redis 使用详解
前戏:
又到了最喜欢的前戏部分,这个前戏可能有点长:
-
Nosql和sql的区别
- 存储结构与mysql这一种关系型数据库完全不同,nosql存储的是KV形式
- 应用场景不同,sql支持关系复杂的数据查询,nosql反之
- sql支持事务性,nosql不支持
-
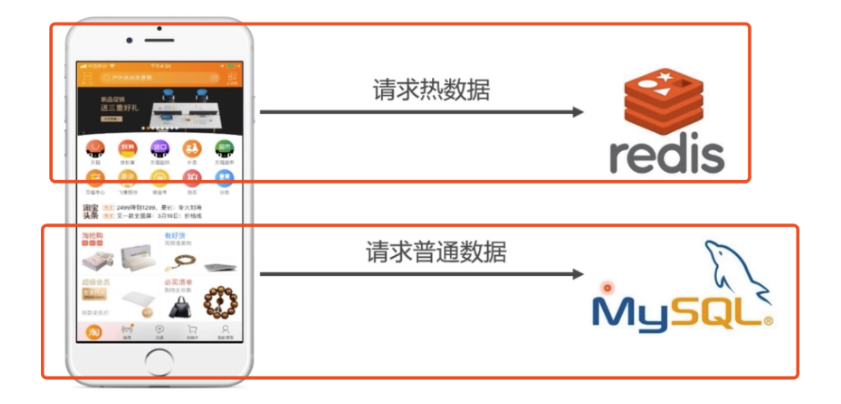
redis的优势,应用场景
- 性能高,读取速度10万次每秒,写入速度8万次每秒
- 所有操作支持原子性
- 用作缓存数据库,数据放在内存中
- 替代某些场景下的mysql,如社交类app
- 大型系统中,可以存储session信息,购物车订单
-
redis 特点
- NoSQL,内存型数据库,读写速度极快
- 存储在内存中,支持持久化存储
- key-value数据库
1.安装redis
-
yum安装,最简单,配置yum源
#前提得配置好阿里云yum源,epel源 #查看是否有redis包 yum list redis #安装redis yum install redis -y #安装好,启动redis systemctl start redis -
源码编译安装,指定安装路径,定制第三方模块功能
- 编译安装的优势是:
- 编译安装时可以指定扩展的module(模块),php、apache、nginx都是一样有很多第三方扩展模块,如mysql,编译安装时候,如果需要就定制存储引擎(innodb,还是MyIASM)
- 编译安装可以统一安装路径,linux软件约定安装目录在/opt/下面
- 软件仓库版本一般比较低,编译源码安装可以根据需求,安装最新的版本
- 又称求虐安装,作为开发不喜欢这种安装方式...
1.下载redis源码 wget http://download.redis.io/releases/redis-4.0.10.tar.gz 2.解压缩 tar -zxf redis-4.0.10.tar.gz 3.切换redis源码目录 cd redis-4.0.10.tar.gz 4.编译源文件 make 5.编译好后,src/目录下有编译好的redis指令 6.make install 安装到指定目录,默认在/usr/local/bin - 编译安装的优势是:
-
检测是否启动成功
redis-cli #redis 客户端工具 #进入交互式环境后,执行ping,返回pong表示安装成功 127.0.0.1:6379> ping PONG
2.redis配置
- ps -ef|grep redis 查看进程
- netstat -tunlp|grep redis 查看端口
-
指定配置文件,安全的启动redis服务端
- 更改启动端口
- 添加redis密码
- 开启redis安全模式
#redis的默认配置文件是 redis.conf #过滤出配置文件的有益信息(去除空白行和注释行) grep -v "^#" redis.conf |grep -v "^$" -
指定配置文件启动
- redis-server /opt/redis-4.0.10/redis.conf & #指定配置文件启动redis,且后台启动
bind 192.168.182.130 #绑定服务端地址 protected-mode yes #安全模式 port 6800 #端口 requirepass haohaio #密码 daemonize yes #后台运行 pidfile /var/run/redis_6379.pid #进程id文件 loglevel notice #日志等级 logfile "" -
使用密码登录redis,使用6800端口
-
方法1:建议使用
[root@oldboy_python ~ 09:48:41]#redis-cli -p 6380 127.0.0.1:6380> auth xxxx OK -
方法2:不建议使用,密码易暴漏
[root@oldboy_python ~ 09:49:46]#redis-cli -p 6380 -a xxxx Warning: Using a password with '-a' option on the command line interface may not be safe. 127.0.0.1:6380> ping PONG
-
1.redis的数据类型
-
redis是一种高级的key:value存储系统,其中value支持五种数据类型
- 字符串(strings)
- 散列(hashes)
- 列表(lists)
- 集合(sets)
- 有序集合(sorted sets)
-
redis 的基本命令
keys * 查看所有key type key 查看key类型 expire key seconds 过期时间 ttl key 查看key过期剩余时间 -2表示key已经不存在了 persist 取消key的过期时间 -1表示key存在,没有过期时间 exists key 判断key存在 存在返回1 否则0 del keys 删除key 可以删除多个 dbsize 计算key的数量
-
strings类型
- set 设置key
- get 获取key
- append 追加string
- mset 设置多个键值对
- mget 获取多个键值对
- del 删除key
- incr 递增+1
- decr 递减-1
-
list类型
- lpush 从列表左边插
- rpush 从列表右边插
- lrange 获取一定长度的元素 lrange key start stop
