就是用当前时间之前的所有历史数据(含当前时间的数据)去估计拟合状态最好的当前隐含状态。这里的当前要着重强调一下,“当前”可以代表实时时间(实时在线学习),
这代表当前时间是动态变化在,在模型学习和推断的时候也是一样。
Smoothing
Smoothing相当于离线计算 P ( z t ∣ x 1 : T ) P(z_{t} | \boldsymbol{x}_{1:T}) P(zt∣x1:T)。Smoothing中文学名叫平滑,大家可能很熟悉。它的意思就是利用相对于当前时间点所有的历史和未来数据,来估计当前的隐含状态。
Prediction
Prediction很自然就是基于当前及历史数据,预测未来隐含状态,即 P ( z t + h ∣ x 1 : t ) P(z_{t+h}|\boldsymbol{x}_{1:t}) P(zt+h∣x1:t)。
还有一种预测类型,就是预测未来观测值,即 P ( x t + h ∣ x 1 : t ) P(\boldsymbol{x}_{t+h} | \boldsymbol{x}_{1:t}) P(xt+h∣x1:t)。
MAP
这里的后验估计就是
a
r
g
m
a
x
z
1
:
T
P
(
z
1
:
T
∣
x
1
:
T
)
argmax_{z_{1:T}} P(z_{1:T} | \boldsymbol{x}_{1:T})
argmaxz1:TP(z1:T∣x1:T),即最有可能的状态序列。在HMM的框架里,Viterbi算法是最有名的一个。再强调一下,这里的MAP是估计的最优序列,和平滑得到的结果可能不一样,
平滑是对某个时点状态的最优估计,不是状态序列。
Posterior samples
有时候,比起隐含状态的估计序列,或许我们对基于后验分布生成得到的隐含序列样本更感兴趣,即 P ( z 1 : T ∣ x 1 : T ) P(z_{1:T} | \boldsymbol{x}_{1:T}) P(z1:T∣x1:T)。
HMM模型与高斯混合模型比较
高斯混合模型
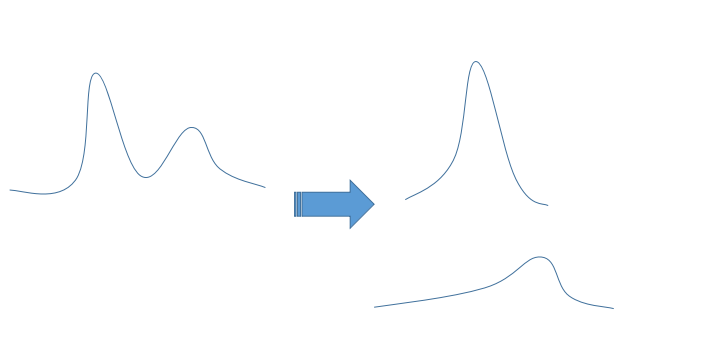
高斯混合模型理论本质很简单,就是有两个或者多个高斯模型混合在一起了,然后我们的任务就是估计每个高斯分布的参数以及它们组合起来的方式(也是概率)。如下示意图,左边是我们得到的一个经验分布,明显可以看到有两个峰。
如果我们假设是多个高斯组成的,那么我们可以把它拆分成多个条件概率分布,每个条件概率分布就是一个高斯,之后我们会用一些算法(比如MLE估计)来得到这些参数。
HMM
HMM和高斯混合模型有些类似,但又有不同的地方。它继承了高斯混合模型的特性,比如后验观测分布可以由多个不同的分布构成。但是最大的不同在于不同分布的出现是有记忆的,在高斯混合分布里,它判断某个观测值由哪个分布产生取决于
观测值在多个条件分布下的拟合效果。比如上图如果我们的观测值出现在第二个峰左右,那么它很有可能是由一个右偏分布生成的,也就是说推断它是哪个分布生成,只取决于当前观测值,和之前的历史没什么关系。而在HMM模型下,判断当前观测值
是由哪个分布生成不仅取决于当前观测值,还依赖于历史。
看我们如下示意图,左边是我们的无条件后验分布,但我们对后验经验分布的建模或者分解的方式不同,我们会考虑到序列的时序特征。看下图的右边,我们不仅把后验分布拆分成了两个不用的分布,它们之间出现的频率还有一定的规律,
红色状态后更容易出现红色状态,绿色状态也更容易跟这一个红色状态。这个假设就比高斯混合更近,高斯混合只会考虑这两个状态的出现频率,而不会考虑时序关联性。
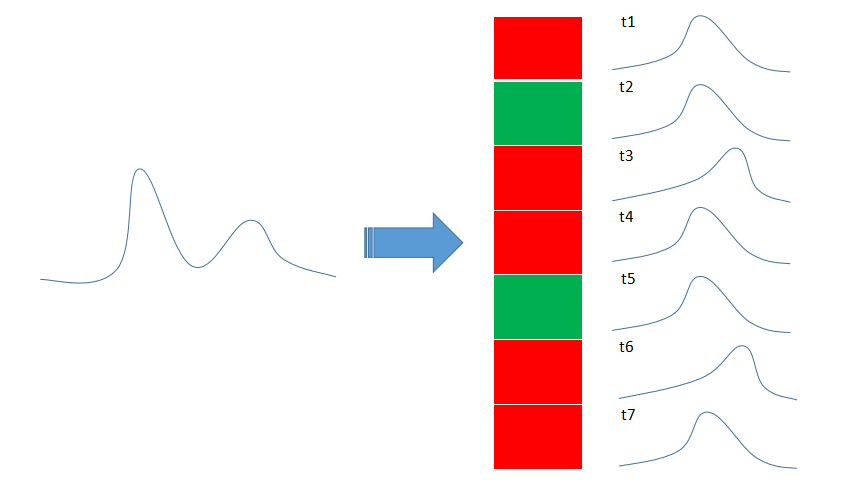
实际上HMM对时序状态的记忆很短,在决定当前是哪个状态是,它只会根据上一个状态做出决策。我们对HMM的“记忆”模型用马尔科夫链展示出来:
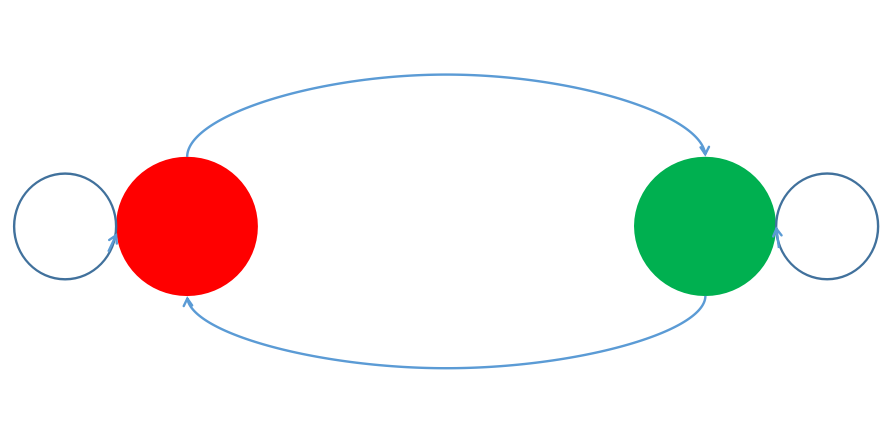
HMM在金融市场的研究浅析
下面我们用一个小案例来说明HMM,我们选取沪深300与恒生指数来作为我们的观测序列,为了平稳化,我们转换成收益率。我们先来看一下它们的后验联合分布是怎么样的:
import scipy
from scipy.stats import multivariate_normal
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
start_date = '2006-01-01'
end_date = '2017-12-31'
data = D.history_data(['000300.SHA','HSI.HKEX'],start_date=start_date,end_date=end_date,fields=['close'])
hs300 = data[data.instrument == '000300.SHA'].set_index('date').drop('instrument', axis=1)
hsi = data[data.instrument == 'HSI.HKEX'].set_index('date').drop('instrument', axis=1)
hs300_ret = hs300.apply(np.log).diff().dropna(0,how='all')
hs300_ret = hs300_ret.rename(columns={'close':'hs300'})
split_date = pd.Timestamp(year=2014,month=1,day=1)
hs300_ret_train = hs300_ret[hs300_ret.index < split_date]
hs300_ret_test = hs300_ret[hs300_ret.index >= split_date]
hsi_ret = hsi.apply(np.log).diff().dropna(0,how='all')
hsi_ret = hsi_ret.rename(columns={'close':'hsi'})
hsi_ret_train = hsi_ret[hsi_ret.index < split_date]
hsi_ret_test = hsi_ret[hsi_ret.index >= split_date]
ret_train = pd.concat([hs300_ret_train,hsi_ret_train],axis=1).dropna()
mu = ret_train.mean()
cov = ret_train.cov()
x = np.linspace(-0.05,0.05,100)
y = np.linspace(-0.05,0.05,100)
X,Y = np.meshgrid(x,y)
pos = np.empty(X.shape + (2,))
pos[:, :, 0] = X; pos[:, :, 1] = Y
rv = multivariate_normal(mu, cov)
#Make a 3D plot
fig = plt.figure(figsize=(15,8))
ax = fig.gca(projection='3d')
ax.plot_surface(X, Y, rv.pdf(pos),cmap='viridis',linewidth=0)
ax.set_xlabel('Mean of SH300 return')
ax.set_ylabel('Mean of HSI return')
ax.set_zlabel('Density')
ax.set_title('Joint distribution of SH300 & HSI')
plt.show()

