寻找市场中的Alpha-WorldQuant功能的实现(下)
导语:本文介绍Alpha的相关基本概念,以及寻找和检验Alpha的主要流程和方法。在上篇中我们梳理了 WorldQuant经典读本FindingAlphas的概要以及WebSim的使用。作为下篇,我们演示如何通过BigQuant平台可以复现WebSim的因子分析功能,可以只输入因子表达式以及一些相关参数,便能够获取因子分析的相关结果。
模拟步骤流程
1、 输入测试的alpha表达式:在左上方m6输入特征列表模块中输入表达式。 2、 选择市场标的范围 :
-
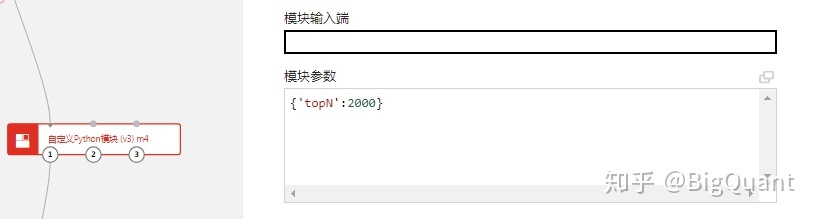
topN:代表选取流动性排名前N的股票作为证券池,在m4自定义模块中设置股票池范围,默认2000
3、 设置Delay: 延迟1(默认设置)表示alpha将使用昨天的数据(价格等)。延迟0意味着alpha将使用今天的数据。本例中默认会输出close_0/close_1和close_0/open_0两类Alpha,对应着延迟0和延迟1,因此无需设置。
4、 设置Decay: 代表因子平滑的参数,decay其实就是下面表达式中的n,默认是4 Decay_linear (x, n) = (x[date] * n x[date - 1] * (n - 1)… X[date - N - 1]) / (n (n - 1)… 1) 可以在m5模块中设置此参数:

5、 设置中性化:
-
neuralized_type:代表中性化的方式,分别有market和industry两种方式 可以在自定义模块m8中设置中性化方式

6 设置最大权重限制 :
-
max_stock_weight:代表组合中的单个股票最大权重,默认0.1 也是在自定义模块m8中设置,见上图。
7、 设置本金:
-
Booksize:代表本金,默认本金1千万,2倍杠杠的话就是2千万,在m16模块中设置

8、设置回测起止时间 回测起止时间通过证券代码列表m1模块设置。

评价指标介绍
-
Long/Short Count: 多空头寸数量
-
PnL: 当期头寸损益(金额)
-
Sharpe: 夏普比
-
Fitness: 定义为Sharpe * abs(Returns) / Turnover
-
Returns: 年化收益率
-
Drawdown: 最大回撤
-
Turnover: 换手率
-
Margin: 定义为PnL / 总交易额
-
Alpha0: 权重是当天因子值,收益率定义:close_0/open_0-1
-
Alpha1: 权重是前一天因子值,收益率定义:close_0/close_1-1
-
Alpha2:权重是前一天因子值,收益率定义:close_0/open_0-1
案例展示:
我们以市值因子作为示例,因子表达式为:-1*market_cap_0。我们在模块m6中输入因子表达式,选择默认参数,点击运行全部。可是以下链接克隆源码:
def m7_run_bigquant_run(input_1, input_2, input_3):
ins = input_1.read_pickle()['instruments']
start_date = input_1.read_pickle()['start_date']
end_date = input_1.read_pickle()['end_date']
industry_df = D.history_data(ins,start_date=start_date,end_date=end_date,fields='industry_sw_level1')
processed_industry_df = industry_df.pivot(index='date',columns='instrument',values='industry_sw_level1')\
.dropna(how='all')\
.stack()\
.apply(lambda x: 'SW'+str(int(x))+'.SHA')\
.reset_index()\
.rename(columns={0:'industry_code'})
## 过滤为0的数据异常,不过不应该被简单过滤
processed_industry_df = processed_industry_df[processed_industry_df['industry_code'].apply(lambda x:len(x)==12)]
data_1 = DataSource.write_df(processed_industry_df)
return Outputs(data_1=data_1, data_2=None, data_3=None)
# 后处理函数,可选。输入是主函数的输出,可以在这里对数据做处理,或者返回更友好的outputs数据格式。此函数输出不会被缓存。
def m7_post_run_bigquant_run(outputs):
return outputs
# Python 代码入口函数,input_1/2/3 对应三个输入端,data_1/2/3 对应三个输出端
def m4_run_bigquant_run(input_1, input_2, input_3, topN):
# 示例代码如下。在这里编写您的代码
amount_df = input_1.read_df()
universe_dic = amount_df.groupby('date').apply(lambda df: df.sort_values('amount_0', ascending=False)[:topN].instrument.tolist()).to_dict()
return Outputs(data_1=DataSource().write_pickle(universe_dic))
# 后处理函数,可选。输入是主函数的输出,可以在这里对数据做处理,或者返回更友好的outputs数据格式。此函数输出不会被缓存。
def m4_post_run_bigquant_run(outputs):