- ltrim 截取一定长度列表
- lpop 删除最左边一个元素
- rpop 删除最右边一个元素
- lpushx/rpushx key存在则添加值,不存在不处理
-
sets集合类型(无序)
- sadd/srem 添加/删除 元素
- sismember 判断是否为set的一个元素
- smembers 返回集合所有的成员
- sdiff 返回一个集合和其他集合的差异
- sinter 返回几个集合的交集
- sunion 返回几个集合的并集
-
有序集合
-
利用有序集合的排序,排序学生的成绩
127.0.0.1:6379> ZADD mid_test 70 "alex" (integer) 1 127.0.0.1:6379> ZADD mid_test 80 "wusir" (integer) 1 127.0.0.1:6379> ZADD mid_test 99 "yuyu" -
zreverange 倒叙
-
zrange正序
-
ZREM 移除
-
返回有序集合mid_test的基数
127.0.0.1:6379> ZCARD mid_test (integer) 3 -
返回成员的score值
127.0.0.1:6379> ZSCORE mid_test alex "70"
-
-
哈希数据结构
- hashes存的是字符串和字符串值之间的映射,比如一个用户要存储其全名、姓氏、年龄等等,就很适合使用哈希。
- hset 设置散列值
- hget 获取散列值
- hmset 设置多对散列值
- hmget 获取多对散列值
- hsetnx 如果散列已经存在,则不设置(防止覆盖key)
- hkeys 返回所有keys
- hvals 返回所有values
- hlen 返回散列包含域(field)的数量
- hdel 删除散列指定的域(field)
- hexists 判断是否存在
- hashes存的是字符串和字符串值之间的映射,比如一个用户要存储其全名、姓氏、年龄等等,就很适合使用哈希。
2.redis的发布订阅
- redis的发布订阅请参考博文地址: https://www.cnblogs.com/pyyu/p/10013703.html
3.redis 的持久化存储
- Redis是一种内存型数据库,一旦服务器进程退出,数据库的数据就会丢失,为了解决这个问题,Redis提供了两种持久化的方案,将内存中的数据保存到磁盘中,避免数据的丢失。
3.1 RDB持久化
-
redis提供了RDB持久化的功能,这个功能可以将redis在内存中的的状态保存到硬盘中,它可以手动执行。 -
也可以再
redis.conf中配置,定期执行。 -
RDB持久化产生的RDB文件是一个经过压缩的二进制文件,这个文件被保存在硬盘中,redis可以通过这个文件还原数据库当时的状态。-
-
实战
-
触发机制,
- 手动执行save命令
- 或者配置触发条件 save 200 10 #在200秒中内,超过10个修改类的操作
-
建立redis配置文件,开启rdb功能
#配置文件 s21_rdb.conf 内容如下 ,有关rdb的配置参数是 dbfilename dbmp.rdb ,一个是 save 900 1 daemonize yes port 6379 logfile /data/6379/redis.log dir /data/6379 #定义持久化文件存储位置 dbfilename s21redis.rdb #rdb持久化文件 bind 127.0.0.1 #redis绑定地址 requirepass redhat save 900 1 save 300 10 save 60 10000 save 20 2 #在20秒内,超过2个修改类的操作
-
3.2 AOF机制
-
第二个机制 aof机制 ,将你的修改类的操作命令,追加到日志文件中
-
AOF 文件中的命令全部以redis协议的格式保存,新命令追加到文件末尾。
-
优缺点
- 优点:最大程序保证数据不丢
- 缺点:日志记录非常大
redis-client 写入数据 > redis-server 同步命令 > AOF文件 -
配置参数
appendonly yes appendfsync always 总是修改类的操作 everysec 每秒做一次持久化 no 依赖于系统自带的缓存大小机制
1.准备aof配置文件 redis.conf
daemonize yes
port 6379
logfile /data/6379/redis.log
dir /data/6379
dbfilename dbmp.rdb
requirepass redhat
save 900 1
save 300 10
save 60 10000
appendonly yes
appendfsync everysec
2.启动redis服务
redis-server /etc/redis.conf
3.检查redis数据目录/data/6379/是否产生了aof文件
[root@web02 6379]# ls
appendonly.aof dbmp.rdb redis.log
4.登录redis-cli,写入数据,实时检查aof文件信息
[root@web02 6379]# tail -f appendonly.aof
5.设置新key,检查aof信息,然后关闭redis,检查数据是否持久化
redis-cli -a redhat shutdown
redis-server /etc/redis.conf
redis-cli -a redhat
3.3小结
- redis 持久化方式有哪些?有什么区别?
