
深度学习前沿 | 利用GAN预测股价走势
本文是对于medium上Boris博主的一篇文章的学习笔记,这篇文章中利用了生成对抗性网络(GAN)预测股票价格的变动,其中长短期记忆网络LSTM是生成器,卷积神经网络CNN是鉴别器,使用贝叶斯优化(以及高斯过程)和深度强化学习(DRL)优化模型中超参数。此外,文章中非常完整地实现了从特征抽取、模型建立、参数优化、实现预测的过程,其中运用了多种机器学习方法,比如BERT进行文本情绪分析、傅里叶变换提取总体趋势、autoencoder识别高级特征、XGboost实现特征重要性排序等。本文学习的思路是:GAN算法概览 – 项目思路 – 项目详解。拟在学习完成后,在Bigquant平台上尝试实现GAN算法预测股价走势。
1 GAN算法概览
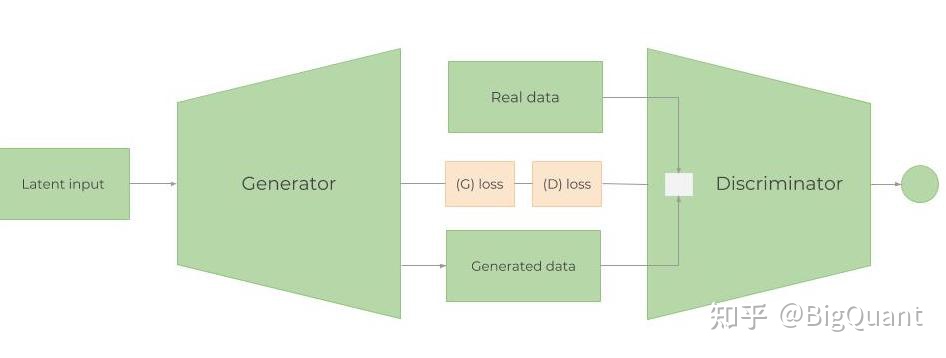
GAN(Generative Adversarial Networks)生成式对抗网络,顾名思义,是通过对抗的方式学习数据分布的生成式模型。所谓对抗,指的是生成网络和判别网络的互相对抗。生成网络尽可能生成逼真的样本,判别网络尽可能去分析该样本是真实的还是生成的。GAN的目的是通过这种对抗博弈得到效果良好的生成式网络,从而应用于图像生成、语音生成、视频生成等,如近期很火的“AI换头”就可能运用了GAN生成可接受的“另一副面孔”。GAN的具体示意如下:
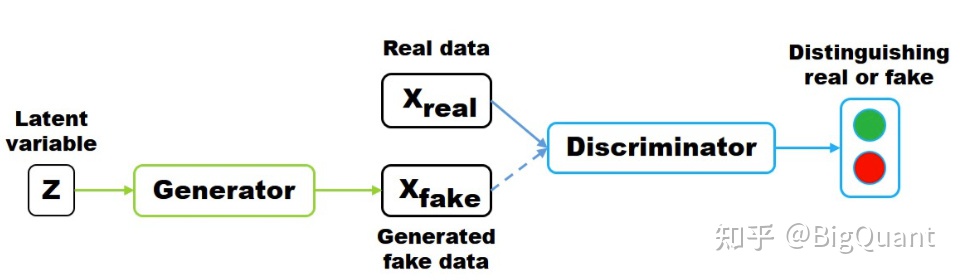
ZZ为隐变量,是随机噪声通常服从高斯分布。ZZ通过生成器generator生成XfakeXfake,判别器discriminator分辨输入的数据是生成样本XfakeXfake还是真实样本XrealXreal。模型训练的目标为尽可能使得XrealXreal和XfakeXfake的分布相似,如果以距离来衡量就是两个分布间距离最小,如可以交叉熵来表示:
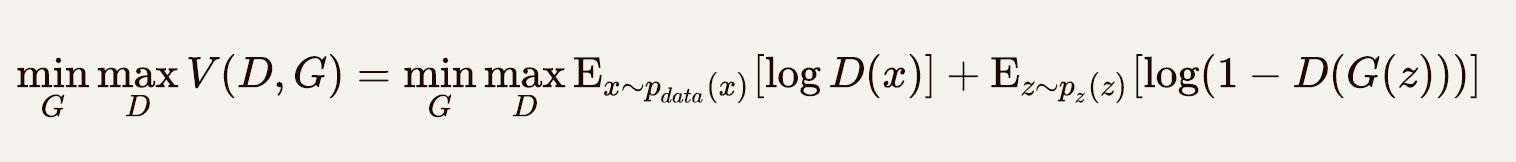
训练时,生成器和判别器采取交替训练,即先训练判别器再训练生成器,直到两者收敛到纳什均衡,即真实和生成样本预测概率均为1/2,难以区分。
从GAN算法的原理可以看出它主要应用于生成新的对象,如创建现实图像、绘画、音频和视频。那这样的生成式模型如何被应用于股价走势这种时间序列预测呢?
