爬虫入门及实战
绪论
本篇参考《Python爬虫开发:从入门到实践》谢乾坤
本篇只做读书总结,如有侵权,请联系我。

第一章. python基础
易混淆忘记知识点
元组和list的区别
列表生成以后还可以往里面继续添加数据,也可以从里面删除数据;但是元组一旦生成就不能修改。如果它里面只有整数、浮点数、字符串、另一个元组,就既不能添加数据,也不能删除数据,还不能修改里面数据的值。但是如果元组里面包含了一个列表,那么这个元组里面的列表依旧可以变化。
倒叙输出
“步长”取-1,表示倒序输出

元组和字符串不能添加新的内容,不能修改元组里面的非可变容器元素,也不能修改字符串里面的某一个字符。
Key来从字典中读取对应的Value,有3种主要的格式

如果get只有一个参数,那么在找不到Key的情况下会得到“None”;如果get有两个参数,那么在找不到Key的情况下,会返回第2个参数。
**使用字典实现多重条件控制
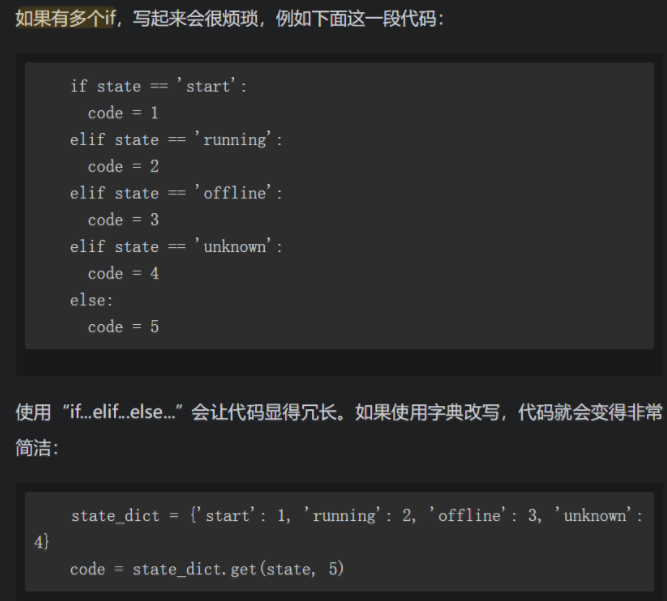
set 和 dict
字典的Key的顺序是乱的,所以不能认为先添加到字典里面的数据就排在前面。
集合里面的元素不能重复。集合也是无序的。
集合最大的应用之一就是去重
由于集合与字典一样,里面的值没有顺序,因此使用集合来去重是有代价的,代价就是原来列表的顺序也会被改变
for循环可以从字符串中获取每个字符
使用is判断
就是当要判断一个变量里面的值是不是None的时候,可以使用“is”这个关键字,也可以使用“”。一般建议使用“is”关键字,因为速度会比“”稍微快一些。
如果你需要永久循环设置time.sleep(1)
遍历字典的几种方法
遍历key
for key in a
for key in a.keys()
遍历value
for value in a.values()
遍历字典项,key value
for key,value in a.items()
for kv in a.items()
第二章.正则表达式
1. 基本符号
- 点号“.”
替除了换行符以外的任何一个字符
eg: kin...me 中间有三个字符 - 星号“*”
0次到无限次循环,就算没有这个字符也可以匹配到,应为0次
eg: 如果快乐你就笑哈*
它前面的字符是一个点号呢?
表示在“如”和“哈”中间出现“任意多个除了换行符以外的任意字符
eg: 如. * 哈
3.问号“?”
问号表示它前面的子表达式0次或1次
eg:笑起来哈?
问号最大的用处是与点号和星号配合起来使用,构成“.* ? ”
4.反斜杠“\”
特殊符号变成普通符号
普通符号变成特殊符号
5.数字“\d”
eg: \d* 匹配若干个数字
6.小括号“()”
小括号可以把括号里面的内容提取出来
eg:密码:12345abcd你的萨芬
匹配: :(.* ?)你 就可以匹配到里面的密码
2.正则
1.findall
import re
# findall(pattern,string,flag)
# 正则 ,原来字符串, 特殊功能标志
# 返回匹配结果的list 没有就返回空列表
包含多个“(.* ? )”怎么返回呢?