return outputs
# Python 代码入口函数,input_1/2/3 对应三个输入端,data_1/2/3 对应三个输出端
def m5_run_bigquant_run(input_1, input_2, input_3, decay):
# 示例代码如下。在这里编写您的代码
df = input_1.read_df()
factor = list(set(input_2.read_pickle()).difference(['end_date', 'instruments', 'start_date']))[0]
pvt = df.pivot(index='date', columns='instrument', values=factor)
pvt = pvt.rolling(decay).apply(lambda x: sum([(i+1)*xx for i,xx in enumerate(x)])/sum(range(decay+1)))
result = pvt.unstack().reset_index().rename(columns={0:factor})
ds = DataSource().write_df(result)
return Outputs(data_1=ds, data_2=None, data_3=None)
# 后处理函数,可选。输入是主函数的输出,可以在这里对数据做处理,或者返回更友好的outputs数据格式。此函数输出不会被缓存。
def m5_post_run_bigquant_run(outputs):
return outputs
# Python 代码入口函数,input_1/2/3 对应三个输入端,data_1/2/3 对应三个输出端
def m8_run_bigquant_run(input_1, input_2, input_3, max_stock_weight, neuralized_type):
# 示例代码如下。在这里编写您的代码
df = input_1.read_df()
factor = list(set(input_3.read_pickle()).difference(['end_date', 'instruments', 'start_date']))[0]
pvt = df.pivot(index='date', columns='instrument', values=factor)
universe_dic = input_2.read_pickle()
all_dates = sorted(list(universe_dic.keys()))
weights = {}
for date in all_dates:
alpha = pvt.loc[date, universe_dic[date]]
if neuralized_type == 'market':
# 市场中性化
alpha = alpha - alpha.mean()
elif neuralized_type == 'industry':
# 行业中性化
group_mean = df[df.date == date].groupby('industry_code', as_index=False).mean().rename(columns={factor:'group_mean'})
tmp = df[df.date == date].merge(group_mean, how='left', on='industry_code')
tmp[factor] = tmp[factor]- tmp['group_mean']
alpha = tmp.set_index('instrument')[factor].loc[universe_dic[date]]
alpha_weight = alpha / alpha.abs().sum()
alpha_weight = alpha_weight.clip(-max_stock_weight, max_stock_weight) # 权重截断处理
alpha_weight = alpha_weight / alpha_weight.abs().sum()
weights[date] = alpha_weight
ds = DataSource().write_pickle(weights)
return Outputs(data_1=ds, data_2=None, data_3=None)
# 后处理函数,可选。输入是主函数的输出,可以在这里对数据做处理,或者返回更友好的outputs数据格式。此函数输出不会被缓存。
def m8_post_run_bigquant_run(outputs):
return outputs
# Python 代码入口函数,input_1/2/3 对应三个输入端,data_1/2/3 对应三个输出端
def m15_run_bigquant_run(input_1, input_2, input_3):
# 示例代码如下。在这里编写您的代码
alpha_weights = input_1.read_pickle()
ret_df = input_2.read_df()
ret0_df = ret_df.pivot(index='date', columns='instrument', values='close_0/close_1-1')
ret1_df = ret_df.pivot(index='date', columns='instrument', values='close_0/open_0-1')
alpha0, alpha1, alpha2 = {}, {}, {}
all_dates = sorted(alpha_weights.keys())
last_date = None
w_prev = None
for date in all_dates:
#Alpha0: 权重是当天因子值,收益:Close/Open -1