背后的逻辑在于一个假设:“历史可以重演”。市场不是100%随机的,股价未来的模式和行为应该或多或少是相同的(除非它开始以一种完全不同的方式运作,或者经济发生剧烈变化)。因此,文章作者希望为未来“生成”与已有的历史交易数据分布类似(当然不是完全相同)的数据,以此来预测股价走势。
这是一种对于市场有效性的自信,并且原文作者在2010年1月1日至2018年12月31日的(训练集7年,测试集2年)美股“Goldman Sachs(高盛)”股票上做了尝试,效果还是很好的。
2 股价预测思路
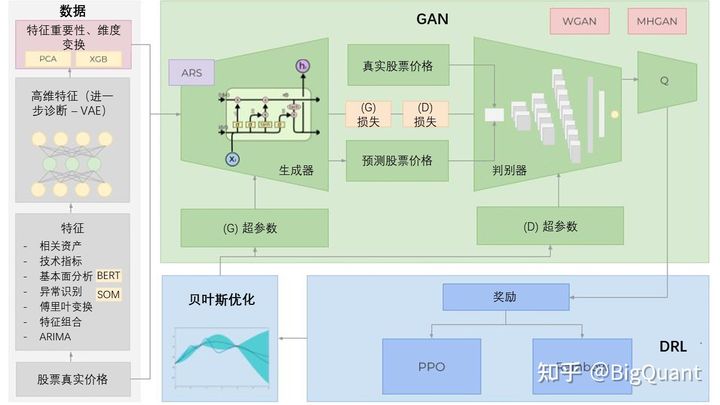
上图是Boris股价预测的整体思路。
特征工程:项目除高盛公司的历史股价之外,使用许多不同类型的输入数据,包括相关资产价格或利率、相关技术指标、基于财报和新闻的基本面分析、利用傅里叶变换提取的总体趋势方向、基于ARIMA的降噪后的预测价格,以便尽可能多地获取关于股票的信息、模式、相关性等。然后,利用变分自动编码器VAE生成一些高维特征,并利用XGBoost进行特征重要性分析和筛选,PCA降维构建特征组合。
模型建立:建立了LSTM作为时间序列生成器,CNN作为判别器的GAN模型,参考了Metropolis-Hastings GAN(MHGAN)和Wasserstein GAN(WGAN)的一些方法,使用判别器来选择生成的接近真实数据分布的样本,使用平滑的Wasserstein distance作为损失函数衡量方法,使得学习过程更为稳定、更易收敛。
超参数优化:用贝叶斯优化替代网格搜索确定模型超参数。此外,在GAN训练200期后,它将记录(LSTM的误差函数,GG)并将其作为奖励价值传递给强化学习,将决定是否改变超参数,使模型更适应不断变化的市场。
3 股价预测详解
本部分为了保持简洁,并没有附上原文的代码。所有的代码都可以在原文 193中找到。
3.1 特征工程
3.1.1 原始数据
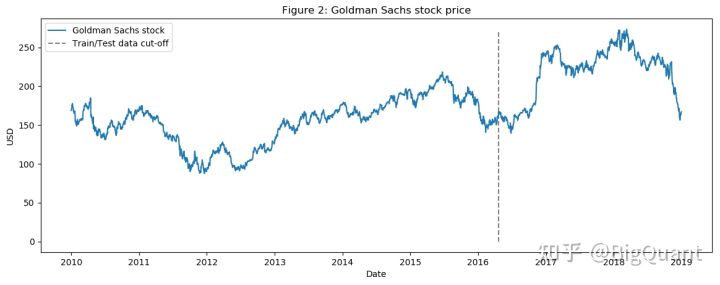
2010年1月1日至2018年12月31日的(训练集7年,测试集2年)高盛股票收盘价数据:
3.1.2 特征提取
(1)相关资产
-
类似于GS的公司,包括大小摩、花旗集团等;
-
全球经济指标,包括Libor利率、国债利率等;
-
每日波动率指数(VIX);
-
