
【2020Python修炼记】MySQL之 单表查询+多表查询
一、单表查询
1、单表查询完整语法
2、关键字的执行优先级
3、select 语句关键字的定义顺序
4、select 语句关键字的执行顺序
5、单表的简单查询-举例
6、where 约束
7、group by 分组
8、having 过滤
9、order by 查询排序
10、limit 限制查询的记录数
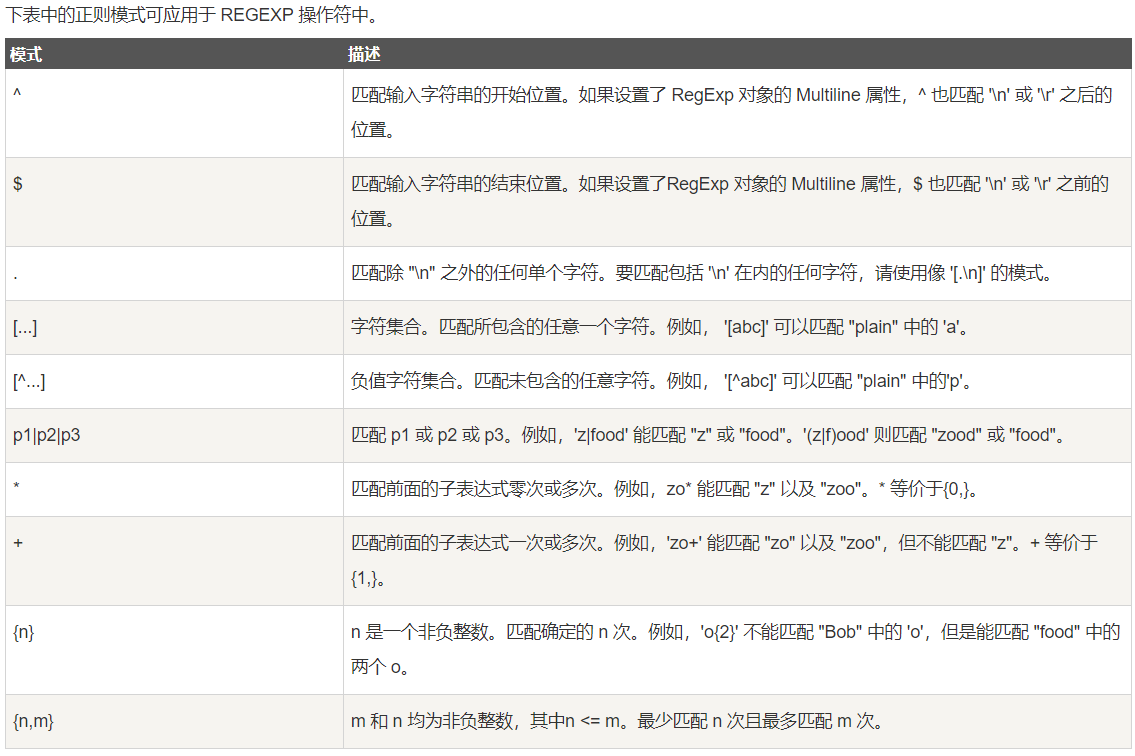
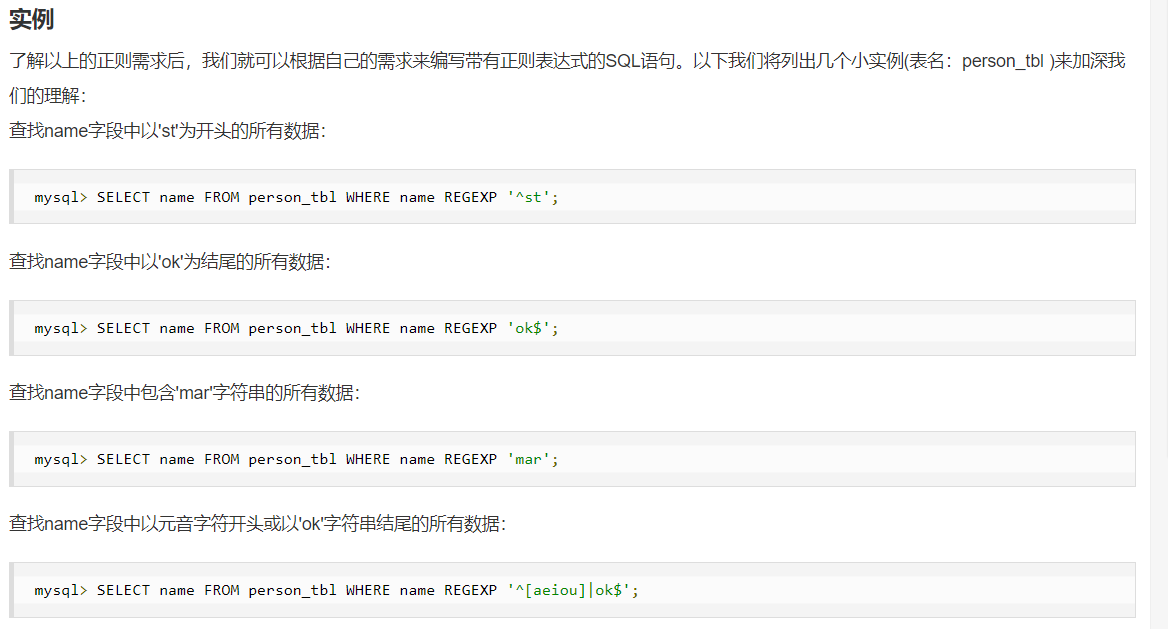
11、使用正则表达式查询
二、多表查询
# 方案一:链表
# 方案二:子查询
一、单表查询


create table emp( id int not null unique auto_increment, name varchar(20) not null, sex enum('male','female') not null default 'male', #大部分是男的 age int(3) unsigned not null default 28, hire_date date not null, post varchar(50), post_comment varchar(100), salary double(15,2), office int, #一个部门一个屋子 depart_id int ); #插入记录 #三个部门:教学,销售,运营 insert into emp(name,sex,age,hire_date,post,salary,office,depart_id) values ('jason','male',18,'20170301','张江第一帅形象代言',7300.33,401,1), #以下是教学部 ('tom','male',78,'20150302','teacher',1000000.31,401,1), ('kevin','male',81,'20130305','teacher',8300,401,1), ('tony','male',73,'20140701','teacher',3500,401,1), ('owen','male',28,'20121101','teacher',2100,401,1), ('jack','female',18,'20110211','teacher',9000,401,1), ('jenny','male',18,'19000301','teacher',30000,401,1), ('sank','male',48,'20101111','teacher',10000,401,1), ('哈哈','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门 ('呵呵','female',38,'20101101','sale',2000.35,402,2), ('西西','female',18,'20110312','sale',1000.37,402,2), ('乐乐','female',18,'20160513','sale',3000.29,402,2), ('拉拉','female',28,'20170127','sale',4000.33,402,2), ('僧龙','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门 ('程咬金','male',18,'19970312','operation',20000,403,3), ('程咬银','female',18,'20130311','operation',19000,403,3), ('程咬铜','male',18,'20150411','operation',18000,403,3), ('程咬铁','female',18,'20140512','operation',17000,403,3);
# 当表字段特别多 展示的时候错乱 可以使用\G分行展示
select * from emp\G;# 个别同学的电脑在插入中文的时候还是会出现乱码或者空白的现象 你可以将字符编码统一设置成GBK
cmd 指令:chcp 936
参考阅读:https://jingyan.baidu.com/article/d7130635e8a38413fdf4753b.html
# 书写顺序 select id,name from emp where id > 3; # 执行顺序 from where select """ 虽然执行顺序和书写顺序不一致 你在写sql语句的时候可能不知道怎么写 你就按照书写顺序的方式写sql select * 先用*号占位 之后去补全后面的sql语句 最后将*号替换后你想要的具体字段 """
# 作用:是对整体数据的一个筛选操作 # 1.查询id大于等于3小于等于6的数据 select id,name,age from emp where id>=3 and id<=6; select id,name from emp where id between 3 and 6; 两者等价 # 2.查询薪资是20000或者18000或者17000的数据 select * from emp where salary=20000 or salary=18000 or salary=17000; select * from emp where salary in (20000,18000,17000); # 3.查询员工姓名中包含字母o的员工的姓名和薪资 """ 模糊查询 like % 匹配任意多个字符 _ 匹配任意单个字符 """ select name,salary from emp where name like '%o%'; # 4.查询员工姓名是由四个字符组成的 姓名和薪资 char_length() _ select name,salary from emp where name like '____'; select name,salary from emp where char_length(name) = 4; # 5.查询id小于3或者id大于6的数据 select * from emp where id not between 3 and 6; # 6.查询薪资不在20000,18000,17000范围的数据 select * from emp where salary not in (20000,18000,17000); # 7.查询岗位描述为空的员工姓名和岗位名 针对null不用等号 用is select name,post from emp where post_comment = NULL; select name,post from emp where post_comment is NULL;
# 分组实际应用场景 分组应用场景非常的多 男女比例 部门平均薪资 部门秃头率 国家之间数据统计 # 1 按照部门分组 select * from emp group by post; """ 分组之后 最小可操作单位应该是组 还不再是组内的单个数据 上述命令在你没有设置严格模式的时候是可正常执行的 返回的是分组之后 每个组的第一条数据 但是这不符合分组的规范:分组之后不应该考虑单个数据 而应该以组为操作单位(分组之后 没办法直接获取组内单个数据) 如果设置了严格模式 那么上述命令会直接报错 """ set global sql_mode = 'strict_trans_tables,only_full_group_by'; 设置严格模式之后 分组 默认只能拿到分组的依据 select post from emp group by post; 按照什么分组就只能拿到分组 其他字段不能直接获取 需要借助于一些方法(聚合函数) """ 什么时候需要分组啊??? 关键字 每个 平均 最高 最低 聚合函数 max min sum count avg """ # 1.获取每个部门的最高薪资 select post,max(salary) from emp group by post; select post as '部门',max(salary) as '最高薪资' from emp group by post; select post '部门',max(salary) '最高薪资' from emp group by post; # as可以给字段起别名 也可以直接省略不写 但是不推荐 因为省略的话语意不明确 容易错乱 # 2.获取每个部门的最低薪资 select post,min(salary) from emp group by post; # 3.获取每个部门的平均薪资 select post,avg(salary) from emp group by post; # 4.获取每个部门的工资总和 select post,sum(salary) from emp group by post; # 5.获取每个部门的人数 select post,count(id) from emp group by post; # 常用 符合逻辑 select post,count(salary) from emp group by post; select post,count(age) from emp group by post; select post,count(post_comment) from emp group by post; null不行 # 6.查询分组之后的部门名称和每个部门下所有的员工姓名 # group_concat不单单可以支持你获取分组之后的其他字段值 还支持拼接操作 select post,group_concat(name) from emp group by post; select post,group_concat(name,'_DSB') from emp group by post; select post,group_concat(name,':',salary) from emp group by post; # concat不分组的时候用 select concat('NAME:',name),concat('SAL:',salary) from emp; # 补充 as语法不单单可以给字段起别名 还可以给表临时起别名 select emp.id,emp.name from emp; select emp.id,emp.name from emp as t1; 报错 select t1.id,t1.name from emp as t1; # 查询每个人的年薪 12薪 select name,salary*12 from emp;
--WITH ROLLUP 可以实现在分组统计数据基础上再进行相同的统计(SUM,AVG,COUNT…)。 --例如我们将以上的数据表按名字进行分组,再统计每个人登录的次数: mysql> SELECT name, SUM(singin) as singin_count FROM employee_tbl GROUP BY name WITH ROLLUP; +--------+--------------+ | name | singin_count | +--------+--------------+ | 小丽 | 2 | | 小明 | 7 | | 小王 | 7 | | NULL | 16 | +--------+--------------+ 4 rows in set (0.00 sec) --其中记录 NULL 表示所有人的登录次数。 -- ==》我们可以使用 coalesce 来设置一个可以取代 NUll 的名称,coalesce 语法: select coalesce(a,b,c); --参数说明:如果a==null,则选择b;如果b==null,则选择c;如果a!=null,则选择a;如果a b c 都为null ,则返回为null(没意义)。 --以下实例中如果名字为空我们使用总数代替: mysql> SELECT coalesce(name, '总数'), SUM(singin) as singin_count FROM employee_tbl GROUP BY name WITH ROLLUP; +--------------------------+--------------+ | coalesce(name, '总数') | singin_count | +--------------------------+--------------+ | 小丽 | 2 | | 小明 | 7 | | 小王 | 7 | | 总数 | 16 | +--------------------------+--------------+ 4 rows in set (0.01 sec)
