
ML(3)——线性回归
在统计学中,线性回归(Linear Regression)是利用称为线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。这种函数是一个或多个称为回归系数的模型参数的线性组合。只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归。
模型
一元回归
以房价预测为例,假设存在这样的训练集:
|
m2 |
Price |
|
123 |
2250000 |
|
86 |
1850000 |
|
76 |
1280000 |
|
179 |
2860000 |
|
120 |
2050000 |
|
123 |
2350000 |
|
90 |
1300000 |
在上表中,房价和房屋大小存在一定的关联,我们试图寻找到一个模型表达这个关联,从而预测某个面积的房价。线性回归就是这样一种模型,它用一条直线拟合数据:
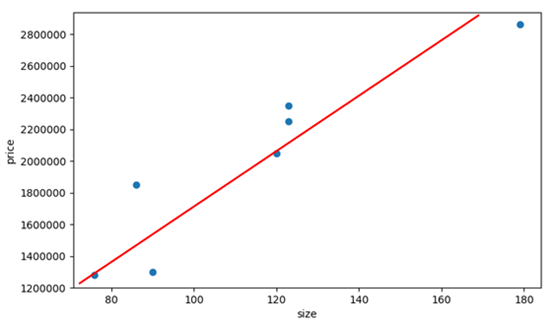
通过这条直线,可以预测任意面积的房价:
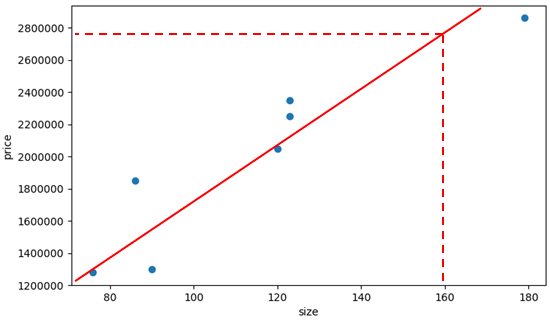
160平米的房价大概是2750000。线性回归之所以叫“线性”,正是由于其连续型,也就是模型函数是连续的,可以对任意值进行预测;至于“回归”,还是别去计较了。
上面是线性回归中最简单的一元模型,只有一个自变量,它用线性模型去拟合数据,其假设函数(hypothesis function) hθ(x)是:
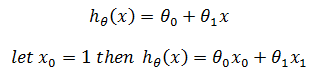
这也是我们熟悉的直线函数y = kx + b。
多元回归
在真实的世界中,房价还和很多因素有关,比如房屋的位置,楼层高度,是否是学区房等,此时需要用到多元回归模型:
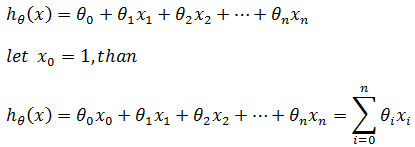
如果用向量表示:
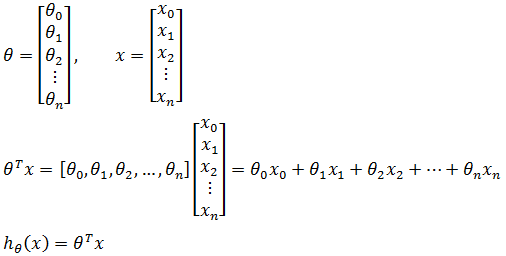
向量有几种写法,在线性代数中用矩阵表示,高数中用尖括号<x1,x2….>表示,我们选取其中一种即可。关于向量的内容可参考《线性代数》中的相关内容。
从上面可以看到,多元模型最终又化简为y = kx的形式。
学习策略
我们的最终目标是找到最佳的θ以拟合最多数据,也就是找到恰当的θ使得所有训练数据误差的总和达到最小化。计算误差的办法有很多种,其中两种典型的做法,一是计算数据到直线的距离(几何距离),二是数据和直线所对应的y值(代数距离)。根据计算方法的不同,得到的最终训练模型也不同。
实际应用中,如果计算点到直线的距离,就需使用两个维度的数据进行计算,而实际上两个维度大多数时候都不存在直接的计算关系,比如时间和房价,二者并不能直接进行指数和加减运算,想要运算必须通过成本函数转换。基于上述原因,通常使用第二种方法,也就是计算数据和直线所对应的y值:
