
浅谈深度学习的落地问题
前言
深度学习不不仅仅是理论创新,更重要的是应用于工程实际。
关于深度学习人工智能落地,已经有有很多的解决方案,不论是电脑端、手机端还是嵌入式端,将已经训练好的神经网络权重在各个平台跑起来,应用起来才是最实在的。
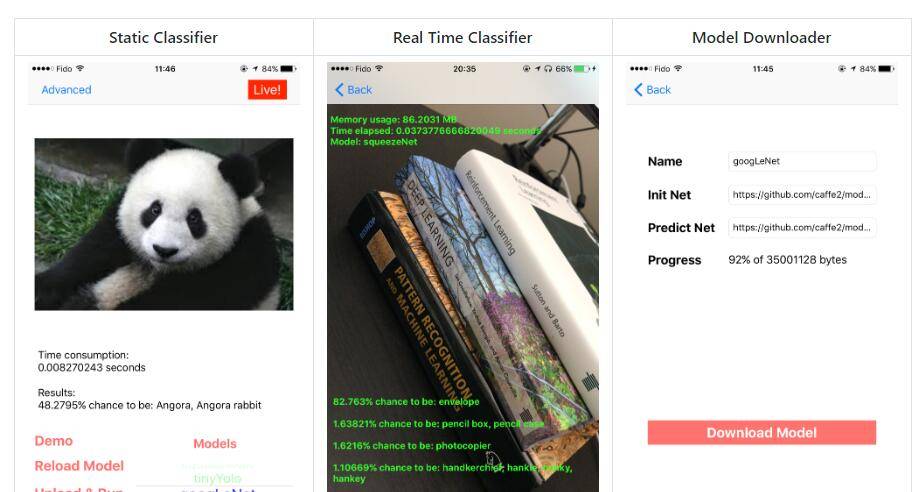
(caffe2-ios:https://github.com/KleinYuan/Caffe2-iOS)
这里简单谈谈就在2018年我们一般深度学习落地的近况。
Opencv
Opencv相比大家都比较了解,很流行很火的开源图像处理库,人工智能深度学习大伙,Opencv自然不能落下。早在去年Opencv开始加入Dnn模块,并且一直更新,但是有点需要注意,Opencv的深度学习模块是用来inference推断而不是用来训练的。
为什么,因为现在已经存在很多优秀的深度学习框架了(TensorFlow、Pytorch),Opencv只需要管好可以读取训练好的权重模型进行推断就足够了。
(opencv-4.0.0已经发布)
自己试着跑了一下Opencv版的yolov3,利用yolo官方训练好的权重,读取权重并且利用Opencv的前向网络运行——速度还可以,在i5-7400 CPU上推断用了600+ms。

