研究分享:用随机森林预测股价走势
机器学习已经广泛地应用在对于资产市场的分析中,在量化投资中尤为显著。但是,在浩如烟海的机器学习算法中,到底哪种算法能取得更优的预测效果呢?发表在《Applied Mathematical Finance》的这篇文章利用随机森林算法对股价d天之后的涨跌方向进行了预测。发现相比于SVM、线性判别分析等模型,随机森林可以取得更优秀的预测结果:能够达到85%-95%的准确率。
摘要
为了最小化预测误差,文章将预测股价的走势看做一个二分类问题(涨or跌),使用集成机器学习建模解决。文章里利用RSI(相对强弱指数)、KD随机指标、MACD等6个常用的技术指标作为分类的特征,对随机森林模型进行训练。最后发现,模型中决策树个数增加,模型准确率增加并有收敛趋势;并且,预测的时间窗口越长,模型越准确。
随机森林简介
在正式进入文章前,先对随机森林算法给出简单的介绍。
随机森林算法是一种非线性模型,顾名思义,是将多个决策树集成为森林的一种模型。理解随机森林的关键有两点:随机抽样和多数投票。
首先,对于每一个决策树,从全样本集中有放回地随机抽取训练集。本文决策树分类的标准是特征矩阵X里面的技术指标,一直利用技术指标分类直到基尼不纯度很小达到要求。
这些决策树独立预测,然后对每个决策树预测的结果进行投票,票数最多的成为随机森林的预测结果。这样避免了单个决策树的过拟合。
由于随机抽样,每个决策树使用的都不是全样本(大约只有 2 3 \frac{2}{3} 32的样本被抽到),没有被抽到的样本是这个决策树的非样本集(袋外样本 Out of Bag Sample)。对于所有决策树产生的袋外样本,对每个样本,计算它作为oob样本的树对它的分类情况(约 1 3 \frac{1}{3} 31的树),然后以简单多数投票作为该样本的分类结果,最后用误分个数占样本总数的比率作为随机森林的OOB误分率。所以,OOB偏差越小,说明误分类的比例越低,随机森林分类越准。
研究思路
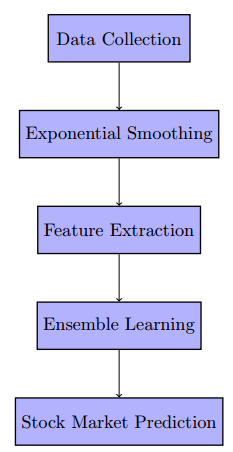
数据收集 - 指数平滑处理 - 特征提取 - 随机森林集成学习 - 股票市场预测
研究内容
1. 数据收集与预处理
作者收集了Apple,三星和GE的共7000个左右交易日股价走势数据,分别预测了30天、60天、90天后的股票走势。
为了去除历史数据中的噪音,展现历史数据的实际规律,作者采用了指数平滑法对股价数据进行预处理:
S
0
=
Y
0
f
o
r
t
>
0
,
S
t
=
α
∗
Y
t
+
(
1
−
α
)
∗
S
t
−
1
S_0 = Y_0\\\\ for\ t>0, \ S_t = \alpha * Y_t + (1-\alpha) * S_{t-1}
S0=Y0for t>0, St=α∗Yt+(1−α)∗St−1
α
\alpha
α在0到1之间并且比较接近1,这样给近期的数据设置了更大的权重。因为近期的走势在某种程度上更具有持续性,所以将较大的权重放在最近的数据。
2. 特征提取
标签设置
t
a
r
g
e
t
i
=
S
i
g
n
(
c
l
o
s
e
i
+
d
−
c
l
o
s
e
i
)
target_i = Sign(close_{i+d} - close_{i})
targeti=Sign(closei+d−closei)
d
d
d是预测的时间窗口,
S
i
g
n
Sign
Sign是符号函数。当
t
a
r
g
e
t
i
target_i
targeti的值为1,代表在
i
i
i这个时刻看,d天后的收盘价比今天的收盘价高,也就是说股票在d天后上涨;反之下跌。
t
a
r
g
e
t
target
target也是模型需要预测的目标。
分类特征
技术指标是在股票分析里用于判断熊牛的重要的信号,文章中运用六个技术指标作为分类的标准,让随机森林模型去学习这些特征。指标列举如下:
| RSI 相对强弱指数 | Stochastic Oscillator 随机指标 | Williams %R 威廉指标 |
| MACD | Price Rate of Change 价格波动率 | On Balance Volume 能量潮指标 |
3. 建模
线性可分性测试
在建立模型之前,作者首先对涨or跌这两类数据进行了线性可分测试,结果发现股票走势预测问题不是线性可分的(投影到二维空间发现凸包有大量重合),所以所有和线性判别分析有关的算法比如SVM都是不适用的。随机森林作为一种非线性算法,可以避免这种情况,在接下来的股票走势预测研究中有重要应用意义。
“线性可分测试结果”
随机森林建立
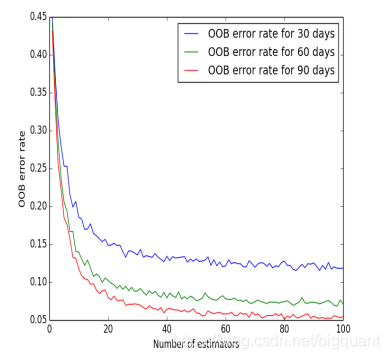
作者利用苹果公司的股价进行了随机森林建模,分别预测了30、60、90天后的股价走势。作者发现,随着模型中决策树个数的增加,模型准确率增加并有收敛趋势。并且,预测的时间窗口越长,模型越准确。