综合市场指数,例Nasdaq和NYSE、FTSE100指数、Nikkei225指数、恒生指数和BSE Sensex指数;
-
货币,全球贸易经常反映在货币的走势上,因此我们将使用一篮子货币(如美元兑日元、英镑兑美元等)作为特征。
(2)技术指标 7日/21日移动平均、21日/26日指数移动平均、MACD、20日标准差、ma7、ma21、26ema、12ema、MACD、20sd、上下布林带、动量、指数动量等
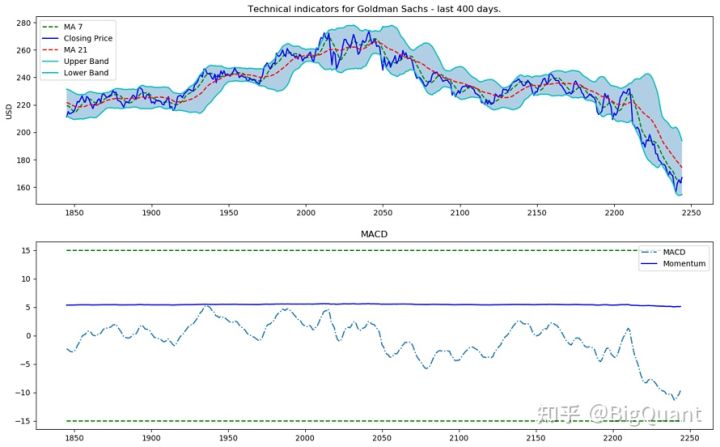
(3)基本面指标 对于基本面分析,我们将对所有关于GS的每日新闻进行情绪分析。最后使用sigmoid,结果将在0到1之间。得分越接近0,负面消息就越多(接近1表示正面情绪)。对于每一天,我们将创建平均每日分数(作为0到1之间的数字),并将其添加为一个特征。
(4)傅里叶变换
G(f)=∫∞−∞g(t)e−i2πftdtG(f)=∫−∞∞g(t)e−i2πftdt
使用傅里叶变换来提取GS股票的整体和局部趋势,并对其进行降
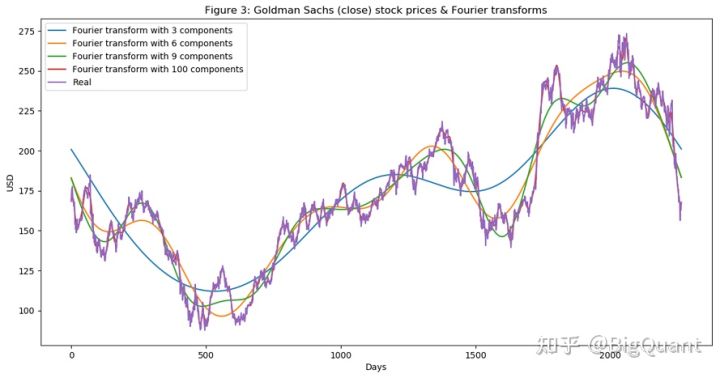
(4)ARIMA 将ARIMA的预测价格作为一个特征,也是起到了趋势抓取和降噪的功能。
进行了异方差、多重共线、序列相关性检查后,一共提取了112个特征。
3.1.3 特征生成和处理
此部分运用了XGBoost进行特征重要性分析、PCA降维处理和VAE高维特征生成,由于平台上已有关于XGBoost 10和PCA 4的介绍和封装模块,此处不做过多解释。主要展现文章中的VAE生成特征部分。
变分自编码器(Variational Auto-Encoders,VAE)作为深度生成模型的一种形式,是由 Kingma 等人于 2014 年提出的基于变分贝叶斯(Variational Bayes,VB)推断的生成式网络结构。与传统的自编码器通过数值的方式描述潜在空间不同,它以概率的方式描述对潜在空间的观察,在数据生成方面表现出了巨大的应用价值
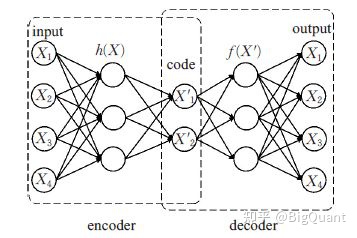
文章中使用了3层编码器和解码器的VAE模型,激活函数使用GELU -高斯误差线性单元。最后生成了112个特征,然后运用PCA对于这112个生成的特征以解释80%方差的标准进行降维,从而形成高维特征组合。最后,产生了84个特征组合。
3.2模型建立
3.2.1 生成器