而我用2017版MacBookPro-2.3GHz版本的CPU(i5-7260u)则跑了500ms。要知道这是完全版本的yolo-v3。如果进一步优化的话,在稍微好点的CPU端是可以跑到10fps!
另外在learnopencv相关文章中,也有详尽的评测:
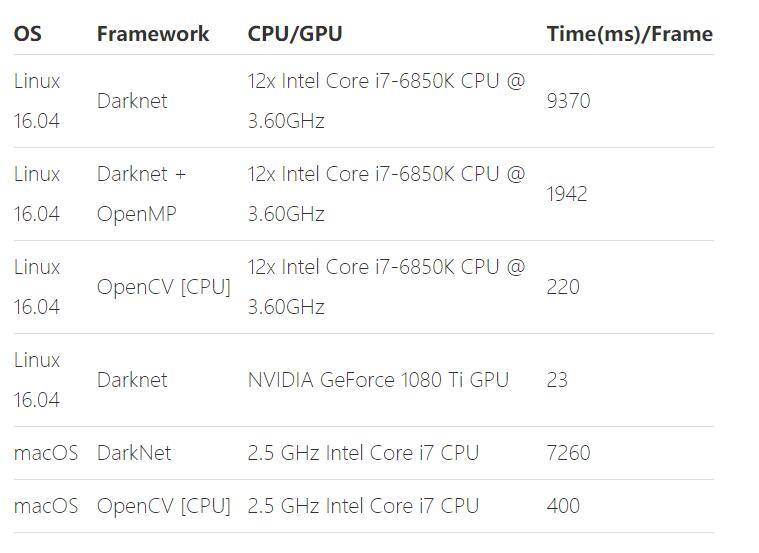
在6核12线程的CPU中可以跑到200ms,速度相当快了,而且优化的空间还是有的。
为什么Opencv版的比Darknet版的速度快那么多,是因为Opencv的Cpu端的op编写过程中利用了CPU-MKL等很多优化库,针对英特尔有着很好的优化,充分利用了多线程的优势(多线程很重要,并行计算比串行计算快很多)。
当然这些优化还不是尽头,Opencv也在一直更新:
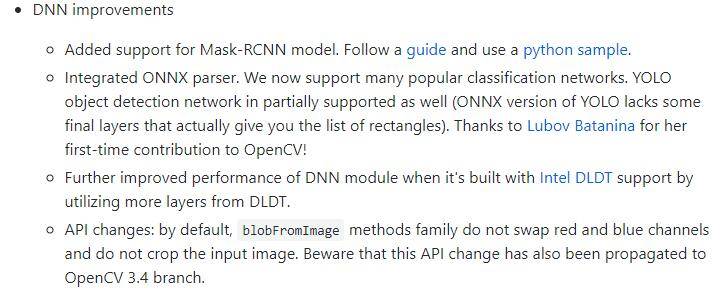
Opencv可以作为一个不错的落地的深度学习推断平台,只要安装好Opencv,就可以跑深度学习代码了,不需要安装其他深度学习框架了。但是有点需要注意,Opencv最好的实践是CPU端,GPU端Opencv对cuda的支持不是很好,Opencv只有利用OpenCL支持GPU,但速度没有cuda库快。
Pytorch-v1.0
Pytorch-v1.0的预览版已经发布了,正式版应该是在国庆节的第一天发布。

但我们在观察Pytorch的1.0文档中已经可以熟知,为什么Pytorch-v1.0称为从研究到生产:

最重要的三点:
- 分布式应用
- ONNX的完全支持
- 利用C++部署生成环境
简单谈谈第三个要点,看了官方的说明文档,Pytorch也做了类似于Opencv工作,新的Pytorch支持直接应用Pytorch的C++部分从而编译可以单独执行Pytorch的推断部分而不需要安装所有Pytorch的组件。
近期会测试一下Pytorh和Opencv相比在Cpu端的速度,看看哪个对CPU端的优化更好些。
IOS、安卓
IOS最大的看点就是:Iphone最新出来的A12仿生处理器!

5W亿次每秒运行速度,跟专业显卡比起来可能不算什么,但是在手机端,意思可想而知。
只是不知道具体的速度如何,跑Yolo的话可不可以实时,期待之后的测评吧。

不过在HomeCourt这款APP中(中国目前还不可以使用),凭借A12强大的性能,貌似可以实时追踪人体骨架。还是很值得期待的。
至于安卓端,因为华为的芯片还没有具体公布,目前在移动端上的神经网络框架大部分是用CPU跑。
速度快慢就看在arm端的优化如何了。
比较流行的两个框架是ncnn(主要是cpu)和mace(也支持Gpu)。都在发展阶段,前者出世1年左右,后者出世半年不到。
也期待一下吧!
后记
深度学习落地,最繁琐的莫过于配置各种环境,希望之后各大深度学习框架能够在落地这块加大投入,实现快速方便地部署吧!
配一张Openpose的配置信息:

(OpenPose中对Windows的要求较为苛刻)
撩我吧
- 如果你与我志同道合于此,老潘很愿意与你交流;
- 如果你喜欢老潘的内容,欢迎关注和支持。
- 如果你喜欢我的文章,希望点赞👍 收藏 📁 评论 💬 三连一下~
想知道老潘是如何学习踩坑的,想与我交流问题~请关注公众号「oldpan博客」。
老潘也会整理一些自己的私藏,希望能帮助到大家,点击神秘传送门获取。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号