ES散记
安装介绍
目录结构

配置的建议
Xms和Xms设置成一样
Xmx不要超过机器内存的50%
不要超过30GB- https://www.elastic.co/blog/a-heap-of-trouble
config/jvm/options
7.1 默认1GB
插件
bin/elasticsearch-plugin list 查看已安装哪些插件
bin/elasticsearch-plugin install analysis-icu 安装
get /_cat/plugins
kibana
bin/kibane-plugin install plugin_location
bin/kibana-plugin list
bin/kibana remove
多实例运行
bin/elasticsearch-E node.name=node1 -E cluster.name-geektime -E path.data=node1_data -d
bin/elasticsearch-E node.name=node2 -E cluster.name=geektime -E path.data=node2_data -d
bin/elasticsearch-E node.name=node3 -E cluster.name=geektime -E path.data=node3_data -d
删除进程ps grep I elasticsearch/kill pid
/_cat/nodes
基本概念
mapping
setting
- Index-索引是文档的容器,是一类文档的结合
- Index体现了逻辑空间的概念:每个索引都有自己的Mapping定义,用于定义包含的文档的字段名和字段类型
- Shard体现了物理空间的概念:索引中的数据分散在Shard上
- 索引的Mapping与Settings
- Mappirng定义文档字段的类型
- Setting定义不同的数据分布 //定义分片数等
index
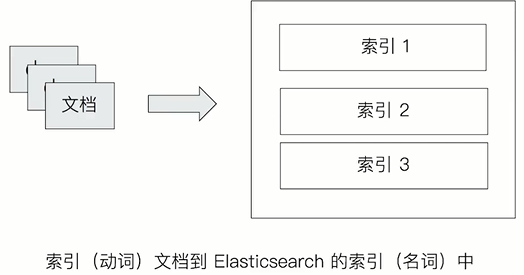
名词:一个Elasticsearch集群中,可以创建很多个不同的索引
动词:保存一个文档到Elasticsearch的过程也叫索引(indexing)。
ES中,创建一个倒排索引的过程
名词:一个B树索引,一个倒排索引
与数据库的类比

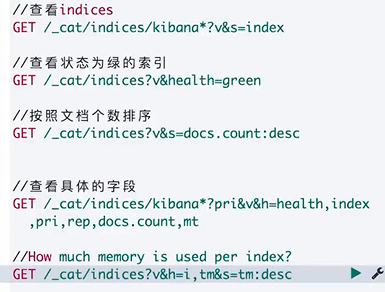
其他查看操作
分布式系统的可用性与扩展性
- 高可用性
- 服务可用性-允许有节点停止服务o数据可用性-部分节点丢失,不会丢失数据
- 可扩展性
- 请求量提升/数据的不断增长(将数据分布到所有节点上)
节点、集群
分布式架构的好处
- 存储的水平扩容
- 提高系统的可用性,部分节点停止服务,整个集群的服务不受影响
ES 集群分布式架构 - 不同的集群通过不同的名字来区分,默认名字“elasticsearch”
- 通过配置文件修改,或者在命令行中
-E cluster.name=geektime进行设定 - 一个集群可以有一个或者多个节点
节点
节点是一个Elasticsearch的实例
本质上就是一个JAVA进程
一台机器上可以运行多个Elasticsearch 进程,但是生产环境一般建议一台机器上只运行一个Elasticsearch实例
每一个节点都有名字,通过配置文件配置,或者启动时候-E node.name=node1指定
每一个节点在启动之后,会分配一个UID,保存在data目录下
Master-eligible nodes和Master Node
eligible 合格者;适任者;有资格者
- 每个节点启动后,默认就是一个Master eligible节点
- 可以设置node.master:false禁止
- Master-eligible节点可以参加选主流程,成为Master 节点
- 当第一个节点启动时候,它会将自己选举成Master节点
- 每个节点上都保存了集群的状态,只有Master节点才能修改集群的状态信息
- 集群状态(Cluster State),维护了一个集群中,必要的信息
- 所有的节点信息
- 所有的索引和其相关的Mapping与Setting 信息分片的路由信息
- 任意节点都能修改信息会导致数据的不一致性
GET /_cluster/health
GET /_cat/nodes
查看集群状态
Green-主分片与副本都正常分配
Yellow-主分片全部正常分配,有副本分片未能正常分配
Red-有主分片未能分配
- 例如,当服务器的磁盘容量超过85%时,去创建了一个新的索引
Data Node & Coordinating Node
Data Node :
可以保存数据的节点,叫做 Data Node。负责保存分片数据。在数据扩展上起到了至关重要的作用
Coordinating Node:
- 负责接受Client的请求,将请求分发到合适的节点,最终把结果汇集到一起
- 每个节点默认都起到了Coordinating Node的职责
Hot & Warm Node
Machine Learning Node
Tribe Node(5.3开始使用Cross Cluster Serarch)
配置节点类型