#Alpha1: 权重是前一天因子值,收益:Close/shift(Close, 1) -1
#Alpha2:权重是前一天因子值,收益:Close/Open -1
#根据统计,市场平均情况下次日低开概率较大,这个导致了alpha1的收益会更低
w = alpha_weights[date]
alpha0[date] = (ret1_df.loc[date, w.index]*w).sum()
alpha1[date] = (ret0_df.loc[date, w_prev.index]*w_prev).sum() if w_prev is not None else 0.0
alpha2[date] = (ret1_df.loc[date, w_prev.index]*w_prev).sum() if w_prev is not None else 0.0
w_prev = w
alpha0 = pd.Series(alpha0)
alpha1 = pd.Series(alpha1)
alpha2 = pd.Series(alpha2)
alpha = pd.DataFrame({'alpha0':alpha0,
'alpha1':alpha1,
'alpha2':alpha2})
ds = DataSource().write_df(alpha)
return Outputs(data_1=ds, data_2=None, data_3=None)
# 后处理函数,可选。输入是主函数的输出,可以在这里对数据做处理,或者返回更友好的outputs数据格式。此函数输出不会被缓存。
def m15_post_run_bigquant_run(outputs):
return outputs
# Python 代码入口函数,input_1/2/3 对应三个输入端,data_1/2/3 对应三个输出端
def m16_run_bigquant_run(input_1, input_2, input_3, booksize):
# 示例代码如下。在这里编写您的代码
def calc_daily_turnover(alpha_weights):
all_dates = sorted(alpha_weights.keys())
last_date = None
turnover = {}
for date in all_dates:
w = alpha_weights[date]
w.name = 'w'
w_prev = alpha_weights[last_date] if last_date is not None else pd.Series(0,index=w.index)
w_prev.name = 'w_prev'
tmp = pd.concat([w,w_prev], axis=1).fillna(0)
turnover[date] = (tmp['w']-tmp['w_prev']).abs().sum()
last_date = date
turnover = pd.Series(turnover)
turnover /= 2
return turnover
import empyrical
alpha_df = m15.data_1.read_df()
alpha_weights = m8.data_1.read_pickle()
dailyPnL = alpha_df*booksize
PnL = dailyPnL.groupby(dailyPnL.index.year).sum()
IR = dailyPnL.groupby(dailyPnL.index.year).mean()/dailyPnL.groupby(dailyPnL.index.year).std()
sharpe = IR * np.sqrt(252)
returns = dailyPnL.groupby(dailyPnL.index.year).sum()/booksize
daily_turnover = calc_daily_turnover(alpha_weights)
turnover = daily_turnover.groupby(daily_turnover.index.year).mean()
fitness = sharpe * np.sqrt(returns.abs().apply(lambda x: x/turnover))
margin = PnL.apply(lambda x: x/(daily_turnover.groupby(daily_turnover.index.year).sum()*booksize)*10000)
long_short_count = pd.DataFrame({date:((w>0).sum(), (w<0).sum()) for date, w in alpha_weights.items()}).T
long_short_count = long_short_count.rename(columns={0: 'long', 1: 'short'})
long_short_count = long_short_count.groupby(long_short_count.index.year).sum()
max_drawdown = dailyPnL.apply(lambda x: empyrical.max_drawdown(x/booksize))
dataset_ds = DataSource()
output_store = dataset_ds.open_df_store()
dailyPnL.to_hdf(output_store, key='dailyPnL')
PnL.to_hdf(output_store, key='PnL')
turnover.to_hdf(output_store, key='turnover')
fitness.to_hdf(output_store, key='fitness')
margin.to_hdf(output_store, key='margin')