有了一个直观的认识后,我们来用HMM对这个联合概率分布进行建模,观测分布我们用高斯正太。由于我们不知道应该选择多少个隐含状态,于是我们分别试下2、3、4个不同的隐含状态数量。
当HMM训练过后,我们分别可视化验证一下每个状态下的观测分布,以及参数分布:
random.seed(0)
np.random.seed(0)
from hmmlearn.hmm import GaussianHMM
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
model_2 = GaussianHMM(n_components=2, covariance_type="full", n_iter=2000).fit(ret_train)
model_3 = GaussianHMM(n_components=3, covariance_type="full", n_iter=2000).fit(ret_train)
model_4 = GaussianHMM(n_components=4, covariance_type="full", n_iter=2000).fit(ret_train)
def plot_hmm_state(model, train=ret_train):
n = len(model.means_)
ind = list(range(n))
plt.figure(figsize=(18,5))
plt.subplot(1,3,1)
#plt.plot(np.sqrt(model.covars_[:,0,0]),model.means_[:,0],'bo',visible=False)
plt.plot(model.means_[:,0],model.means_[:,1],'bo',visible=False)
plt.ylabel('$\mu_{1}$')
plt.xlabel('$\mu_{2}$')
plt.title('Characteristic of components')
for i in range(n):
plt.text(x=model.means_[i,0],y=model.means_[i,1], s=str(i))
plt.subplot(1,3,2)
plt.plot(np.sqrt(model.covars_[:,0,0]),np.sqrt(model.covars_[:,1,1]),'bo',visible=False)
plt.ylabel('$\sigma_{1}$')
plt.xlabel('$\sigma_{2}$')
plt.title('Characteristic of components')
for i in range(n):
plt.text(x=np.sqrt(model.covars_[i,0,0]),y=np.sqrt(model.covars_[i,1,1]), s=str(i))
plt.subplot(1,3,3)
ind, counts = np.unique(model.decode(train)[1],return_counts=True)
percents = counts/counts.sum()
plt.bar(left=ind,height=percents)
plt.xticks(ind, ['comp ' + str(i) for i in ind])
plt.ylabel('percents')
plt.xlabel('components')
plt.title('Distribution of components')
plt.show()
plot_hmm_state(model_2)