分片
主分片
- 每个分片就是一个lucene实例
- 主分片数在索引创建时指定,后续不允许修改,除非Reindex
副本分片
- 解决数据高可用
- 副本分片数,可以动态调整
- 增加副本数,还可以在一定程度上提高服务的可用性(读取的吞吐)
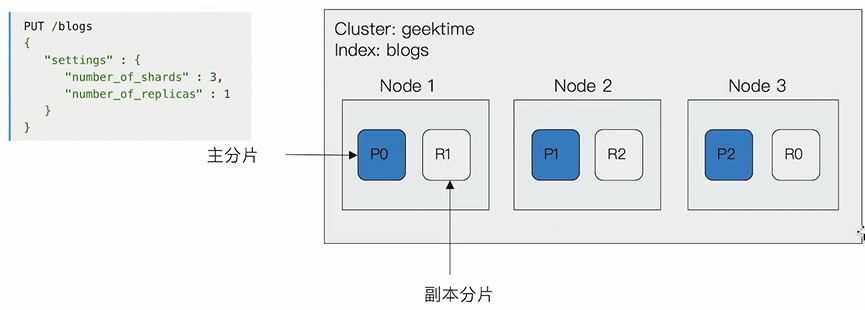
分片设定
对于生产环境中分片的设定,需要提前做好容量规划
- 分片数设置过小
- 导致后续无法增加节点实现水平扩展
- 单个分片的数据量太大,导致数据重新分配耗时
- 分片数设置过大,7.0开始,默认主分片设置成1,解决了over-sharding的问题 over-sharding??
- 影响搜索结果的相关性打分,影响统计结果的准确性
- 单个节点上过多的分片,会导致资源浪费,同时也会影响性能
文档操作
//可指定也可以不指定,已经存在的id会报错
PUT index/_create/1
POST index/_doc
{}
GET index/_doc/id
POST index/_update/id
{
"doc":{ "name" : "TOM" }
}
Update方法不会删除原来的文档,而是实现真正的数据更新. Post方法/Payload需要包含在"doc"中
Bulk
支持在一次API调用中,对不同的索引进行操作
支持四种类型操作
Index、Create、Update、Delete
可以在URI中指定Index,也可以在请求的Payload中进行
操作中单条操作失败,并不会影响其他操作
返回结果包括了每一条操作执行的结果
批量读取mget