- rdb:基于快照的持久化,速度更快,一般用作备份,主从复制也是依赖于rdb持久化功能
- aof:以追加的方式记录redis操作日志的文件。可以最大程度的保证redis数据安全,类似于mysql的binlog
4.redis主从复制
话不多说,直接看案例:
-
环境准备,
主从规划 主节点:6380 从节点:6381、6382
-
运行3个redis数据库,达到 1主 2从的配置
#主库 6379.conf port 6379 daemonize yes pidfile /data/6379/redis.pid loglevel notice logfile "/data/6379/redis.log" dbfilename dump.rdb dir /data/6379 #从库 6380 port 6380 daemonize yes pidfile /data/6380/redis.pid loglevel notice logfile "/data/6380/redis.log" dbfilename dump.rdb dir /data/6380 slaveof 127.0.0.1 6379 #从库 6381 port 6381 daemonize yes pidfile /data/6381/redis.pid loglevel notice logfile "/data/6381/redis.log" dbfilename dump.rdb dir /data/6381 slaveof 127.0.0.1 6379
-
开启主从复制功能
edis-cli info #查看数据库信息
redis-cli info replication
-
在6380 和6381数据库上 ,配置主从信息,通过参数形式修改配置,临时生效,注意要写入配置文件
redis-cli -p 6380 slaveof 127.0.0.1 6379 redis-cli -p 6381 slaveof 127.0.0.1 6379
-
模拟主从复制故障,手动切换master-slave身份
1.杀死6379进程 ,干掉主库 2.手动切换 6381为新的主库,需要先关闭它的从库身份 redis-cli -p 6381 slaveof no one 3.修改6380的新主库是 6381 redis-cli -p 6380 slaveof 127.0.0.1 6381
5.哨兵高可用
- redis-sentinel功能
-
环境准备
- 三个redis数据库实例 ,配置好 1主 2从的配置
#1 6379.conf port 6379 daemonize yes logfile "6379.log" dbfilename "dump-6379.rdb" dir "/var/redis/data/" #2 6380.conf port 6380 daemonize yes logfile "6380.log" dbfilename "dump-6380.rdb" dir "/var/redis/data/" slaveof 127.0.0.1 6379 #3 6381.conf port 6381 daemonize yes logfile "6381.log" dbfilename "dump-6381.rdb" dir "/var/redis/data/" slaveof 127.0.0.1 6379- 三个redis哨兵进程,指定好,检测着谁,也是准备三个配置文件,内容如下
sentinel-26379.conf port 26379 dir /var/redis/data/ logfile "26379.log" // 当前Sentinel节点监控 192.168.182.130:6379 这个主节点 // 2代表判断主节点失败至少需要2个Sentinel节点节点同意 // mymaster是主节点的别名 sentinel monitor s21ms 0.0.0.0 6379 2 //每个Sentinel节点都要定期PING命令来判断Redis数据节点和其余Sentinel节点是否可达,如果超过30000毫秒30s且没有回复,则判定不可达 sentinel down-after-milliseconds s21ms 20000 //当Sentinel节点集合对主节点故障判定达成一致时,Sentinel领导者节点会做故障转移操作,选出新的主节点, 原来的从节点会向新的主节点发起复制操作,限制每次向新的主节点发起复制操作的从节点个数为1 sentinel parallel-syncs mymaster 1 //故障转移超时时间为180000毫秒 sentinel failover-timeout mymaster 180000 #三个哨兵的配置文件,一模一样,仅仅是端口的区别 #三个哨兵的配置文件,一模一样,仅仅是端口的区别 #三个哨兵的配置文件,一模一样,仅仅是端口的区别 sentinel-26380.conf #三个哨兵的配置文件,一模一样,仅仅是端口的区别 sentinel-26381.conf -
分别启动 三个redis数据库, 以及三个 哨兵进程 ,
- 注意 ,哨兵第一次启动后,会修改配置文件,如果错了,得删除配置文件,重新写
