
【干货】开发AI量化策略所遇到的坑
AI只是工具,想要驾驭AI还得自身有点功底,不然反而会被工具所害,甚至从信仰AI变为抵制AI。本文简单介绍开发AI量化选股策略中所遇到的各种坑,希望大家有所收获,少走弯路。
本文主要从思想和实操两个层面分享下我在开发AI量化选股策略中所遇到的各种坑,也希望各位小伙伴能够进行补充。
策略思想逻辑层面
-
训练集和测试集不能有所重合
机器学习的基本思路就是在训练集上发现pattern,训练出模型,然后对样本外的预测集数据进行预测。这好比老师平时布置的作业就是训练集,学生们通过平时的作业学习到知识,然后期末老师通过期末试卷来检验学生的学习掌握情况,如果期末试卷和平时作业一模一样,那么学生测试效果就会很好,因为之前他们就见过答案,这样就做不到对学生平时学习能力、知识掌握能力的测试,因此测试集不能和训练集一样。对于AI量化策略同样如此,如果拿模型预测训练集,效果一定很好,毕竟训练模型的时候模型已经“见过”了实际值。 -
金融时序数据采取以时间点划分训练集和测试集,而不是随机划分
金融数据是标准的时间序列数据,时间序列数据最主要的特征就是具有自相关性,因此使用机器学习、深度学习对金融数据进行建模不能完全照搬传统的机器学习模式。传统机器学习模式对训练集和测试集的划分是采取随机划分,样本之间没有时间先后顺序,完全是独立的样本,因此可以把数据打乱,随机抽取80%的数据作为训练集,剩下的20%数据作为测试集。但是金融市场不同的时间段市场状况是不一样的,时间是划分训练集和测试集最好的直尺。可以参考:《40 Interview Questions asked at Startups in Machine Learning / Data Science》 -
训练集数据不能太少,不要选择几只股票作为股票池
刚刚提到训练数据好比老师给学生平时布置的作业,如果作业太少、题目类型单一,那么学生求解问题也不能得到很好的训练。机器学习算法比较复杂,参数也较之于线性回归模型更多,训练集数据不够可能会导致模型泛化能力太差,因为训练集可能并不能反映出整体数据的分布,因此在预测集上偏差很(Bias)大,这有点类似“欠拟合”。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-soKMU0OE-1606982755164)(/community/uploads/default/original/2X/3/3f57b99c3dab1b2c7c84ea12e23d0000b3cc0609.jpg)]]()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-soKMU0OE-1606982755164)(/community/uploads/default/original/2X/3/3f57b99c3dab1b2c7c84ea12e23d0000b3cc0609.jpg)]](https://img-blog.csdnimg.cn/20201203160705625.png)
不仅如此,如果样本太小,特征太多,很容易陷入“维度灾难”,直接后果就是“过拟合”,为了防止“过拟合”,那么所需的训练样本数量就会呈指数型增长。但是,如果只选较短时间或者小部分股票的话,过拟合难以避免,模型在训练集上训练的很好,拿来预测测试集效果也很差,因此最好是全市场选股。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I1YqgtEM-1606982755167)(/community/uploads/default/original/2X/b/b624cd99f106ba90cf2ca3a546f420116ffd2fd9.jpg)]](https://img-blog.csdnimg.cn/20201203160730750.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2JpZ3F1YW50,size_16,color_FFFFFF,t_70)
-
特征具有可比性