msearch
倒排索引
单词词典
记录所有文档的单词,单词与倒排列表的关联关系
单词词典一般比较大,可以通过B+树或哈希拉链法实现,以满足高性能的插入与查询
倒排列表
记录了单词对应的文档结合,由倒排索引项组成
- 倒排索引项
文档ID
词频TF-该单词在文档中出现的次数,用于相关性评分
位置(Position)-单词在文档中分词的位置。用于语句搜索(phrase query)
偏移(Offset)-记录单词的开始结束位置,实现高亮显示
Elasticsearch的JSON文档中的每个字段,都有自己的倒排索引
可以指定对某些字段不做索引
优点:节省存储空间
缺点:字段无法被搜索
分词
Analysis-文本分析是把全文本转换一系列单词(term/token)的过程,也叫分词
Analysis是通过Analyzer来实现的
- 可使用Elasticsearch内置的分析器/或者按需定制化分析器
analyerd组成
Character Filters(针对原始文本处理,例如去除html)
Tokenizer(按照规则切分为单词)
Token Filter(将切分的的单词进行加工,小写,删除stopwords,增加同义词)
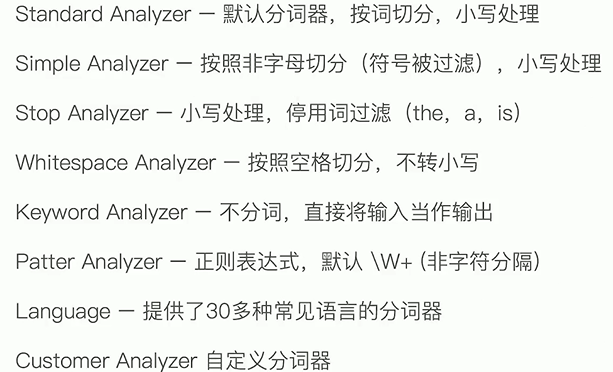
内置分词器:
_analyer API
3种测试方式
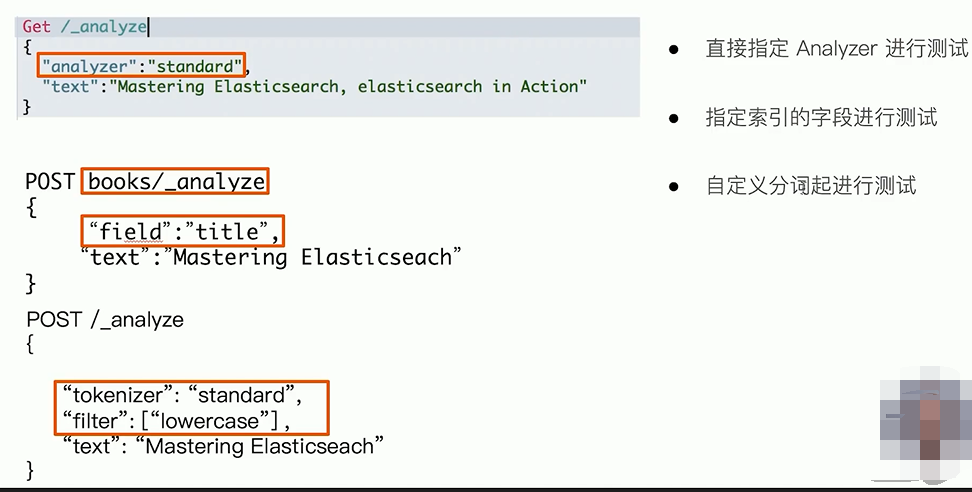
中文分词
聚合
基本聚合操作
对text进行terms,需要打开fielddata。
Keyword默认支持fielddata
Text需要在Mapping 中enable。会按照分词后的结果进行.
{}


如果对text类型 field 进行统计,使用 field.keyword
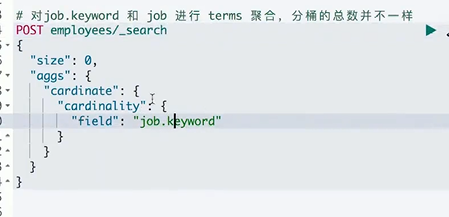
cardinality 去重统计


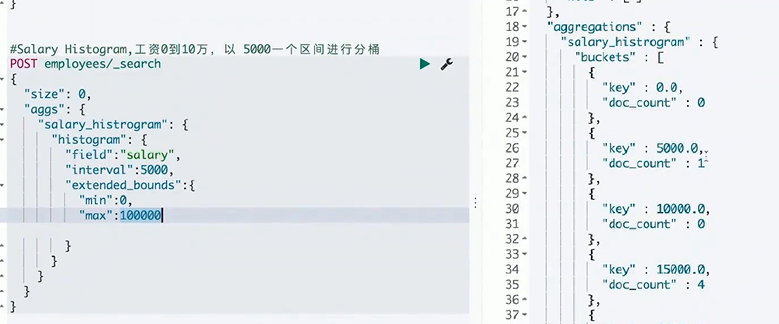
Range&histrogram分桶
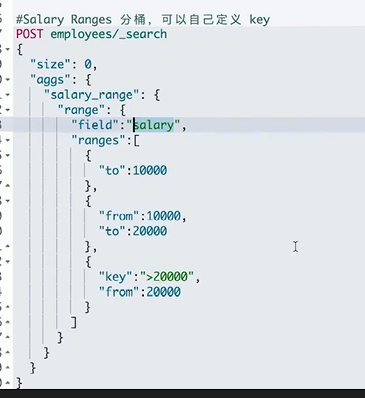
可以指定key获取
pipeline
管道的概念:支持对聚合分析的结果,再次进行聚合分析
指定路径 >