plot_hmm_state(model_3)

plot_hmm_state(model_4)

我们先来研究隐含状态数量为2时的参数分布,我们不难从均值的散点图中看到,HMM把隐含状态分为同涨和同跌两种状态,从方差看在同跌情况下要大的多。
再来看下隐含状态数量为3时的参数分布情况,HMM把市场分为同涨、同跌以及异步状态(即市场涨跌方向相反)。从均值方差看,异步状态是沪深指数最惨、波动率最大的时候。
最后我们看到隐含状态数量为4时,观测分布就不太均衡,状态1和状态2下面没多少观测值,状态1代表市场同步大跌,状态2是市场同步轻微下跌。状态0代表沪深轻微震荡、恒生轻微上涨,状态3则是同步上涨。
当然,隐含状态的划分不一定要有经验意义,可以理解为是聚类算法的一种。每个类也不一定要均衡。
接下来我们再来研究下它们的转移矩阵:
model_2.transmat_

model_3.transmat_

model_4.transmat_

我们不难总结出,不管是在2和3个隐含状态数量时,每个状态95%以上的概率会维持自身状态,这是否说明了市场动量的惯性特征?
在4个隐含状态时,状态0和4有更多可能会继续留在原状态,其中状态4还有19%的概率会变成状态三,大涨过后更容易调整?状态1有96%的概率继续留在原状态,并且有不到4%的概率会切换成0状态,看来市场下跌的惯性也很大。
然后状态2有78%的概率会变成71%,27%的概率留在原状态。
我不想过分去解释这些隐含状态,有些人为性,我们直接来看数据拟合效果,这里为了演示目的,我们只展示三个隐含状态数量的MAP状态序列估计:
state_seq = model_3.predict(ret_train)
seg_ps = [] # (start_index, end_index, state)
last_state = None
s_idx = None
e_idx = None
for i in range(len(state_seq)):
state = state_seq[i]
if last_state is None:
s_idx = 0
e_idx = i+1
last_state = state
continue
if last_state is not None and state != last_state:
seg_ps.append((s_idx,e_idx,last_state))
s_idx = i
last_state = state
e_idx = i+1
seg_ps.append((s_idx,e_idx,last_state))
plt.figure(figsize=(20,5))
colors = ['r','g','b','k']
plt.subplot(2,1,1)
plt.plot(hs300.close[ret_train.index])
plt.title('hs300 index')
for i in range(len(seg_ps)):
s_idx = seg_ps[i][0]
e_idx = seg_ps[i][1]
s = seg_ps[i][2]
style = ''
if s == 0:
style = 'r-'
elif s == 1:
style = 'g-'
else:
style = 'b-'
plt.plot(hs300.close[ret_train.index][s_idx:e_idx+1], style)
plt.subplot(2,1,2)
plt.plot(hsi.close[ret_train.index])
plt.title('hsi index')
for i in range(len(seg_ps)):
s_idx = seg_ps[i][0]
e_idx = seg_ps[i][1]
s = seg_ps[i][2]
style = ''
if s == 0:
style = 'r-'
elif s == 1:
style = 'g-'
else:
style = 'b-'
plt.plot(hsi.close[ret_train.index][s_idx:e_idx+1], style)
plt.show()

这里大家看到了沪深和恒指在MAP最优隐含状态序列,有什么规律大家自己去看。这里只想强调一点,HMM的隐含状态本质上可以理解为聚类,给我们提供了另外一种视角来看待问题,它本身不知道隐含状态的意义,只是拟合出来的结果,That’s it。
另外,大家在观测上图模式的时候,一定要记住,HMM是根据观测分布来划分不同的联合分布,本身也没有太多的“记忆”。大家还可以再加入其他的变量,及调整隐含状态数量。
作为一篇教程,为了完整性,我再给大家演示下如何预测未来状态以及预测未来观测:
current_state_prob = model_3.predict_proba(ret_train)[-1] # 得到当前状态估计
next_state_prob = current_state_prob.dot(model_3.transmat_) # 乘以转移矩阵得到下个状态预测向量
next_state_prob
对于预测下个观察序列,我们有如下公式:
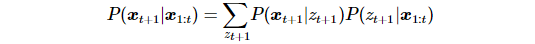
等式右边的第一项代表了我们三个状态下的正太分布,于是就等同于对三个正太分布(联合分布)的均值进行加权平均,权重就是预测状态概率向量:
mu = model_3.means_
next_predict_obs = np.sum([mu[s]*next_state_prob[s] for s in range(len(mu))],0)
next_predict_obs # 代表 (沪深300收益预测,恒生收益预测)
总结
- HMM是一个概率模型,对于观测量分布和状态分布均有概率解释
- HMM是一个时序模型,对状态序列做了自相关一阶的建模和假设,即马尔科夫假设
- HMM是一个非监督学习模型,可以看成是一个聚类模型,隐状态可以给我们看待问题的全新角度
- HMM是一个预测模型,对未来观测值的预测本质上就是隐状态所代表的概率分布的加权平均
- HMM是一个贝叶斯模型,可以对观测分布预设初始信念参数
- HMM需要预设隐状态数量,这个有一定的人为性
- HMM需要预测观测分布,比如高斯分布、高斯混合分布
- HMM对状态序列平滑的效果似乎要超过对状态预测的效果,最著名的就是Viterbi算法
预告:《ML系列》下期可能推出关于HMM的算法详解和实现
- 原文链接:《HMM 理论基础及金融市场的应用》
- 实现平台:BigQuant—人工智能量化投资平台
本文由BigQuant人工智能量化投资平台原创推出,版权归BigQuant所有,转载请注明出处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号