思考:2021年还可以入门深度学习吗?
前言
过年时闲来无事,瞎翻自己的博客,偶然看到之前写的一篇文章:
这篇文章原先发布于2018年中旬,那会正是深度学习、神经网络无脑火热的时候。火热到什么程度?火热到显卡一度卖脱销(不是因为挖矿),研究生导师集体推荐学生转深度学习方向、毕业论文不带“深度学习”四个字都毕不了业、大街上随便拉个学生问都认识吴恩达。
就这个火的程度,我那会也毅然决然地踏入了深度学习的大军,开始追星(吴恩达、李宏毅),开始上课(CS231n、CS229),开始学习框架(Pytorch、Tensorflow),开始水论文(逃~)。

不过转眼两年多过去2021年了,现在怎么样了呢?2018年那会知乎热搜已经是“算法岗神仙打架”,2019年是“诸神黄昏”,2020年是“灰飞烟灭”,2021不知道又是啥我也很好奇。不过显而易见的是,大家对人工智能岗位已经抱有谨慎态度,尤其是CV岗。
其实这个现象的原因是,CV在现在处于门槛低,找工作人多,职业少的一个尴尬的位置,一边是大量的学生涌入,一边是不景气的经济环境和日益饱满的就业岗位。自然而然导致相关岗位就业难度达到18层地狱级别。
不过这可不是代表深度学习的浪潮已经过了,只不过大家对深度学习没有之前那么盲目罢了。
最花里胡哨的阶段过去了,漫天吹牛的阶段过去了,现在这个时代,深度学习已经成为了基础设施,逐渐渗透进了各个我们平时所在的行业和领域。例如人脸识别已经基本成熟(现在车站基本都通过人脸识别去实现身份证和人脸的核验)、语音识别OCR识别技术也都在应用。
这就是智能化,自动化的浪潮。难的不是CV内卷,难的是如何不错过这个时代(文末有福利)。
一篇文章解决机器学习,深度学习入门疑惑
以下正文写于2018年,2021年2月15号进行了修改。
话不多说,看则新闻,人工智能已经被国家所认可:

由此可见国家对人工智能的重视程序,趁早学习,让我们也贡献一份力量。
这篇文章要说的东西
研究生期间,和之前的几个学长以及几个学弟偶尔也聊聊天。大部分聊的话题无关乎这几年大火的机器学习深度学习神经网络,而这篇文章的目的,则是从学生的角度(不管是研究生还是即将步入研究生的本科生)来看待这个大方向和大趋势,也是为了替那些刚入门或者准备入门机器学习、深度学习、计算机视觉、图像处理、语音识别及处理等等等相关方向的童鞋,或者研一童鞋学习相关方向迷茫者了清一些基本的概念,以及解决这些“名词”代表什么,应该怎么选择,怎么入门的问题,毕竟谁当年也迷茫过,多一些传承,就少走一些弯路。
涉及到的专业
多了去了,现在什么专业只要和算法沾点关系,差不多都可以搞机器学习深度学习神经网络,举几个比较常见的专业:机器学习、深度学习、图像处理、计算机视觉、大数据处理、信息检索、智能系统、数据挖掘、并行计算、图形图像处理、大数据处理与可视化分析…
案头的两本书,经典的西瓜书和深度学习圣经。

涉及到的相关应用
机器学习和深度学习方面的应用太多,什么图像分割,语言识别,超分辨率,图像跟踪,图像生成等等等等,具体到每个小的领域都有相关方面的应用,在这里简单随便介绍两个使用场景。
- 机器学习:比如淘宝推荐,有那么一两天心血来找突然想买一个游戏机。你打开手机淘宝App后点击搜索,输入某款游戏机的名字(例如:switch),查看一些卖游戏机的店的信息。这个时候淘宝就已经在记录你的信息了,不管你点开哪个店主的网店,淘宝都会收集你的偏好,淘宝会记录你点开的每一个链接,每一个链接的内容都给你记录下来。当你下一次登录淘宝App的时候,淘宝就会根据在你这边收集的信息和机器学习算法来分析你的爱好和特点进而给你推送一些比较适合你的,你可能喜欢的物品。