# 关键字where和group by同时出现的时候group by必须在where的后面 where先对整体数据进行过滤之后再分组操作 where筛选条件不能使用聚合函数 select id,name,age from emp where max(salary) > 3000; select max(salary) from emp; # 不分组 默认整体就是一组 # 统计各部门年龄在30岁以上的员工平均薪资 1 先求所有年龄大于30岁的员工 select * from emp where age>30; 2 再对结果进行分组 select * from emp where age>30 group by post; select post,avg(salary) from emp where age>30 group by post;
""" having的语法根where是一致的 只不过having是在分组之后进行的过滤操作 即having是可以直接使用聚合函数的 """ # 统计各部门年龄在30岁以上的员工平均工资并且保留平均薪资大于10000的部门 select post,avg(salary) from emp where age>30 group by post having avg(salary) > 10000 ;
""" 一定要注意 必须是完全一样的数据才可以去重!!! 一定不要将逐渐忽视了 有逐渐存在的情况下 是不可能去重的 [ {'id':1,'name':'jason','age':18}, {'id':2,'name':'jason','age':18}, {'id':3,'name':'egon','age':18} ] ORM 对象关系映射 让不懂SQL语句的人也能够非常牛逼的操作数据库 表 类 一条条的数据 对象 字段对应的值 对象的属性 你再写类 就意味着在创建表 用类生成对象 就意味着再创建数据 对象点属性 就是在获取数据字段对应的值 目的就是减轻python程序员的压力 只需要会python面向对象的知识点就可以操作MySQL """ select distinct id,age from emp; select distinct age from emp;
select * from emp order by salary; select * from emp order by salary asc; select * from emp order by salary desc; """ order by默认是升序 asc 该asc可以省略不写 也可以修改为降序 desc """ select * from emp order by age desc,salary asc; # 先按照age降序排 如果碰到age相同 则再按照salary升序排 # 统计各部门年龄在10岁以上的员工平均工资并且保留平均薪资大于1000的部门,然后对平均工资降序排序 select post,avg(salary) from emp where age>10 group by post having avg(salary) > 1000 order by avg(salary) desc ;
--MySQL 排序我们知道从 MySQL 表中使用 SQL SELECT 语句来读取: --MySQL 拼音排序 --如果字符集采用的是 gbk(汉字编码字符集),直接在查询语句后边添加 ORDER BY: SELECT * FROM runoob_tbl ORDER BY runoob_title; --如果字符集采用的是 utf8(万国码),需要先对字段进行转码然后排序: SELECT * FROM runoob_tbl ORDER BY CONVERT(runoob_title using gbk);
"""针对数据过多的情况 我们通常都是做分页处理""" select _column,_column from _table [where Clause] [limit N][offset M] select * : 返回所有记录 limit N : 返回 N 条记录 offset M : 跳过 M 条记录, 默认 M=0, 单独使用似乎不起作用 limit N,M : 相当于 limit M offset N , 从第 N 条记录开始, 返回 M 条记录 select * from emp; select * from emp limit 3; # 只展示三条数据 select * from emp limit 0,5; select * from emp limit 5,5; 第一个参数是起始位置,即 偏移量 第二个参数是展示条数,即查询条数
select * from emp where name regexp '^j.*(n|y)$';
like 匹配/模糊匹配,会与 % 和 _ 结合使用。 '%a' //以a结尾的数据 'a%' //以a开头的数据 '%a%' //含有a的数据 '_a_' //三位且中间字母是a的 '_a' //两位且结尾字母是a的 'a_' //两位且开头字母是a的 查询以 java 字段开头的信息。 SELECT * FROM position WHERE name LIKE 'java%'; 查询包含 java 字段的信息。 SELECT * FROM position WHERE name LIKE '%java%'; 查询以 java 字段结尾的信息。 SELECT * FROM position WHERE name LIKE '%java';
在 where like 的条件查询中,SQL 提供了四种匹配方式。 %:表示任意 0 个或多个字符。可匹配任意类型和长度的字符,有些情况下若是中文,请使用两个百分号(%%)表示。 _:表示任意单个字符。匹配单个任意字符,它常用来限制表达式的字符长度语句。 []:表示括号内所列字符中的一个(类似正则表达式)。指定一个字符、字符串或范围,要求所匹配对象为它们中的任一个。 [^] :表示不在括号所列之内的单个字符。其取值和 [] 相同,但它要求所匹配对象为指定字符以外的任一个字符。 查询内容包含通配符时,由于通配符的缘故,导致我们查询特殊字符 “%”、“_”、“[” 的语句无法正常实现,而把特殊字符用 “[ ]” 括起便可正常查询。
==1 单表查询完整语法 select 字段1,字段2(可以取别名: as 别名),, from 表名 where 条件 group by 字段 having 条件 order by 字段 limit 记录条数 ==2 关键字的执行优先级 from where 最大条件 group by 分组 having 过滤筛选 select 选择 distinct 去重 order by 按照条件排序 limit 限制查询结果的显示条数 1.找到表:from 2.拿着where指定的约束条件,去文件/表中取出一条条记录 3.将取出的一条条记录进行分组group by,如果没有group by,则整体作为一组 4.将分组的结果进行having过滤 5.执行select 6.去重 7.将结果按条件排序:order by 8.限制结果的显示条数 ==3 select 语句关键字的定义顺序 SELECT DISTINCT <select_list> FROM <left_table> <join_type> JOIN <right_table> ON <join_condition> # 连接表 WHERE <where_condition> GROUP BY <group_by_list> HAVING <having_condition> # having语句主要和 group by语句配合使用 ORDER BY <order_by_condition> LIMIT <limit_number> ==4 select 语句关键字的执行顺序 (7) SELECT (8) DISTINCT <select_list> (1) FROM <left_table> (3) <join_type> JOIN <right_table> (2) ON <join_condition> (4) WHERE <where_condition> (5) GROUP BY <group_by_list> (6) HAVING <having_condition> (9) ORDER BY <order_by_condition> (10) LIMIT <limit_number> # --------------------------------------------------- ==5 单表查询-举例 --简单查询 select id,name,sex from t1; select * from t1; --避免重复 distinct select distinct name from t1; --通过四则运算查询 select name,money*12 from t1; select name,money*12 as sum_money from t1; # 使用 as 给字段取别名(通常是以查询语句为字段) select name,money*12 sum_money from t1; # 也可以省略 as,直接在字段后面 加上别名 --定义显示格式 concat() 该函数 用于连接字符串 select concat('姓名:',name,'年薪:',money*12) as sum_money from t1; concat_ws() 第一个参数为分隔符 select concat_ws(':',name,money*12) as sum_money from t1; 结合case语句 --- 分情况定义不同的显示格式 select( case when name = 'egon' then name when name = 'alex' then concat(name,'_BIGSB') else concat(name, 'SB') end ) as new_name from t1; # --------------------------------------------------- ==6 where 约束 --1 条件设置 where字句中可以使用: 1. 比较运算符:> < >= <= <> != 2. between 80 and 100 值在10到20之间 3. in(80,90,100) 值是10或20或30 4. like 'egon%' pattern可以是%或_, %表示任意多字符 _表示一个字符 5. 