#配置文件在这里 # 1 sentinel-26379.conf port 26379 dir /var/redis/data/ logfile "26379.log" sentinel monitor s21ms 127.0.0.1 6379 2 sentinel down-after-milliseconds s21ms 20000 sentinel parallel-syncs s21ms 1 sentinel failover-timeout s21ms 180000 #加一个后台运行 daemonize yes #2 #仅仅是端口的不同 sentinel-26380.conf #3 sentinel-26381.conf- 启动哨兵
redis-sentinel sentinel-26379.conf redis-sentinel sentinel-26380.conf redis-sentinel sentinel-26381.conf -
验证哨兵是否正常
redis-cli -p 26379 info sentinel # 正常结果master0:name=s21ms,status=ok,address=127.0.0.1:6379,slaves=2,sentinels=3 -
干掉主库 ,检查主从切换状态
kill -9 12749 ps -ef|grep redis redis-cli -p 6380 info replication redis-cli -p 6381 info replication redis-cli -p 6380 info replication redis-cli -p 6381 info replication -
如果从库变成了主库,那么你就已经完成了,哨兵高可用配置
6.redis-cluster (集群搭建)
6.1 基础知识
-
请你先看一个图,遭遇
-
搭建集群前

-
搭建集群之后

-
-
为什么使用redis-cluster:
redis官方生成可以达到 10万/每秒,每秒执行10万条命令假如业务需要每秒100万的命令执行呢? -
数据分布原理图:

-
数据分布理论
-
分布式数据库首要解决把整个数据集按照分区规则映射到多个节点的问题,即把数据集划分到多个节点上,每个节点负责整个数据的一个子集。
-
Redis Cluster采用哈希分区规则,因此接下来会讨论哈希分区规则。节点取余分区 一致性哈希分区 虚拟槽分区(redis-cluster采用的方式)-
节点取余分区
-
一致性哈希分区
- 哈希分区1~100的数据对3取余,可以分为三类
- 余数为0
- 余数为1
- 余数为2

- 一致性哈希,客户端进行分片,哈希+顺时针取余
- 哈希分区1~100的数据对3取余,可以分为三类
-
虚拟槽分区(redis-cluster采用的方式)**
虚拟槽分区巧妙地使用了哈希空间,使用分散度良好的哈希函数把所有的数据映射到一个固定范围内的整数集合,整数定义为槽(slot)。 Redis Cluster槽的范围是0 ~ 16383。 槽是集群内数据管理和迁移的基本单位。采用大范围的槽的主要目的是为了方便数据的拆分和集群的扩展, 每个节点负责一定数量的槽。
-
-
6.2 搭建redis cluster
redis-cluster集群架构
多个服务端,负责读写,彼此通信,redis指定了16384个槽。
多匹马儿,负责运输数据,马儿分配16384个槽位,管理数据。
ruby的脚本自动就把分配槽位这事做了

-
环境准备
-
redis配置
redis-7000.conf port 7000 daemonize yes dir "/opt/redis/data" logfile "7000.log" dbfilename "dump-7000.rdb cluster-enabled yes #开启集群模式 cluster-config-file nodes-7000.conf #集群内部的配置文件 cluster-require-full-coverage no #redis cluster需要16384个slot都正常的时候才能对外提供服务,换句话说,只要任何一个slot异常那么整个cluster不对外提供服务。 因此生产环境一般为no -
准备好 6匹马儿,,6个redis节点
# 6个配置文件,仅仅是端口的区别 redis-7000.conf port 7000 daemonize yes dir "/opt/redis/data" logfile "7000.log" dbfilename "dump-7000.rdb cluster-enabled yes cluster-config-file nodes-7000.conf cluster-require-full-coverage no redis-7001.conf redis-7002.conf redis-7003.conf redis-7004.conf redis-7005.conf -
redis支持多实例的功能,我们在单机演示集群搭建,需要6个实例,三个是主节点,三个是从节点,数量为6个节点才能保证高可用的集群。
每个节点仅仅是端口运行的不同!