max_drawdown.to_hdf(output_store, key='max_drawdown')
long_short_count.to_hdf(output_store, key='long_short_count')
sharpe.to_hdf(output_store, key='sharpe')
returns.to_hdf(output_store, key='returns')
dataset_ds.close_df_store()
return Outputs(data_1=dataset_ds)
# 后处理函数,可选。输入是主函数的输出,可以在这里对数据做处理,或者返回更友好的outputs数据格式。此函数输出不会被缓存。
def m16_post_run_bigquant_run(outputs):
return outputs
m1 = M.instruments.v2(
start_date='2010-01-01',
end_date='2018-09-30',
market='CN_STOCK_A',
instrument_list='',
max_count=0
)
m7 = M.cached.v3(
input_1=m1.data,
run=m7_run_bigquant_run,
post_run=m7_post_run_bigquant_run,
input_ports='',
params='{}',
output_ports=''
)
m2 = M.input_features.v1(
features='mean(amount_0,66)'
)
m3 = M.general_feature_extractor.v7(
instruments=m1.data,
features=m2.data,
start_date='',
end_date='',
before_start_days=0
)
m4 = M.cached.v3(
input_1=m3.data,
run=m4_run_bigquant_run,
post_run=m4_post_run_bigquant_run,
input_ports='',
params='{\'topN\':2000}',
output_ports='',
m_cached=False
)
m6 = M.input_features.v1(
features='-1*market_cap_0',
m_cached=False
)
m10 = M.general_feature_extractor.v7(
instruments=m1.data,
features=m6.data,
start_date='',
end_date=''
)
m11 = M.derived_feature_extractor.v3(
input_data=m10.data,
features=m6.data,
date_col='date',
instrument_col='instrument',
user_functions={}
)
m5 = M.cached.v3(
input_1=m11.data,
input_2=m6.data,
run=m5_run_bigquant_run,
post_run=m5_post_run_bigquant_run,
input_ports='',
params='{\'decay\': 4}',
output_ports='',
m_cached=False
)
m9 = M.join.v3(
data1=m7.data_1,
data2=m5.data_1,
on='date,instrument',
how='inner',
sort=False
)
m8 = M.cached.v3(
input_1=m9.data,
input_2=m4.data_1,
input_3=m6.data,
run=m8_run_bigquant_run,
post_run=m8_post_run_bigquant_run,
input_ports='',
params="""{'max_stock_weight': 0.1,
'neuralized_type': 'industry'}""",
output_ports='',
m_cached=False
)
m12 = M.input_features.v1(
features="""close_0/open_0-1
close_0/close_1-1
"""
)
m13 = M.general_feature_extractor.v7(
instruments=m1.data,
features=m12.data,
start_date='',
end_date='',
before_start_days=0
)
m14 = M.derived_feature_extractor.v3(
input_data=m13.data,
features=m12.data,
date_col='date',
instrument_col='instrument',
user_functions={}
)
m15 = M.cached.v3(
input_1=m8.data_1,
input_2=m14.data,
run=m15_run_bigquant_run,
post_run=m15_post_run_bigquant_run,
input_ports='',
params='{}',
output_ports='',
m_cached=False
)
m16 = M.cached.v3(
input_1=m15.data_1,
run=m16_run_bigquant_run,
post_run=m16_post_run_bigquant_run,
input_ports='',
params='{\'booksize\': 20000000}',
output_ports='',
m_cached=False
)
 浙公网安备 33010602011771号
浙公网安备 33010602011771号