逻辑运算符:在多个条件直接可以使用逻辑运算符 and or not --2 查询语句举例 ----单条件查询 select name form t1 where id=1; ----多条件查询 select name,money from t1 where age=18 and money>1200; select name,money from t1 where age=18 or money>1200; ----关键字 between and select name money from t1 where age between 18 and 30 select name money from t1 where age not between 18 and 30 ----关键字 is null(判断某个字段是否为 null 不能用等号,需要用 is) select name,money from t1 where money is null; select name,money from t1 where money is not null; select name,money from t1 where money is ''; # 注意''是空字符串(有为空的数据),不是null(没有数据) ----关键字 in集合 查询 select name,age from t1 where age=18 or age=20 or age=34; select name,age from t1 where age in (18,20,34); select name,age from t1 where age not in (18,20,34); ----关键字 like 模糊查询 _ 代表任意单个字符 % 代表任意多个字符 使用正则表达式 查询条件 regexp '正则表达式' select * from t1 where name like'e%'; # % 代表任意多个字符 select * from t1 where name like'al_'; # _ 代表任意单个字符 # --------------------------------------------------- ==7 group by 分组查询 # ---------------------------------- 【数据准备】 company.employee 员工id id int 姓名 emp_name varchar 性别 sex enum 年龄 age int 入职日期 hire_date date 岗位 post varchar 职位描述 post_comment varchar 薪水 salary double 办公室 office int 部门编号 depart_id int #创建表 create table employee( id int not null unique auto_increment, name varchar(20) not null, sex enum('male','female') not null default 'male', #大部分是男的 age int(3) unsigned not null default 28, hire_date date not null, post varchar(50), post_comment varchar(100), salary double(15,2), office int, #一个部门一个屋子 depart_id int ); #查看表结构 mysql> desc employee; +--------------+-----------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------------+-----------------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | varchar(20) | NO | | NULL | | | sex | enum('male','female') | NO | | male | | | age | int(3) unsigned | NO | | 28 | | | hire_date | date | NO | | NULL | | | post | varchar(50) | YES | | NULL | | | post_comment | varchar(100) | YES | | NULL | | | salary | double(15,2) | YES | | NULL | | | office | int(11) | YES | | NULL | | | depart_id | int(11) | YES | | NULL | | +--------------+-----------------------+------+-----+---------+----------------+ #插入记录 #三个部门:教学,销售,运营 insert into employee(name,sex,age,hire_date,post,salary,office,depart_id) values ('egon','male',18,'20170301','老男孩驻沙河办事处外交大使',7300.33,401,1), #以下是教学部 ('alex','male',78,'20150302','teacher',1000000.31,401,1), ('wupeiqi','male',81,'20130305','teacher',8300,401,1), ('yuanhao','male',73,'20140701','teacher',3500,401,1), ('liwenzhou','male',28,'20121101','teacher',2100,401,1), ('jingliyang','female',18,'20110211','teacher',9000,401,1), ('jinxin','male',18,'19000301','teacher',30000,401,1), ('成龙','male',48,'20101111','teacher',10000,401,1), ('歪歪','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门 ('丫丫','female',38,'20101101','sale',2000.35,402,2), ('丁丁','female',18,'20110312','sale',1000.37,402,2), ('星星','female',18,'20160513','sale',3000.29,402,2), ('格格','female',28,'20170127','sale',4000.33,402,2), ('张野','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门 ('程咬金','male',18,'19970312','operation',20000,403,3), ('程咬银','female',18,'20130311','operation',19000,403,3), ('程咬铜','male',18,'20150411','operation',18000,403,3), ('程咬铁','female',18,'20140512','operation',17000,403,3) ; #ps:如果在windows系统中,插入中文字符,select的结果为空白,可以将所有字符编码统一设置成gbk # --------------------------------- ---1 什么是分组 分组发生在where之后,即分组是基于where之后得到的记录而进行的 可以按照任意字段分组,但是分组完毕后,只能查看分组依据所在字段的信息 比如group by post,只能查看post字段,如果想查看组内信息,需要借助于聚合函数 ---2 group by 的应用 单独使用GROUP BY关键字分组 SELECT post FROM employee GROUP BY post; 注意:我们按照post字段分组,那么select查询的字段只能是post,想要获取组内的其他相关信息,需要借助函数 GROUP BY关键字和GROUP_CONCAT()函数一起使用 SELECT post,GROUP_CONCAT(name) FROM employee GROUP BY post;#按照岗位分组,并查看组内成员名 SELECT post,GROUP_CONCAT(name) as emp_members FROM employee GROUP BY post; GROUP BY与聚合函数一起使用 select post,count(id) as count from employee group by post;#按照岗位分组,并查看每个组有多少人 【注意】 如果我们用unique的字段作为分组的依据,则每一条记录自成一组,这种分组没有意义 多条记录之间的某个字段值相同,该字段通常用来作为分组的依据。 ---3 聚合函数 min() max() sum() avg() count() 聚合函数聚合的是组的内容,若是没有分组,则默认一组 SELECT COUNT(*) FROM employee; SELECT COUNT(*) FROM employee WHERE depart_id=1; SELECT MAX(salary) FROM employee; SELECT MIN(salary) FROM employee; SELECT AVG(salary) FROM employee; SELECT SUM(salary) FROM employee; SELECT SUM(salary) FROM employee WHERE depart_id=3; ---4 only_full_group_by --- 一种SQL模式 (1) #查看MySQL 5.7默认的sql_mode如下: select @@global.sql_mode; # SQL模式: # ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE, # ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION (2) ONLY_FULL_GROUP_BY的语义就是 确定select target list中的所有列的值都是明确语义, 简单的说来,在ONLY_FULL_GROUP_BY模式下,target list中的值要么是来自于聚集函数的结果,要么是来自于group by list中的表达式的值。 (3)设置sql_mode(设置后,需要退出MySQL,然后重新登录) # 例如:去除ONLY_FULL_GROUP_BY模式(直接把 模式列表里的该模式去除,重新设置mysql模式即可) set global sql_mode = 'STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION'; # --------------------------------------------------- ==8 having 过滤 --1 having 和 where 的区别 执行优先级从高到低:where > group by > having #1. Where 发生在分组group by之前,因而Where中可以有任意字段,但是绝对不能使用聚合函数。 #2. Having发生在分组group by之后,因而Having中可以使用分组后的字段,无法直接取到其他字段,可以使用聚合函数 【举例子 1 】 mysql> select @@sql_mode; +--------------------+ | @@sql_mode | +--------------------+ | ONLY_FULL_GROUP_BY | +--------------------+ 1 row in set (0.00 sec) mysql> select * from emp where salary > 100000; +----+------+------+-----+------------+---------+--------------+------------+--------+-----------+ | id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id | +----+------+------+-----+------------+---------+--------------+------------+--------+-----------+ | 2 | alex | male | 78 | 2015-03-02 | teacher | NULL | 1000000.31 | 401 | 1 | +----+------+------+-----+------------+---------+--------------+------------+--------+-----------+ 1 row in set (0.00 sec) mysql> select * from emp having salary > 100000; ERROR 1463 (42000): Non-grouping field 'salary' is used in HAVING clause mysql> select post,group_concat(name) from emp group by post having salary > 10000;#错误,分组后无法直接取到salary字段 ERROR 1054 (42S22): Unknown column 'salary' in 'having clause' mysql> select post,group_concat(name) from emp group by post having avg(salary) > 10000; +-----------+-------------------------------------------------------+ | post | group_concat(name) | +-----------+-------------------------------------------------------+ | operation | 程咬铁,程咬铜,程咬银,程咬金,张野 | | teacher | 成龙,jinxin,jingliyang,liwenzhou,yuanhao,wupeiqi,alex | +-----------+-------------------------------------------------------+ 2 rows in set (0.00 sec) 【举例子 2 】 # 1. 查询各岗位内包含的员工个数小于2的岗位名、岗位内包含员工名字、个数 # 3. 查询各岗位平均薪资大于10000的岗位名、平均工资 # 4. 查询各岗位平均薪资大于10000且小于20000的岗位名、平均工资 #题1: mysql> select post,group_concat(name),count(id) from employee group by post having count(id) < 2; +-----------------------------------------+--------------------+-----------+ | post | group_concat(name) | count(id) | +-----------------------------------------+--------------------+-----------+ | 老男孩驻沙河办事处外交大使 | egon | 1 | +-----------------------------------------+--------------------+-----------+ #题目2: mysql> select post,avg(salary) from employee group by post having avg(salary) > 10000; +-----------+---------------+ | post | avg(salary) | +-----------+---------------+ | operation | 16800.026000 | | teacher | 151842.901429 | +-----------+---------------+ #题目3: mysql> select post,avg(salary) from employee group by post having avg(salary) > 10000 and avg(salary) <20000; +-----------+--------------+ | post | avg(salary) | +-----------+--------------+ | operation | 16800.026000 | +-----------+--------------+ # ------------------------------------------- ==9 order by 查询排序 (1)单列排序和多列排序 按单列排序 SELECT * FROM employee ORDER BY salary; SELECT * FROM employee ORDER BY salary ASC; SELECT * FROM employee ORDER BY salary DESC; 按多列排序:先按照age排序,如果年纪相同,则按照薪资排序 SELECT * from employee ORDER BY age, salary DESC; =desc 降序 =asc 升序 【栗子+】 # 1. 查询所有员工信息,先按照age升序排序,如果age相同则按照hire_date降序排序 # 2. 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资升序排列 # 3. 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资降序排列 #题目1 mysql> select * from employee ORDER BY age asc,hire_date desc; #题目2 mysql> select post,avg(salary) from employee group by post having avg(salary) > 10000 order by avg(salary) asc; +-----------+---------------+ | post | avg(salary) | +-----------+---------------+ | operation | 16800.026000 | | teacher | 151842.901429 | +-----------+---------------+ #题目3 mysql> select post,avg(salary) from employee group by post having avg(salary) > 10000 order by avg(salary) desc; +-----------+---------------+ | post | avg(salary) | +-----------+---------------+ | teacher | 151842.901429 | | operation | 16800.026000 | +-----------+---------------+ # ---------------------------------------------------- ==10 limit 限制查询的记录数 # 示例1: SELECT * FROM employee ORDER BY salary DESC LIMIT 3; #默认初始位置为0 SELECT * FROM employee ORDER BY salary DESC LIMIT 0,5; #从第0开始,即先查询出第一条,然后包含这一条在内往后查5条 SELECT * FROM employee ORDER BY salary DESC LIMIT 5,5; #从第5开始,即先查询出第6条,然后包含这一条在内往后查5条 # 示例2: # 分页显示,每页5条 mysql> select * from employee limit 0,5; +----+-----------+------+-----+------------+-----------------------------------------+--------------+------------+--------+-----------+ | id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id | +----+-----------+------+-----+------------+-----------------------------------------+--------------+------------+--------+-----------+ | 1 | egon | male | 18 | 2017-03-01 | 老男孩驻沙河办事处外交大使 | NULL | 7300.33 | 401 | 1 | | 2 | alex | male | 78 | 2015-03-02 | teacher | | 1000000.31 | 401 | 1 | | 3 | wupeiqi | male | 81 | 2013-03-05 | teacher | NULL | 8300.00 | 401 | 1 | | 4 | yuanhao | male | 73 | 2014-07-01 | teacher | NULL | 3500.00 | 401 | 1 | | 5 | liwenzhou | male | 28 | 2012-11-01 | teacher | NULL | 2100.00 | 401 | 1 | +----+-----------+------+-----+------------+-----------------------------------------+--------------+------------+--------+-----------+ 5 rows in set (0.00 sec) mysql> select * from employee limit 5,5; +----+------------+--------+-----+------------+---------+--------------+----------+--------+-----------+ | id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id | +----+------------+--------+-----+------------+---------+--------------+----------+--------+-----------+ | 6 | jingliyang | female | 18 | 2011-02-11 | teacher | NULL | 9000.00 | 401 | 1 | | 7 | jinxin | male | 18 | 1900-03-01 | teacher | NULL | 30000.00 | 401 | 1 | | 8 | 成龙 | male | 48 | 2010-11-11 | teacher | NULL | 10000.00 | 401 | 1 | | 9 | 歪歪 | female | 48 | 2015-03-11 | sale | NULL | 3000.13 | 402 | 2 | | 10 | 丫丫 | female | 38 | 2010-11-01 | sale | NULL | 2000.35 | 402 | 2 | +----+------------+--------+-----+------------+---------+--------------+----------+--------+-----------+ 5 rows in set (0.00 sec) mysql> select * from employee limit 10,5; +----+-----------+--------+-----+------------+-----------+--------------+----------+--------+-----------+ | id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id | +----+-----------+--------+-----+------------+-----------+--------------+----------+--------+-----------+ | 11 | 丁丁 | female | 18 | 2011-03-12 | sale | NULL | 1000.37 | 402 | 2 | | 12 | 星星 | female | 18 | 2016-05-13 | sale | NULL | 3000.29 | 402 | 2 | | 13 | 格格 | female | 28 | 2017-01-27 | sale | NULL | 4000.33 | 402 | 2 | | 14 | 张野 | male | 28 | 2016-03-11 | operation | NULL | 10000.13 | 403 | 3 | | 15 | 程咬金 | male | 18 | 1997-03-12 | operation | NULL | 20000.00 | 403 | 3 | +----+-----------+--------+-----+------------+-----------+--------------+----------+--------+-----------+ 5 rows in set (0.00 sec) # --------------------------------------- ==11 使用正则表达式查询 参考: https://zhuanlan.zhihu.com/p/28672572 * 表示 匹配0-n次,优先匹配n次,相当于{0,} ^ 放在[]内的字符前面,表示 非(不是/取反)的意思——[^abc] 表示能够匹配abc之外的任意字符 ^在[]外表示匹配开头的意思——^abc // 可以匹配abc,但是不能匹配aabc $ 表示匹配结尾的意思 abc$ 可以匹配abc,但是不能匹配abcc % a{2} {n}匹配n次,比如a{2},匹配aa [abc] 字符集,匹配中括号内的任意一个字符 (1) SELECT * FROM employee WHERE name REGEXP '^ale'; SELECT * FROM employee WHERE name REGEXP 'on$'; SELECT * FROM employee WHERE name REGEXP 'm{2}'; 小结:对字符串匹配的方式 WHERE name = 'egon'; WHERE name LIKE 'yua%'; WHERE name REGEXP 'on$'; (2) 查看所有员工中名字是jin开头,n或者g结果的员工信息 select * from employee where name regexp '^jin.*[gn]$';
二、多表查询
前期表准备
```python #建表 create table dep( id int, name varchar(20) ); create table emp( id int primary key auto_increment, name varchar(20), sex enum('male','female') not null default 'male', age int, dep_id int ); #插入数据 insert into dep values (200,'技术'), (201,'人力资源'), (202,'销售'), (203,'运营'); insert into emp(name,sex,age,dep_id) values ('jason','male',18,200), ('egon','female',48,201), ('kevin','male',18,201), ('nick','male',28,202), ('owen','male',18,203), ('jerry','female',18,204); ```
表查询
select * from dep,emp; # 结果 笛卡尔积 """ 了解即可 不知道也没关系 """ select * from emp,dep where emp.dep_id = dep.id; """ MySQL也知道 你在后面查询数据过程中 肯定会经常用到拼表操作 所以特地给你开设了对应的方法 inner join 内连接 left join 左连接 right join 右连接 union 全连接 """ # inner join 内连接 select * from emp inner join dep on emp.dep_id = dep.id; # 只拼接两张表中公有的数据部分 # left join 左连接 select * from emp left join dep on emp.dep_id = dep.id; # 左表所有的数据都展示出来 没有对应的项就用NULL # right join 右连接 select * from emp right join dep on emp.dep_id = dep.id; # 右表所有的数据都展示出来 没有对应的项就用NULL # union 全连接 左右两表所有的数据都展示出来 select * from emp left join dep on emp.dep_id = dep.id union select * from emp right join dep on emp.dep_id = dep.id;
子查询
""" 子查询就是我们平时解决问题的思路 分步骤解决问题 第一步 第二步 ... 将一个查询语句的结果当做另外一个查询语句的条件去用 """ # 查询部门是技术或者人力资源的员工信息 1 先获取部门的id号 2 再去员工表里面筛选出对应的员工 select id from dep where name='技术' or name = '人力资源'; select name from emp where dep_id in (200,201); select * from emp where dep_id in (select id from dep where name='技术' or name = '人力资源');
总结:
表的查询结果可以作为其他表的查询条件
也可以通过起别名的方式把它作为一个张虚拟表根其他表关联"""
多表查询就两种方式
先拼接表再查询
子查询 一步一步来
"""
union
UNION 语句:用于将不同表中相同列中查询的数据展示出来;(不包括重复数据) UNION ALL 语句:用于将不同表中相同列中查询的数据展示出来;(包括重复数据) 使用形式如下: SELECT 列名称 FROM 表名称 UNION SELECT 列名称 FROM 表名称 ORDER BY 列名称; SELECT 列名称 FROM 表名称 UNION ALL SELECT 列名称 FROM 表名称 ORDER BY 列名称;
1、多表联合查询 # ---------------------- 【数据准备】 mysql> create database db97; mysql> use db97; mysql> create table department(id int,name varchar(20)); mysql> create table employee( id int primary key auto_increment, name varchar(20), sex enum('male','female')not null default 'male', age int, dep_id int); mysql> insert into department values(200,'jishu'),(201,'renli'),(202,'xiaoshou'),(203,'yunying'); mysql>insert into employee(name,sex,age,dep_id) values('egon','male',48,200),('cc','male',18,201),('mili','female',19,202),('mela','male',28,204); mysql> show tables; +----------------+ | Tables_in_db97 | +----------------+ | department | | employee | +----------------+ mysql> select * from employee; +----+------+--------+------+--------+ | id | name | sex | age | dep_id | +----+------+--------+------+--------+ | 1 | egon | male | 48 | 200 | | 2 | cc | male | 18 | 201 | | 3 | mili | female | 19 | 202 | | 4 | mela | male | 28 | 204 | +----+------+--------+------+--------+ mysql> select * from department; +------+----------+ | id | name | +------+----------+ | 200 | jishu | | 201 | renli | | 202 | xiaoshou | | 203 | yunying | +------+----------+ # 给表取别名 mysql> alter table employee rename emp; mysql> alter table department rename dep; # 方案一:链表 # 把多张物理表合并成一张虚拟表,再进行后续查询 # 外链接语法 SELECT 字段列表 FROM 表1 INNER|LEFT|RIGHT JOIN 表2 ON 表1.