也支持status_bucket等
聚合的作用范围
query
filter
post field
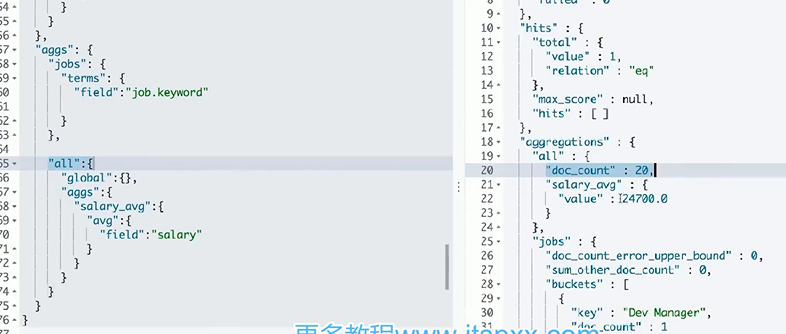
global
filter:
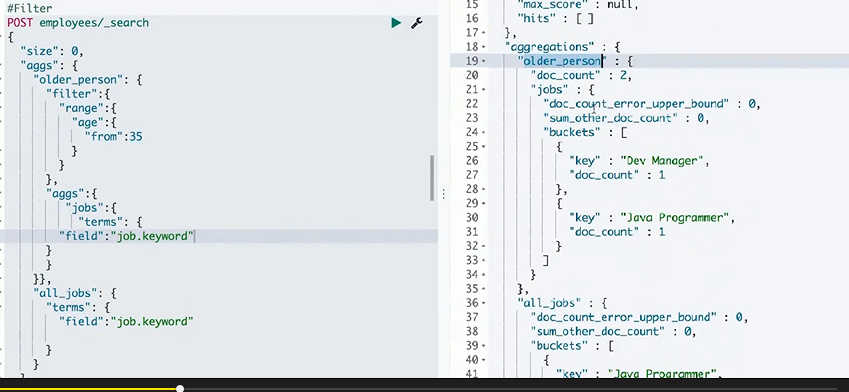
post_filter
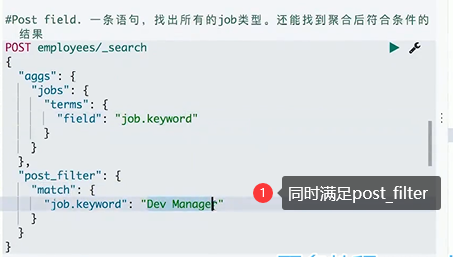
globa,忽略query的作用范围
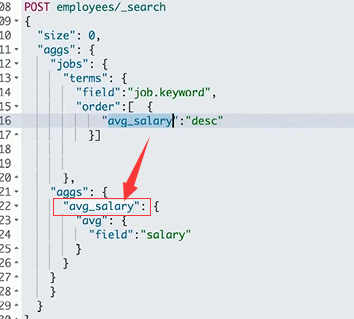
排序
- 默认按count降序
- 指定size,返回对应同
- 自定义order,按count和key排序
![]()
可指定其他agg
![]()
![]()


并发控制
3种方式


自动补全与上下文提示

1.定义mapping时使用 type "completion"
2.索引数据
3.运行“suggest”查询,得到搜索建议
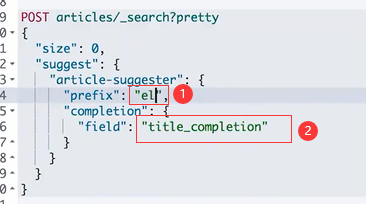
Context Suggest

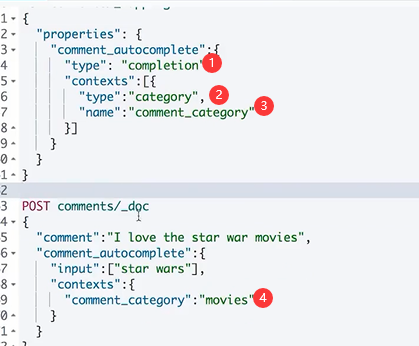
精准度和召回率


 浙公网安备 33010602011771号
浙公网安备 33010602011771号