- 深度学习:再比如之前很火的换脸项目-DeepFake:
通过变分自编码器提取一张图片的特征信息,再根据另一张图片的特征信息还原出来
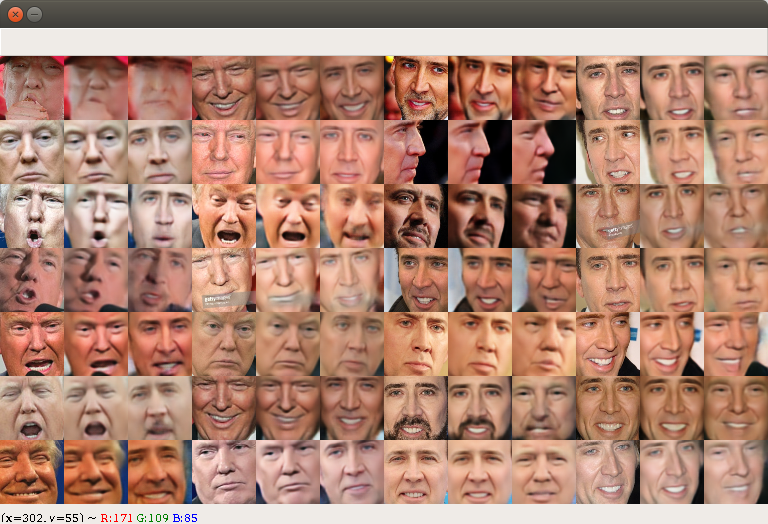
上面每三个图中,最左边是川普的脸,而最右边则是尼古拉的脸,通过自编码器提取特征进行生成。通过这个甚至可以对视频进行以假乱真,这是个深度学习的应用,对这个项目有兴趣的可以看其相关文章。
正文
首先声明,正文部分可能没有你们想象的那么多,这篇文章并不妄想将所有的机器学习和深度学习的知识概括并整理出来,没有什么意义。因为,一是机器学习涉及到的公式算法很多很多,写那么多公式对初学者并不友好,本来是入门很简单的一件事情没有必要复杂化,二是这篇文章的定位不是机器学习也不是深度学习教材,当然也不是科普文,这篇文章是以大学生的角度来谈一谈这个话题,把我的一些经验跟大家分享分享。
开始说正事,不论你之前干什么学什么,在什么专业什么领域,不用担心。有一些编程基础(C/C++),还有一些数学的基本知识(高数、线性代数、概率统计)就可以了,另外,机器学习主要使用的语言是python。python(派森),想必大家不管熟悉不熟悉总归是听说过,对,这个语言很火,很强大,很牛逼,无所不能,机器学习和python有着很紧密的联系。很多的深度学习库都是使用python语言进行编程的,所以学习这门语言也是有必要的。
机器学习
首先说明机器学习和深度学习的关系:深度学习是机器学习的子集,深度学习是机器学习中的一个领域,一小块部分,想要了解深度学习,首先要了解机器学习。
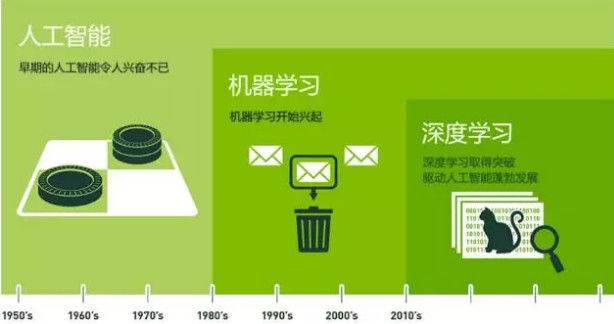
通过上面这张图可以看出人工智能、机器学习和深度学习的关系,人工智能的范围很广,当然不止包括机器学习,而深度学习只是机器学习的一个比较重要的子集。刚开始看很容易搞混,虽然理论上深度学习属于机器学习的一部分,但机器学习和深度学习主要定位目标还是可以区分出来的,机器学习主要是对文本数据进行处理(表格中的数据),而深度学习则主要对图像和语音这些方面进行处理。
关于机器学习的历史,这里不多说,网上一抓一大把,自行查阅即可。也以看看机器学习西瓜书(就是上文图片中摆出的)上面对机器学习历史的介绍。
那到底什么是机器学习,本质上就是利用一些数学算法来解决实际问题。并且这些数学算法我们都学过一些。做过数学建模的同学们或多或少接触过机器学习的知识,当你使用matlab在对一个函数进行线性拟合的时候,你已经在用机器学习了。
机器学习的一般过程大致分为:
- 获取你需要的数据(获取数据,整理数据,数据增强)
- 对数据进行分析(数据预处理)
- 使用相应的算法,对数据进行处理(机器学习算法)
- 然后得出结果的过程。(输出结果)
直白点,假如我们把算法想象成一个简单的函数(这个函数就是你设计的算法): y = x + 2。x就是输入也就是数据,y就是输出也就是你要得到的结果,x + 2这个过程就是你算法的过程。
简单吧,再来个稍微复杂点的函数: 5 = w*x + 4。
这个函数不是方程吗?对,这是个方程,如果我们得到了x的值,相应地我们就可以求出w。但我们现在不以方程的角度去想他,让我们以机器学习的角度去想它。