数据挖掘离不开对数据进行清洗和预处理,机器学习也是如此。此外,还应该选择更有可比性的特征。比如今日收盘价这个特征,绝不可直接拿来训练模型,因为不同的股票其价格本身可能就不在一个平台上,贵州茅台的价格和工商银行的价格相差甚远,用这个特征并不能很好地反映出收益率的变动。在目前这个阶段,端到端的机器学习还没到来,特征工程(特征提取、特征选择、特征构建)在机器学习中起着非常重要的作用。虽然收盘价没有什么可比性,但是收盘价除以开盘价,或者10日均线除以20日均线这类的特征就能剔除价格本身差异所带来的影响。另外再举一个例子,市盈率是一个非常有效的特征,但是无论怎么调参数,收益都上不去,达到了一个瓶颈位置。对股票市场稍微了解的朋友就知道,不同行业公司的市盈率是不具有对比性的,银行行业的市盈率和制造行业的市盈率不在同一个水平,因此如果使用市盈率除以所属行业平均市盈率这个调整后的市盈率,效果应该更好。因此想要构造出好的因子还应该对金融市场有一些背景知识。 -
标注函数和策略逻辑保持一致
目前开发的AI量化策略还是属于监督式学习范畴,要训练出一个学习算法需要特征数据和标注数据。特征数据就是股票的各个特征,比如5日均价、当日收益率等,标注数据就代表着你希望选出什么样表现的股票,比如你使用未来5日的收益率作为标注,那么就表示你希望模型能够找出未来5日大概率上涨的股票。因此,标注函数和策略逻辑应始终保持一致。不同的特征对应的标注函数是不一样的,比如市盈率特征,这样的特征短期内变动不大,因此对短期股票的预测效果应该并不显著,因此标注函数应关注更长期的数据,而资金流特征、价量特征变动迅速,应该对应较短期的标注数据。可以看出,特征决定了标注函数,标注函数决定了策略的持仓周期。这也对我们调参提供了一种参考方法。 -
因子并非越多越好
在开发策略中,我们可以先对单因子进行检验,然后收集数十个能够带来正收益有效的因子,那是否可以把这些因子简单组合起来形成一个多因子的AI选股策略呢?答案远没有这么简单。
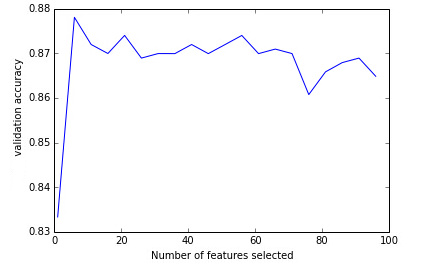
这里有一个图,横轴是所选择的因子数目,纵轴是测试集(也可称为验证集)获得的准确率,从中可以看到,并非选择了全部特征,准确率最高,当少数几个特征就可以得到最高准确率时候,选择的特征越多,反而画蛇添足了。
![image|441x272]()
比较暴力的方法就是遍历所有的特征集,然后确定出最优的特征集合。另外也可以通过模型各个特征的贡献度,留下贡献度高的特征,去除贡献度低的特征,在此过程中,多做实验时做好的途径。
平台使用实操方面
-
尽量选择AI可视化模块新建策略,选择最新的策略模板
之前BigQuant一直是代码模式开发策略,对编程要求较高,后来支持了上手更为简单的可视化模式,可视化模式最大的好处就是让策略更为直观,操作也更为灵活,拖动模块、连连线就能把策略运行起来。不仅如此,如果采取代码模式,模块版本很可能不是最新版本,产生一些很奇怪的问题,因此果断建议小伙伴采取可视化模式开发策略,这样每次都能选择最新的策略模板,规避不少奇奇怪怪的问题。 -
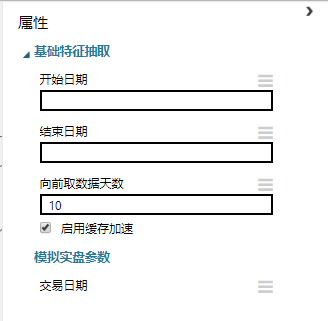
测试集跨越日期太短,却含有某些需要长周期参数的因子
这个坑比较隐蔽,而且是模拟交易时候才会遇到。比如测试集为2017-11-13到2017-11-17,一共5天数据,但是在因子列表里面却10日均价,10日收益率标准差等需要更多日期数据才能计算出来的因子,于是测试集抽取出来的因子都是NaN,经数据过滤模块一过滤(删除缺失值),测试集就没有数据了,于是会出现No data left after dropnan。这个问题需要这样解决:打开测试集的基础特征抽取模块,修改“向前取数据天数”参数。
![image|328x321]()
-
成交率限制设置为0
不知道大家有没有遇到这样的问题,在回测结果交易详情页面可以看到连续几天卖出同一只股票,但其实策略里面只有第一天才有卖出订单。这个坑也是特别隐蔽,其原因就是Trade(回测/模拟)模块成交率限制(volume_limit)这个参数导致的。这个参数默认清况下是0.025,具体含义是指,下单当日对股票的下单量和该日的成交量进行一个检查,如果下单量大于当日成交量的2.5%,则实际成交数量等于当日成交量的2.5%,超出的部分顺延到下一日进行成交;如果设置volume_limit为0,表明不需要进行检查,实际成交数量等于下单数量。因此,如果采取默认参数,并且初始金额很大的话,就会遇到连续几日持续交易的情况。最好的办法就是设置volume_limit为0,取消成交量检查。
以上为BigQuant用户的经验分享,更多AI量化探寻欢迎来 BigQuant人工智能量化平台

 浙公网安备 33010602011771号
浙公网安备 33010602011771号