字段 = 表2.字段; # =交叉连接:不使用任何匹配条件,生成 笛卡尔积 mysql> select * from emp,dep; +----+------+--------+------+--------+------+----------+ | id | name | sex | age | dep_id | id | name | +----+------+--------+------+--------+------+----------+ | 1 | egon | male | 48 | 200 | 200 | jishu | | 2 | cc | male | 18 | 201 | 200 | jishu | | 3 | mili | female | 19 | 202 | 200 | jishu | | 4 | mela | male | 28 | 204 | 200 | jishu | | 1 | egon | male | 48 | 200 | 201 | renli | | 2 | cc | male | 18 | 201 | 201 | renli | | 3 | mili | female | 19 | 202 | 201 | renli | | 4 | mela | male | 28 | 204 | 201 | renli | | 1 | egon | male | 48 | 200 | 202 | xiaoshou | | 2 | cc | male | 18 | 201 | 202 | xiaoshou | | 3 | mili | female | 19 | 202 | 202 | xiaoshou | | 4 | mela | male | 28 | 204 | 202 | xiaoshou | | 1 | egon | male | 48 | 200 | 203 | yunying | | 2 | cc | male | 18 | 201 | 203 | yunying | | 3 | mili | female | 19 | 202 | 203 | yunying | | 4 | mela | male | 28 | 204 | 203 | yunying | +----+------+--------+------+--------+------+----------+ # =内连接:join…on 只连接匹配的行 # 保存两张表 有对应关系的记录 mysql> select * from emp,dep where emp.id=dep.id; # 查询结果为空,因为emp 表的id 有两个,因此无法匹配。 mysql> select * from emp,dep where emp.dep_id=dep.id; mysql> select dep.name,emp.name from emp inner join dep on emp.dep_id=dep.id where dep.name ='jishu'; # 表连接查询 可以增加筛选条件 +-------+------+ | name | name | +-------+------+ | jishu | egon | +-------+------+ # =左连接 left join…on # 在内链接的基础上保留左表的记录 mysql> select * from emp left join dep on emp.id=dep.id; +----+------+--------+------+--------+------+------+ | id | name | sex | age | dep_id | id | name | +----+------+--------+------+--------+------+------+ | 1 | egon | male | 48 | 200 | NULL | NULL | | 2 | cc | male | 18 | 201 | NULL | NULL | | 3 | mili | female | 19 | 202 | NULL | NULL | | 4 | mela | male | 28 | 204 | NULL | NULL | +----+------+--------+------+--------+------+------+ # =右连接 right join…on # 在内链接的基础上保留右表的记录 mysql> select * from emp right join dep on emp.id=dep.id; +------+------+------+------+--------+------+----------+ | id | name | sex | age | dep_id | id | name | +------+------+------+------+--------+------+----------+ | NULL | NULL | NULL | NULL | NULL | 200 | jishu | | NULL | NULL | NULL | NULL | NULL | 201 | renli | | NULL | NULL | NULL | NULL | NULL | 202 | xiaoshou | | NULL | NULL | NULL | NULL | NULL | 203 | yunying | +------+------+------+------+--------+------+----------+ # =全外连接 # 左连接 union 右连接 # mysql 不支持 full join,但是可以通过 左连接结果 union 右连接结果 # 在内链接的基础上保留左右表的记录 mysql> select * from emp right join dep on emp.id=dep.id union select * from emp left join dep on emp.id=dep.id; +------+------+--------+------+--------+------+----------+ | id | name | sex | age | dep_id | id | name | +------+------+--------+------+--------+------+----------+ | NULL | NULL | NULL | NULL | NULL | 200 | jishu | | NULL | NULL | NULL | NULL | NULL | 201 | renli | | NULL | NULL | NULL | NULL | NULL | 202 | xiaoshou | | NULL | NULL | NULL | NULL | NULL | 203 | yunying | | 1 | egon | male | 48 | 200 | NULL | NULL | | 2 | cc | male | 18 | 201 | NULL | NULL | | 3 | mili | female | 19 | 202 | NULL | NULL | | 4 | mela | male | 28 | 204 | NULL | NULL | +------+------+--------+------+--------+------+----------+ # ---------》 # 方案二:子查询 子查询是将一个查询语句嵌套在另一个查询语句中。 内层查询语句的查询结果,可以为外层查询语句提供查询条件。 子查询中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等关键字 还可以包含比较运算符:= 、 !=、> 、<等 mysql> select * from (select emp.*,dep.name as dep_name from emp inner join dep on emp.dep_id = dep.id) as t1 inner join dep on t1.dep_id = dep.id; +----+------+--------+------+--------+----------+------+----------+ | id | name | sex | age | dep_id | dep_name | id | name | +----+------+--------+------+--------+----------+------+----------+ | 1 | egon | male | 48 | 200 | jishu | 200 | jishu | | 2 | cc | male | 18 | 201 | renli | 201 | renli | | 3 | mili | female | 19 | 202 | xiaoshou | 202 | xiaoshou | +----+------+--------+------+--------+----------+------+----------+ # --------------> # 1 带IN关键字的子查询 #查询平均年龄在25岁以上的部门名 【分析】首先 确定要什么结果--id,部门名 ,从哪张表可以得到目标结果-- dep delect id,name from dep 筛选条件? 平均年龄在25岁以上--能和部门表关联的,是emp表的dep_id 因此通过筛选 id 获得目标结果 select dep_id from emp group by dep_id having avg(age)>25 mysql> select id,name from dep where id in (select dep_id from emp group by dep_id having avg(age)>25); +------+-------+ | id | name | +------+-------+ | 200 | jishu | +------+-------+ #查看技术部员工姓名 mysql> select name from emp where dep_id in (select id from dep where name='jishu'); +------+ | name | +------+ | egon | +------+ #查看不足1人的部门名(子查询得到的是有人的部门id),即 要查询出 部门id 不在员工表里的部门 mysql> select name from dep where id not in (select distinct dep_id from emp); +---------+ | name | +---------+ | yunying | +---------+ 【注意】 not in 不支持 null 即 如果子查询里有为null的结果,是查询不到目标结果的。 因此 需要把为 null的记录先剔除-- where dep_id is not null ,再将子查询 作为查询条件 mysql> select name from dep where id not in (select distinct dep_id from emp where dep_id is not null); # --------------> # 2 带 ANY关键字的子查询 -in(子查询语句) -in(值1,值2,值3) -any 后面只能跟子查询语句 -any 必须跟比较运算符配合使用 【栗子】 #在 SQL 中 ANY 和 SOME 是同义词,SOME 的用法和功能和 ANY 一模一样。 # ANY 和 IN 运算符不同之处1 ANY 必须和其他的比较运算符共同使用,而且ANY必须将比较运算符放在 ANY 关键字之前,所比较的值需要匹配子查询中的任意一个值,这也就是 ANY 在英文中所表示的意义 例如:使用 IN 和使用 ANY运算符得到的结果是一致的 select * from employee where salary = any ( select max(salary) from employee group by depart_id); select * from employee where salary in ( select max(salary) from employee group by depart_id); 结论:也就是说“=ANY”等价于 IN 运算符,而“<>ANY”则等价于 NOT IN 运算符 # ANY和 IN 运算符不同之处2 ANY 运算符不能与固定的集合相匹配,比如下面的 SQL 语句是错误的 SELECT * FROM T_Book WHERE FYearPublished < ANY (2001, 2003, 2005) # --------------> # 3 带ALL关键字的子查询 # all同any类似,只不过all表示的是所有,any表示任一 # 查询出那些薪资比所有部门的平均薪资都高的员工=》薪资在所有部门平均线以上的狗币资本家 select * from employee where salary > all ( select avg(salary) from employee group by depart_id); # 查询出那些薪资比所有部门的平均薪资都低的员工=》薪资在所有部门平均线以下的无产阶级劳苦大众 select * from employee where salary < all ( select avg(salary) from employee group by depart_id); # 查询出那些薪资比任意一个部门的平均薪资低的员工=》薪资在任一部门平均线以下的员工select * from employee where salary < any ( select avg(salary) from employee group by depart_id); # 查询出那些薪资比任意一个部门的平均薪资高的员工=》薪资在任一部门平均线以上的员工 select * from employee where salary > any ( select avg(salary) from employee group by depart_id); # --------------> # 4 带比较运算符的子查询 #比较运算符:=、!=、>、>=、<、<=、<> #查询大于所有人平均年龄的员工名与年龄 mysql> select name,age from emp where age>(select avg(age) from emp); +------+------+ | name | age | +------+------+ | egon | 48 | +------+------+ #查询大于部门内平均年龄的员工名、年龄 mysql> select t1.name,t1.age from emp t1 inner join (select dep_id,avg(age) avg_age from emp group by dep_id) t2 on t1.dep_id=t2.dep_id where t1.age>t2.avg_age; Empty set (0.15 sec) # --------------> # 5 带EXISTS关键字的子查询 EXISTS关字键字表示存在。 在使用EXISTS关键字时,内层查询语句不返回查询的记录。 而是返回一个真假值 True或False—— 当返回True时,外层查询语句将进行查询; 当返回值为False时,外层查询语句不进行查询。 #department表中存在dept_id=203,Ture mysql> select * from emp where exists (select id from dep where id=203); +----+------+--------+------+--------+ | id | name | sex | age | dep_id | +----+------+--------+------+--------+ | 1 | egon | male | 48 | 200 | | 2 | cc | male | 18 | 201 | | 3 | mili | female | 19 | 202 | | 4 | mela | male | 28 | 204 | +----+------+--------+------+--------+ mysql> select * from emp where exists (select id from dep where id=200); +----+------+--------+------+--------+ | id | name | sex | age | dep_id | +----+------+--------+------+--------+ | 1 | egon | male | 48 | 200 | | 2 | cc | male | 18 | 201 | | 3 | mili | female | 19 | 202 | | 4 | mela | male | 28 | 204 | +----+------+--------+------+--------+ #department表中存在dept_id=205,False mysql> select * from emp where exists (select id from dep where id=205); Empty set (0.00 sec) mysql> select * from emp where exists (select id from dep where id=204); Empty set (0.00 sec) # --------------- # 5.1 in与exists 区别: in 先查完子查询的结果,然后外查询再与子查询结果进行匹配 exists 每次查询 都是外查询一次,走一次子查询,最后得出一个结果;每次查询都是这样循环。 # (1) exists exists后面一般都是子查询,后面的子查询被称做相关子查询(即与主语句相关), 当子查询返回行数时,exists条件返回true, 否则返回false,exists是不返回列表的值的, exists只在乎括号里的数据能不能查找出来,是否存在这样的记录。 # 例 查询出那些班级里有学生的班级 select * from class where exists (select * from stu where stu.cid=class.id) # exists的执行原理为: 1、依次执行外部查询:即select * from class 2、然后为外部查询返回的每一行分别执行一次子查询:即(select * from stu where stu.cid=class.cid) 3、子查询如果返回行,则exists条件成立,条件成立则输出外部查询取出的那条记录 # (2)in in后跟的都是子查询,in()后面的子查询 是返回结果集的 # 例 查询和所有女生年龄相同的男生 select * from stu where sex='男' and age in(select age from stu where sex='女') # in的执行原理为: in()的执行次序和exists()不一样,in()的子查询会先产生结果集, 然后主查询再去结果集里去找符合要求的字段列表去.符合要求的输出,反之则不输出. 【总结】 in 的效率比 exists 的高 # 5.2 not exists / not in (1)not exists: 如果主查询表中记录少,子查询表中记录多,并有索引。 例如:查询那些班级中没有学生的班级 select * from class where not exists (select * from student where student.cid = class.cid) not exists的执行顺序是: 在表中查询,是根据索引查询的,如果存在就返回true,如果不存在就返回false,不会每条记录都去查询。 (2) not in ()子查询的执行顺序是: 为了证明not in成立,即找不到,需要一条一条地查询表,符合要求才返回子查询的结果集, 不符合的 就继续查询下一条记录,直到把表中的记录查询完,只能查询全部记录才能证明,并没有用到索引。 【总结】not exists 的效率比 not in 的高 # 【综合栗子1】 # ----数据准备 create database db13; use db13 create table student( id int primary key auto_increment, name varchar(16) ); create table course( id int primary key auto_increment, name varchar(16), comment varchar(20) ); create table student2course( id int primary key auto_increment, sid int, cid int, foreign key(sid) references student(id), foreign key(cid) references course(id) ); insert into student(name) values ("egon"), ("lili"), ("jack"), ("tom"); insert into course(name,comment) values ("数据库","数据仓库"), ("数学","根本学不会"), ("英语","鸟语花香"); insert into student2course(sid,cid) values (1,1), (1,2), (1,3), (2,1), (2,2), (3,2); # ---查询 # 1、查询选修了所有课程的学生id、name:(即该学生根本就不存在一门他没有选的课程。) select * from student s where not exists (select * from course c where not exists (select * from student2course sc where sc.sid=s.id and sc.cid=c.id)); 【分析】 明确三层筛选的结果,以及每层之间的逻辑关系(循环关系以及真假关系) 第一层-学生 not exists 第二层-课程 not exists 第三层-选课 三层的循环关系:(学生 1,2,3,4 课程 1,2,3 ) for sid in [1,2,3,4]: for cid in [1,2,3]: (sid,cid) 最外层循环第一次 # (1,1) # (1,2) # (1,3) 最外层循环第二次 # (2,1) # (2,2) # (2,3) 最外层循环第三次 # (3,1) # (3,2) # (3,3) 最外层循环第四次 # (4,1) # (4,2) # (4,3) 以第一次循环为例,第一个学生 id=1 与 第一门课程 id=1 配对,形成 选课(1,1), 语句1 ----select * from student s where not exists 语句2 ---- (select * from course c where not exists 语句3 ---- (select * from student2course sc where sc.sid=s.id and sc.cid=c.id)); (select * from student2course sc where sc.sid=s.id and sc.cid=c.id) 的结果里,有选课对应关系(1,1), 因此 语句3 的结果为True;再到语句2--not exsits ,取反之后结果为假,因此语句2的最后结果为假; 最后到了最外层的判断,语句1 --not exsits, 里面的语句2 的最后结果为假,语句3取反之后 结果为真, 因此输出语句1的选择结果--select * from student ,得到的id=1的学生,是符合要求的,即选修了所有课的学生。 # ==》其实有种傻瓜式的‘翻译方法’ 查询选修了所有课程的学生id、name:(即该学生根本就不存在一门他没有选的课程。) 切割-主语(查询目标)和 定语(查询条件) 目标1-学生--》select * from student s 不存在一门课程--》where not exists 目标2-课程--》select * from course c 他没有选的课程--》where not exists(select * from student2course sc where sc.sid=s.id and sc.cid=c.id) # 即 不在选课列表里 # ------- 方法2 -- 链表的方式 select s.name from student as s inner join student2course as sc on s.id=sc.sid group by s.name # 按照学生分组 having count(sc.id) = (select count(id) from course); # 分组后,统计每个学生的选课门数,并筛选出 选课表的课程种数 和 课程表里的课程种数 相等的 # 2、查询没有选择所有课程的学生,即没有全选的学生。(存在这样的一个学生,他至少有一门课没有选(即 有一门课,在选课表里没有对应关系)) select * from student s where exists (select * from course c where not exists (select * from student2course sc where sc.sid=s.id and sc.cid=c.id)); # 3、查询一门课也没有选的学生。(不存在这样的一个学生---》至少选修一门课程的学生) select * from student s where not exists (select * from course c where exists (select * from student2course sc where sc.sid=s.id and sc.cid=c.id)); # 4、查询至少选修了一门课程的学生。(存在至少选修了一门课的学生) select * from student s where exists (select * from course c where exists (select * from student2course sc where sc.sid=s.id and sc.cid=c.id)); # ----------------- # 【综合栗子2】 # ----数据准备 company.employee 员工id id int 姓名 emp_name varchar 性别 sex enum 年龄 age int 入职日期 hire_date date 岗位 post varchar 职位描述 post_comment varchar 薪水 salary double 办公室 office int 部门编号 depart_id int #创建表 create table employee( id int not null unique auto_increment, name varchar(20) not null, sex enum('male','female') not null default 'male', #大部分是男的 age int(3) unsigned not null default 28, hire_date date not null, post varchar(50), post_comment varchar(100), salary double(15,2), office int, #一个部门一个屋子 depart_id int ); #查看表结构 mysql> desc employee; +--------------+-----------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------------+-----------------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | varchar(20) | NO | | NULL | | | sex | enum('male','female') | NO | | male | | | age | int(3) unsigned | NO | | 28 | | | hire_date | date | NO | | NULL | | | post | varchar(50) | YES | | NULL | | | post_comment | varchar(100) | YES | | NULL | | | salary | double(15,2) | YES | | NULL | | | office | int(11) | YES | | NULL | | | depart_id | int(11) | YES | | NULL | | +--------------+-----------------------+------+-----+---------+----------------+ #插入记录 #三个部门:教学,销售,运营 insert into employee(name,sex,age,hire_date,post,salary,office,depart_id) values ('egon','male',18,'20170301','老男孩驻沙河办事处外交大使',7300.33,401,1), #以下是教学部 ('alex','male',78,'20150302','teacher',1000000.31,401,1), ('wupeiqi','male',81,'20130305','teacher',8300,401,1), ('yuanhao','male',73,'20140701','teacher',3500,401,1), ('liwenzhou','male',28,'20121101','teacher',2100,401,1), ('jingliyang','female',18,'20110211','teacher',9000,401,1), ('jinxin','male',18,'19000301','teacher',30000,401,1), ('成龙','male',48,'20101111','teacher',10000,401,1), ('歪歪','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门 ('丫丫','female',38,'20101101','sale',2000.35,402,2), ('丁丁','female',18,'20110312','sale',1000.37,402,2), ('星星','female',18,'20160513','sale',3000.29,402,2), ('格格','female',28,'20170127','sale',4000.33,402,2), ('张野','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门 ('程咬金','male',18,'19970312','operation',20000,403,3), ('程咬银','female',18,'20130311','operation',19000,403,3), ('程咬铜','male',18,'20150411','operation',18000,403,3), ('程咬铁','female',18,'20140512','operation',17000,403,3) ; #ps:如果在windows系统中,插入中文字符,select的结果为空白,可以将所有字符编码统一设置成gbk # ----查询应用 # 查询每个部门最新入职的那位员工 # 方法一 链表方式 select * from emp as t1 inner join (select post,max(hire_date) max_date from emp group by post) as t2 on t1.post=t2.post where t1.hire_date = t2.max_date # 方法二 子查询 select t3.name,t3.post,t3.hire_date from emp as t3 where id in (select (select id from emp as t2 where t2.post=t1.post order by hire_date desc limit 1) from emp as t1 group by post);
【补充】
null--查找数据表中 数据列是否为 NULL,必须使用 IS NULL 和 IS NOT NULL
我们已经知道 MySQL 使用 SQL SELECT 命令及 WHERE 子句来读取数据表中的数据,但是当提供的查询条件字段为 NULL 时,该命令可能就无法正常工作。 为了处理这种情况,MySQL提供了三大运算符: IS NULL: 当列的值是 NULL,此运算符返回 true。 IS NOT NULL: 当列的值不为 NULL, 运算符返回 true。 <=>: 比较操作符(不同于 = 运算符),当比较的的两个值相等或者都为 NULL 时返回 true。 关于 NULL 的条件比较运算是比较特殊的。你不能使用 = NULL 或 != NULL 在列中查找 NULL 值 。 在 MySQL 中,NULL 值与任何其它值的比较(即使是 NULL)永远返回 NULL,即 NULL = NULL 返回 NULL 。 MySQL 中处理 NULL 使用 IS NULL 和 IS NOT NULL 运算符。 注意: select * , columnName1+ifnull(columnName2,0) from tableName; columnName1,columnName2 为 int 型,当 columnName2 中,有值为 null 时,columnName1+columnName2=null, ifnull(columnName2,0) 把 columnName2 中 null 值转为 0。
参考:
https://www.cnblogs.com/linhaifeng/articles/7267592.html
https://www.cnblogs.com/linhaifeng/articles/7267596.html
🐱不负韶华,只争朝夕🍚

 浙公网安备 33010602011771号
浙公网安备 33010602011771号