假设,上面那个函数我们现在不能一眼看出结果。上面的函数是我们设计的一个机器学习算法,使这个算法通过输入我们给的数据x然后得到一个结果(假设我们要得到的结果是5),于是,上面这个机器学习算法(函数)是我们自己设计的,我们想要通过输入x来得到输出5。
于是我们设计了: 5 = w*x + 4。
然后怎么办呢,机器学习,就是机器进行学习的过程。在机器学习中,我们想要我们设计的这个算法能够逐渐学习如何去得到最终结果,这个过程就是通过训练来得到的。
训练肯定和实战是不一样的,一般在我们机器学习的过程中,我们数据集分为两个部分,训练集和测试集,相当于练习和实战了。当然训练这个过程是针对有监督学习的,什么是有监督学习,简单来说就是有label,有标记。比如给你一张图,上面画有一只猫,这张图对应的标记就是1,如果这张图上面是一条狗,那么这张图对应的标记是2,我们让机器学习去判断一系列上面有猫和狗的图片,在训练过程中我们给予其正确的图和相应标记。可以理解为给一个几岁小孩让它认图,给他猫的图他说1,给他狗的图他说2,如果错了让这个小孩记住狗的特征,下次可能就不会认错了。这种学习过程就是有监督,在学习过程中知道自个儿做出判断是否正确,或者说有人监督你,告诉你哪些你的判断错了。

上面这张图最右面是算法得出的结果,分数最高的一项就是算法判断出最有可能的结果(上面显然判断错了,本来是猫的图,但是猫的得到为负,而狗的得分是437,显然此时的算法错把猫识别成狗了,需要继续“操练”(训练))。
而无监督学习,就不需要标记了,让你凭自己的感觉去判断是否正确,就像给你一堆三角形、圆形、或者长方形的卡片让你将他们摆成三类。你凭借对这些卡片的形状进行区别,从而将这些卡片分为三类。
回到我们之前的问题:5 = w*x + 4。
首先我们不知道w是多少,这里我们把w称之为权重。我们假设这个w是1(这是权重的初始化,而初始化方法也有很多),然后我们要求的输入x是2(这里的输入是固定的,是2也只能是2,2在这里相当于数据,从生活中获得到的数据,比如你往自动售水机投入1个硬币会出来一瓶矿泉水,这里的1就是输入,你投入0.5个或者2个硬币都不会得到矿泉水)。
这样,x是2,w是1,这是我们第一次尝试,我们运行一遍算法,很快我们发现,1*2 + 4 = 6。6不等于5,结果当然错了。
错了就错了吗?为了达到正确的结果,我们要设计一个标准,在这里我们设计一个Loss,以下简称为L,我们令L = y - 5,是我们算法结果和正确结果(这里的正确结果又可以称之为Ground truth)的差。这个Loss就是损失,这个函数就是损失函数,损失函数表明了我们算法得出的结果和实际的结果中有多大的差距,当L为0时,说明我们的算法可以完美地得到我们想要的结果。
但显然这里的L是6-5=1,损失不为0,我们对损失L进行求对权重w的导数,通过链式法则来进行:
dL/dw = dL/dy * dy/dw
很显然可以得到 dL/dw = 1*2(x带入为2)。
于是我们得到了损失对输入的导数,在这里我们再定义一个学习率:r(learning rate)我们设其为:0.1,于是接下来我们得到了关于x的梯度下降公式:
w = w - r * dL/dw
带入具体数字:
w = 1 - 0.1 * 2 = 0.8
此时,权重w为0.8。
回到最开始的公式:w*x + 4 = 0.8 * 2 + 4 = 5.6
虽然5.6依然不等于5,但是相比于之前的结果6来说,稍微接近了,从L中就可以看出来,L = y - 5 = 5.6 - 5 = 0.6,经过一次“学习过程”损失变小了。