为了对序列数据进行分析,生成器自然选用了长短期记忆网络LSTM(具体介绍可参见平台此处)。LSTM结构比较简单,特征数量个输入单元,500个隐藏单元,一个输出单元(股票价格),损失函数为L1正则化的mae,优化器为adam。
LSTM背后的逻辑是:取17天的数据(这些数据是GS股票每天的股价+当天的所有其他特性——相关资产、情绪等),并尝试预测第18天。然后将窗口后移,再次预测第18天,如此迭代整个数据集。
平台上对于LSTM的介绍在此处 42。
3.2.2 判别器
CNN通常用于图像相关的工作。在股价预测中,数据点形成小趋势,小趋势形成大趋势,趋势反过来形成模式,所以CNN检测特征的能力可用于提取有关GS股价走势模式的信息。此外,CNNs可以很好地处理空间数据——这意味着彼此距离较近的数据点之间的关系比分布在各处的数据点之间的关系更密切。这适用于时间序列,两天的时间越近,它们之间的关系就越密切。有一件事需要考虑,那就是季节性以及它可能如何改变CNN的工作。
平台上对于CNN的介绍在此处 25。
3.2.3 超参数
-
batch_size : the batch size of the LSTM and CNN
-
cnn_lr: the learning rate of the CNN
-
strides: the number of strides in the CNN
-
lrelu_alpha: the alpha for the LeakyReLU in the GAN
-
batchnorm_momentum: momentum for the batch normalization in the CNN
-
padding: the padding in the CNN
-
kernel_size’:1: kernel size in the CNN
-
dropout: dropout in the LSTM
-
filters: the initial number of filters
3.3参数优化
股票市场一直在变化。即使成功地训练了GAN和LSTM来创建非常准确的结果,结果也可能只在一定时期内有效。也就是说,我们需要不断优化整个过程:
1、添加或删除特征(例如添加可能相关的新股票或货币)
2、完善深度学习模式。改进模型最重要的方法之一是优化超参数
3.3.1 DRL