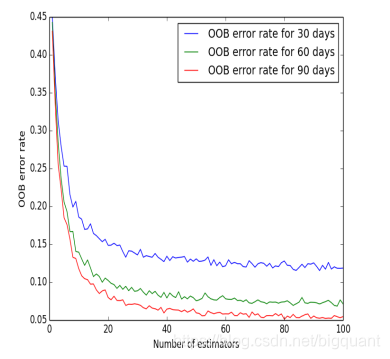
“OOB误差具体结果”
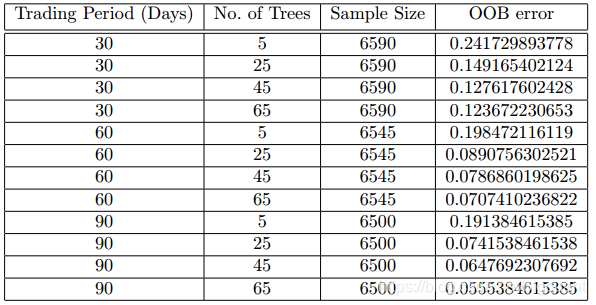
据上图,OOB误差逐渐减小并收敛,当决策树的数量大于45时到达稳态;预测的时间窗口越大,OOB误差越小,但是这种减少是边际递减的。
模型结果
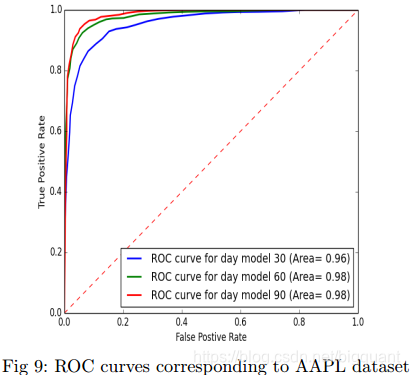
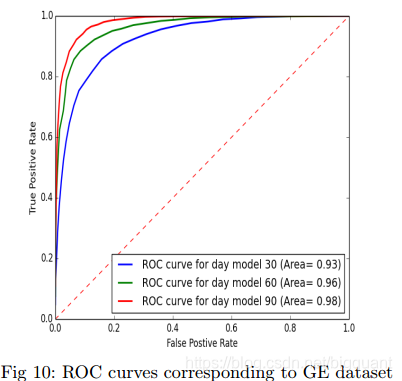
模型对于苹果、三星、通用电气的股票价格预测都能达到85%以上的准确率,随机森林模型表现优异。
“苹果股价预测准确率的ROC曲线”
“三星股价预测准确率的ROC曲线”
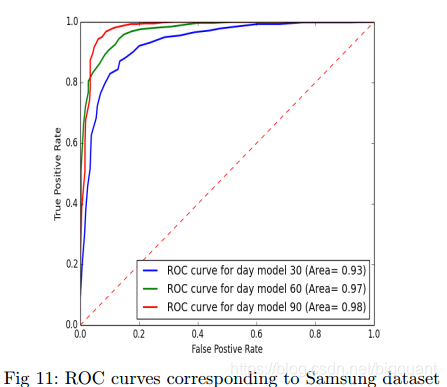
“通用电气股价预测准确率的ROC曲线”
4. 模型比较
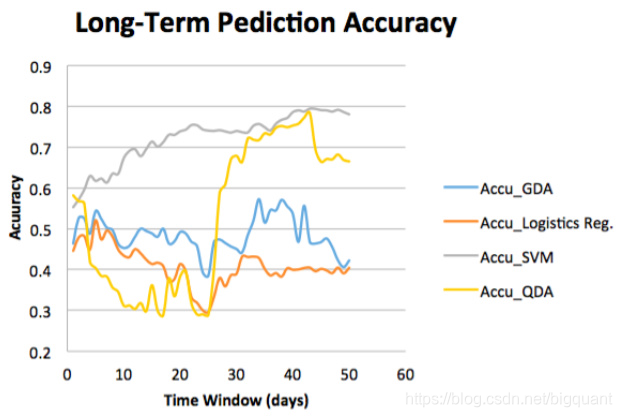
为了证明随机森林算法的优越性,作者与SVM、逻辑回归、高斯判别分析、二次判别分析等模型进行了比较。
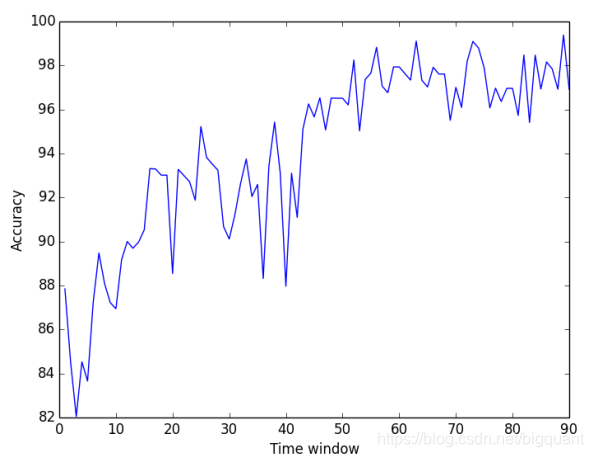
作者和Dai和Zhang在2013年发表的文章中使用的四种监督算法进行比较,使用2008年9月1日到2013年8月11日的3M股票历史数据,发现相比于SVM、逻辑回归、高斯判别分析、二次判别分析模型30%-80%的准确率,随机森林算法可达到80%-99%的准确率,并且当预测的时间窗口大于60天时准确率可以稳定在98%左右。
四种监督算法结果"
随机森林算法结果
研究结果与未来展望
本文填补了股票走势预测中集成学习研究的空白,利用随机森林分类器预测股票的长期走势并取得了令人惊艳的结果。对于文章中用到的苹果、三星、通用电气数据集,随机森林模型的预测结果都能达到85%-95%的准确率。并且随着随机森林中决策树数量的增加,模型的结果趋于稳定。
本文可以用于设计股票投资策略。如果使用小时或分钟交易数据训练模型,可以用来做更短周期的预测。
本文也给了我们一个启示,股价预测的分类问题是线性不可分的,因此简单使用SVM等线性分类器的结果不会很好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号