看到这里很容易发现,这个学习率如果改成0.2那么岂不损失下降的更快?当然,学习率是超参数(即根据经验来设置的参数),是由我们自行设定的,太高太低都不好,合适即可。
借用cs231n课程中的一张图:
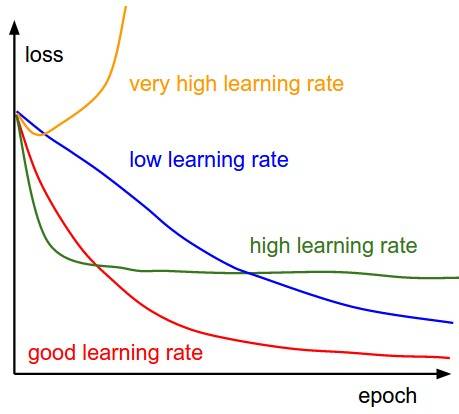
epoch即训练次数,不同的学习率造成的结果是不一样的,合适即可。
这样,我们只训练了一次使损失由1降为0.6,当我们训练多次的时候loss会继续下降,但需要注意,loss并不会“恰好”地降为0,这种情况很少见,我们以后在实验中loss降到一定程度不会发生变化说明已经训练结束了。
机器学习暂且说这么多。
深度学习
深度学习是机器学习的一部分,可以归纳为具有网络层数更深的神经网络。
神经网络的讲解内容网上很多,不再赘述,大家可以看下文的相关资料部分。
相关资料
机器学习和深度学习相关的资料很多,如果想全面列举的话,100页的篇幅都列举不完,在这里我只向初学者推荐一些极具性价比的一些资料。另外,机器学习和深度学习理论上不分家,但是既然要学习有个先后过程是比较好的,我的建议是先对机器学习有全面的认识和实践,然后再来进行深度学习,这样基础将会很扎实。
书籍
- 推荐程序员的数学系列,一共有三本(第一本稍微鸡肋,后两本干货较多),分别是程序员的数学1,线性代数(程序员的数学2)以及概率统计(程序员的数学3),这三本可以有效补充我们所需要的线性代数和概率统计知识。

-
《周志华-机器学习-清华大学出版社》,可以作为案头的参考书,类似于教材,如果一章一章看的话是比较枯燥的。建议有需求的时候看,书中有很多公式和基础知识:https://book.douban.com/subject/26708119/
-
《机器学习实战》,从名字中就可以看出来,这本书主要是将利用python程序来编写机器学习相关算法的,讲解公式比较少,更多的是实战代码:https://book.douban.com/subject/24703171/
-
《深度学习-人名邮电出版社》,同样作为案头的参考书,书中的内容很详实,前几章介绍了深度学习需要的机器学习只是基础,在之后开始讲解深度学习的一系列知识以及公式,基本现在所用的大部分深度学习基础算法上面都有讲,伪代码和公式并存:https://book.douban.com/subject/27087503/
-
李航教授的《统计学习方法》,这本书配合机器学习西瓜书看大概可以覆盖99%的机器学习基础知识,但同样这本书只是讲解一些原理和公式,最好还是结合实战来进行练习。
视频资料
-
吴恩达系列:网上所说吴恩达的课程一般是这两个:一个是Coursera上的machine-learning|Coursera,另一个则是斯坦福大学课程:s229:Maching Learning,这两门课都是对机器学习相关的数学知识进行讲解,前者比后者简单一些,这门课程涉及到的公式较多而工程实践讲解很少,可能看起来比价枯燥但是对于打基础还是很重要的。如果对英文不是很熟悉或者看视频加载慢(视频有时需要FQ),可以考虑看国内的搬运:吴恩达给你的人工智能第一课、网易斯坦福机器学习吴恩达公开课。另外吴恩达最近打算新出一本结合工程实践和数学讲解的一本书,完全免费只需要订阅即可获取,有兴趣的可以看这里。
-
台大李宏毅机器学深度学习课程:http://speech.ee.ntu.edu.tw/~tlkagk/talk.html, 比较出名的中文机器学习课程,讲课很用心,讲解使用的例子也比较生动有趣,讲课幽默诙谐,知识点和兴趣并存,同样推荐。