由于我们不能够了解股票市场运行的完整规则,所以需要采用无模型算法(model-free algorithms)。文章中采用Q-学习和策略优化的方法。
-
Q-learning:在Q-learning中,我们从给定的状态学习采取行动的价值。q值是采取行动后的预期收益。我们将使用Rainbow,它是7个Q-learning算法的组合。
-
策略优化:学习从给定状态采取的操作,准确设置奖励R:Reward=2∗lossG+lossD+accuracyG,Reward=2∗lossG+lossD+accuracyG, ,使用了PPO(Proximal Policy Optimization)方法。
关于强化学习的详细介绍可参考平台此处 27。
3.3.2 贝叶斯优化
不同于网格搜索的枚举式,贝叶斯优化是一种近似逼近的方法。如果说我们不知道某个函数具体是什么,那么可能就会使用一些已知的先验知识逼近或猜测该函数是什么。这就正是后验概率的核心思想。假设有一系列观察样本,并且数据是一条接一条地投入模型进行训练(在线学习)。这样训练后的模型将显著地服从某个函数,而该未知函数也将完全取决于它所学到的数据。因此,我们的任务就是找到一组能最大化学习效果的超参数。
3.4模型结果
在测试集上进行预测,epoch不同次数的模型效果分别如下:
(1)第一次epoch后
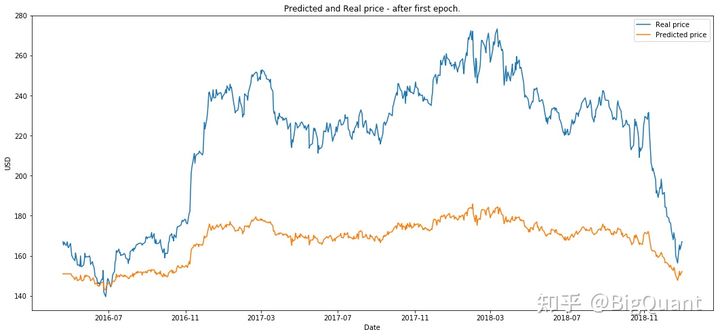
(2)第50次epoch后
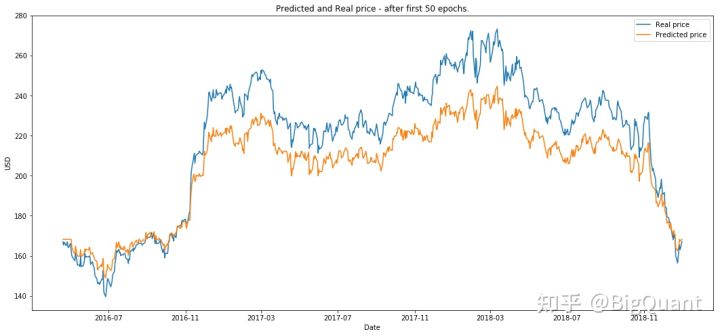
(3)第200次epoch后
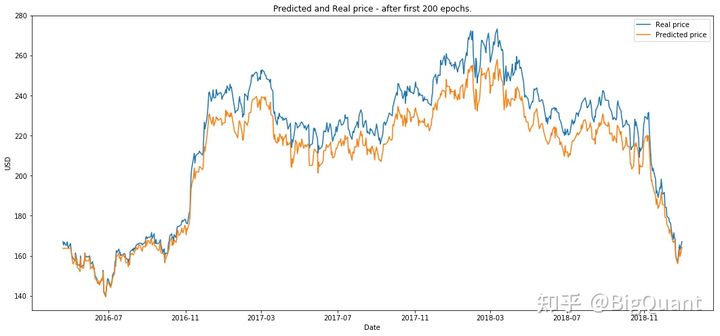
(4)DRL后 RL运行10episodes(我们将eposide定义为200个epochs上的一个完整GAN训练)
可见200次epoch迭代后模型效果已经不错,强化学习后达到了非常惊艳的效果。
后记: 原文作者是针对于美股市场上高盛这一支股票进行了股价预测,取得了不错的预测效果。经过学习,我准备在平台上实现这一过程的简化版本:如减少特征工程步骤、替换为A股个股、简化超参优化部分等,重点放在学习GAN算法的思路。 此外,如果GAN能达到良好的效果,预测结果可以作为量化策略的基础,设计相应策略。
欢迎来BigQuant平台验证实现!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号