2.search
只返回第一个满足要求的字符串,找到就立即停止

- 匹配成果,则是一个正则表达式的对象
- 失败是None
- 获得结果
.group()获得里面的值 group(0)效果一样 group(1)表示正则里第一个括号的内容,group(2)表示正则里第二个括号的内容
- “.* ”和“.* ? ”的区别
①“.* ”:贪婪模式,获取最长的满足条件的字符串。
②“.* ?”:非贪婪模式,获取最短的能满足条件的字符串。
?代表0次或者1次,换句话说就是满足前面一次或者0次即可,而不加?号就是说无限次都可以
3.1.3 正则表达式提取技巧
re.compile() 不用直接使用findall 或者search即可
3.python文件操作
打开文件,创建文件对象两种方式

第二种代码退出缩进就会自动关闭文件
f.readlines() #读取所有行并以列表形式返回
f.read() 文件的全部内容用一个字符串返回
python写文本文件

“w”write直接覆盖进去
“a”add添加进文件的末尾
写文本的两种放进去
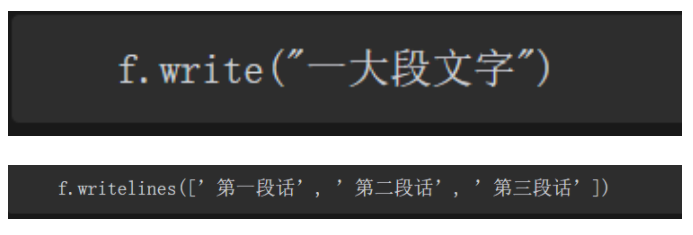
写列表的时候,Python写到文本中的文字是不会自动换行的
案例--半自动爬虫
1.手动的部分是把网页的源代码复制下来,
2.自动的部分是通过正则表达式把其中的有效信息提取出来
第四章网页爬虫开发
- GET方式
request库 自动化获取源代码
import request
source = requests.get('https://www.baidu.com').content.decode()
- POST方式
requests.post("xxx",data).content.decode()
带上data
- 多线程爬虫
python设计时候: Global Interpreter Lock,GIL 全局解释器锁
Python的多线程都是伪多线程,微观单线程,宏观多线程
在I/O密集型影响不大,但是在CPU密集型影响很大,只能使用CPU一个核
所以计算密集型需要使用多进程
爬虫属于I/O密集型
multiprocessing多进程
multiprocessing下面有一个dummy模块,它可以让Python的线程使用multiprocessing的各种方法。
dummy下面有一个Pool类,它用来实现线程池。这个线程池有一个map()方法
所有线程都“同时”执行一个函数
python因为GIL的影响多线程并不能减少运算时间
import multiprocessing.dummy import Pool
pool = pool.map()
pool.map()可以执行一些多线程任务
4.3爬虫搜索算法
1.深度优先搜索 vs 广度优先搜索
有的人喜欢一次只领取一个任务,把这个任务做完,再去领下一个任务,这就叫作深度优先搜索。还有一些人喜欢先把能够领取的所有任务一次性领取完,然后去慢慢完成,最后再一次性把任务奖励都领取了,这就叫作广度优先搜索。
实现爬取小说
from matplotlib.pyplot import title
import requests
import re
from multiprocessing.dummy import Pool
import os
def find_chapter_content(url):
http = "https://www.bswtan.com/0/9/"
content = requests.get(http+url).content.decode()
title = re.search('<h1>(.*?)</h1>',content).group(1)
content1 = re.search('<div id="content">(.*?)</div>',content).group(1)
return [title,content1]
def save(c):
title,content1 = c[0],c[1]
os.makedirs("凡人修仙传",exist_ok=True)
with open(os.path.join('./凡人修仙传',title+'.txt'), 'w', encoding='utf-8') as f:
f.writelines([title,content1])
content1 = requests.get('https://www.bswtan.com/0/9/').content.decode()
chapter_url = re.findall('<a href="(.*?)">(.*?)</a>',content1)
chapter_list = []
url_list = []
for url,chapter in chapter_url:
if chapter[0] == "第":
chapter_list.append(chapter)
url_list.append(url)
pool = Pool(10)
result = pool.map(find_chapter_content,url_list)
pool.map(save,result)
print("finish")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号