-
cs231n:斯坦福大学的深度学习课程:http://cs231n.stanford.edu/, 可以说这是全网最好,干货最多的深度学习课程,从最基本的分类算法进行讲解,讲解了神经网络所需要的所有基础知识,也包含了深度学习中几个经典的神经网络架构(VggNet、ResNet)、几个比较出名的深度学习应用,并且对比多个深度学习框架,最重要的是,课后作业很值得做,有一定难度而且可以学到很多重点。总之这门课强烈推荐。
-
优达学城系列,优达学城的课以工程示例优秀著称,每个课程最后包含的工程大都有趣而且适用,例如预测房价、小狗品种分类、生成电影剧本等。课程数量多但是每节很短,每小节都有问题需要回答,也有很多附带知识供你学习,虽然有些知识讲解可能不是很深,但是很适合入门。只是有一点…这些课不是免费的,简单说一下,深度学习课程分两个学期:第一学期3299元,第二学期3999。
关于学习成本
这个是老生常谈的问题,知乎上各路神仙说法纷纭,一千个读者一千个哈姆雷特。我当初也遇到过这样的问题,选择了一段时间,在这里总结一下。
以下是2018年的回答:
如果你的方向是机器学习部分(不涉及神经网络,或者神经网络的层数不是很高的时候)对计算机的要求不是很高,普通笔记本电脑即可。带不带显卡都无所谓。但是如果你主要方向是深度学习,需要处理图像或者视频信息,尤其当你设计的神经网络的层数比较多的时候(层数深即深度学习),显卡的作用就会体现出来,显卡跑深度学习代码是对于显卡的选择建议(前面是型号,后面是显存大小):入门GTX 1060 6g、性价比最高GTX 1070 8g,需要深入研究GTX 1080ti 11g,当然你可以选泰坦显卡(3w+)或者多显卡,总之财富限制想象力。如果电脑上已经有Nvidia的显卡也是可以的,但要看计算能力是否足够(一般capacity大于4.0勉强入门)是否可以使用,在这里查看你的显卡的计算能力(compute capacity)够不够吧:https://developer.nvidia.com/cuda-gpus。
ps:因为挖矿等各种因素等显卡涨价较为厉害,该买还是得买,要将财富转化为生产力。
附一个cpu、gpu测试深度学习运算速度分析:https://github.com/jcjohnson/cnn-benchmarks。
2021年的看法:
最新的30系列我没有用过,暂时不发表评论。20系的显卡我只用过2080ti(半精度推理很好),不过买什么显卡其实重要还是看显存和计算特性(是否支持单精度半精度等),按需购买,可以参考一下我之前写过的一篇文章,还是有参考意义的:
后记
本文发表于2021年新年之际,老潘还是祝大家新年快乐,牛年大吉~
老潘希望我们每个人都能及时找到自己的方向,只有方向正确的时候,努力才会有回报。
分享一波上述提到的部分资源,收集于网络,回复相应code即可:
- 回复“010”获取程序员数学系列
- 回复“011”获取深度学习系列
交流
如果你与我志同道合于此,老潘很愿意与你交流;如果你喜欢老潘的内容,欢迎关注和支持。博客每周更新一篇深度原创文,关注公众号「oldpan博客」不错过最新文章。老潘也会整理一些自己的私藏,希望能帮助到大家,公众号回复"888"获取老潘学习路线资料与文章汇总,还有更多等你挖掘。如果不想错过老潘的最新推文,请点击神秘链接。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号