[root@yugo /opt/redis/config 17:12:30]#ls redis-7000.conf redis-7002.conf redis-7004.conf redis-7001.conf redis-7003.conf redis-7005.conf #确保每个配置文件中的端口修改!!
-
-
启动6个节点,6个马儿
redis-server 7000.conf redis-server 7001.conf redis-server 7002.conf redis-server 7003.conf redis-server 7004.conf redis-server 7005.conf#检查日志文件 cat 7000.log #检查redis服务的端口、进程 netstat -tunlp|grep redis ps -ef|grep redis #此时集群还不可用,可以通过登录redis查看 redis-cli -p 7000 set hello world #(error)CLUSTERDOWN The cluster is down -
分配redis slot 槽位
-
使用ruby大神 写的一个redis模块,自动分配
下载、编译、安装Ruby 安装rubygem redis 安装redis-trib.rb命令 -
下载安装ruby
#下载ruby wget https://cache.ruby-lang.org/pub/ruby/2.3/ruby-2.3.1.tar.gz #安装ruby tar -xvf ruby-2.3.1.tar.gz ./configure --prefix=/opt/ruby/ make && make install #准备一个ruby命令 #准备一个gem软件包管理命令 #拷贝ruby命令到path下/usr/local/ruby cp /opt/ruby/bin/ruby /usr/local/ cp bin/gem /usr/local/bin -
安装ruby gem 包管理工具
wget http://rubygems.org/downloads/redis-3.3.0.gem gem install -l redis-3.3.0.gem #查看gem有哪些包 gem list -- check redis gem -
安装redis-trib.rb命令
[root@yugo /opt/redis/src 18:38:13]#cp /opt/redis/src/redis-trib.rb /usr/local/bin/
-
-
一键开启redis-cluster集群
#每个主节点,有一个从节点,代表--replicas 1 redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 #集群自动分配主从关系 7000、7001、7002为 7003、7004、7005 主动关系 -
查看集群状态
redis-cli -p 7000 cluster info redis-cli -p 7000 cluster nodes #等同于查看nodes-7000.conf文件节点信息 集群主节点状态 redis-cli -p 7000 cluster nodes | grep master 集群从节点状态 redis-cli -p 7000 cluster nodes | grep slave -
安装完毕后,检查集群状态
[root@yugo /opt/redis/src 18:42:14]#redis-cli -p 7000 cluster info cluster_state:ok cluster_slots_assigned:16384 cluster_slots_ok:16384 cluster_slots_pfail:0 cluster_slots_fail:0 cluster_known_nodes:6 cluster_size:3 cluster_current_epoch:6 cluster_my_epoch:1 cluster_stats_messages_ping_sent:10468 cluster_stats_messages_pong_sent:10558 cluster_stats_messages_sent:21026 cluster_stats_messages_ping_received:10553 cluster_stats_messages_pong_received:10468 cluster_stats_messages_meet_received:5 cluster_stats_messages_received:21026
-
写在最后的话
# 测试写入集群数据,登录集群必须使用redis-cli -c -p 7000必须加上-c参数 127.0.0.1:7000> set name chao -> Redirected to slot [5798] located at 127.0.0.1:7001 OK 127.0.0.1:7001> exit [root@yugo /opt/redis/src 18:46:07]#redis-cli -c -p 7000 127.0.0.1:7000> ping PONG 127.0.0.1:7000> keys * (empty list or set) 127.0.0.1:7000> get name -> Redirected to slot [5798] located at 127.0.0.1:7001 "chao" -
工作原理:
redis主从:是备份关系, 我们操作主库,数据也会同步到从库。 如果主库机器坏了,从库可以上。就好比你 D盘的片丢了,但是你移动硬盘里边备份有。 redis哨兵:哨兵保证的是HA,保证特殊情况故障自动切换,哨兵盯着你的“redis主从集群”,如果主库死了,它会告诉你新的老大是谁。 redis集群:集群保证的是高并发,因为多了一些兄弟帮忙一起扛。同时集群会导致数据的分散,整个redis集群会分成一堆数据槽,即不同的key会放到不不同的槽中。 主从保证了数据备份,哨兵保证了HA 即故障时切换,集群保证了高并发性。redis客户端任意访问一个redis实例,如果数据不在该实例中,通过重定向引导客户端访问所需要的redis实例

 浙公网安备 33010602011771号
浙公网安备 33010602011771号