在线性回归中,通常使用平方差损失函数作为J(θ):
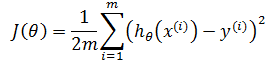
其中m是训练样本的个数,上标i表示第i个训练样本,y表示实际结果。平方是为了得能够进行凸优化的曲线,1/m 是为了使实际值与预测值误差均值接近于0,也就是每一个样本的误差接近于0:
如果写成矩阵的形式:
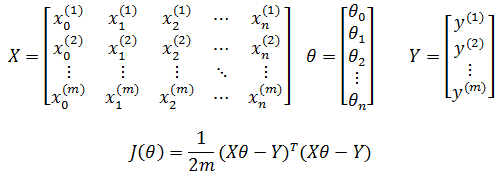
算法
梯度下降
梯度下降是适用范围很广的方法,其更多内容可参考《ML(附录1)——梯度下降》。
根据梯度下降:
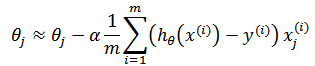
使用更为简洁的矩阵形式:
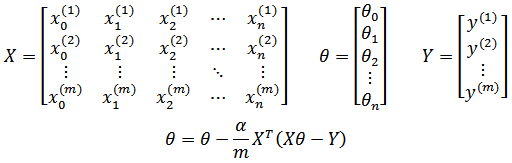
也可以使用随机梯度下降,每次仅选取第i个样本进行迭代:
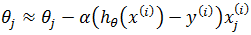
最小二乘法
也可以使用最小二乘法,形成一个对θ求偏导的方程组,通过方程组直接求得θ。关于最小二乘法,可参考《ML(附录2)——最小二乘法》。对于n维向量,转化过程如下:
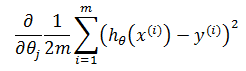
当训练集中仅有一个训练数据,即m = 1时,对θj求偏导:
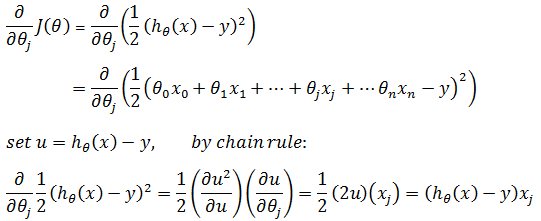
推广到m个数据:
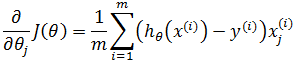
根据最小二乘法,令每个偏导都为0,由此得到含有n+1个方程的方程组:
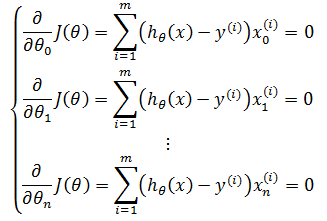
以第二个方程为例:
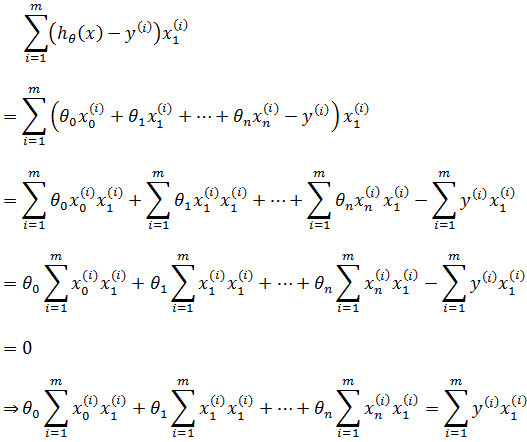
注意:
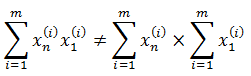
这里需要抑制住冲动,除非m = 1,否则不能将等式两边同时除以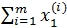
推广至方程组,得到n+1个不同的方程:
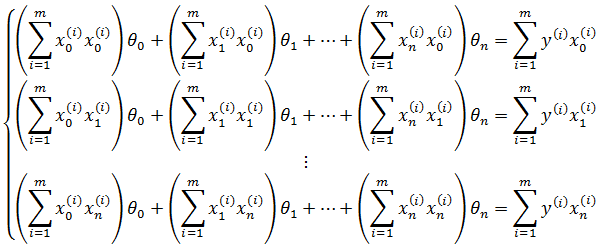
写成矩阵:
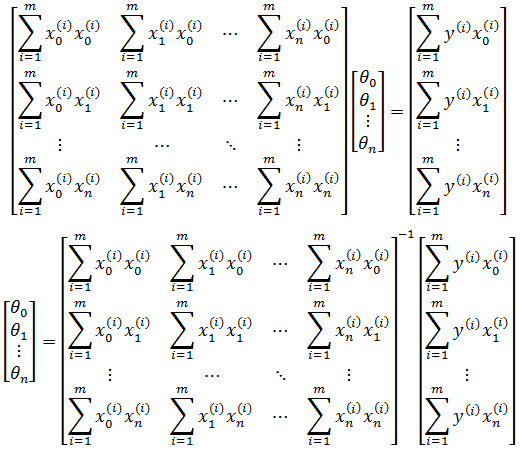
虽然能够最终求得θ,但是这种写法太过低效,在计算时很容易出错,更高效的法案是改为矩阵。以房价为例, 如果最终预测模型是hθ(x) = 20 + 2x,那么对于123m2,86m2,76m2三个数据的预测结果可以写作:
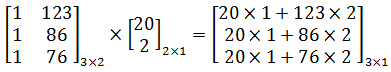
如果将模型参数和训练集全部看作矩阵向量:
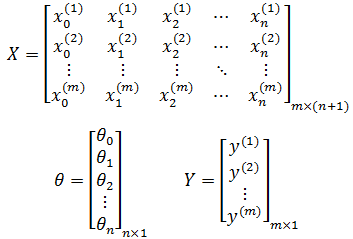
现在:
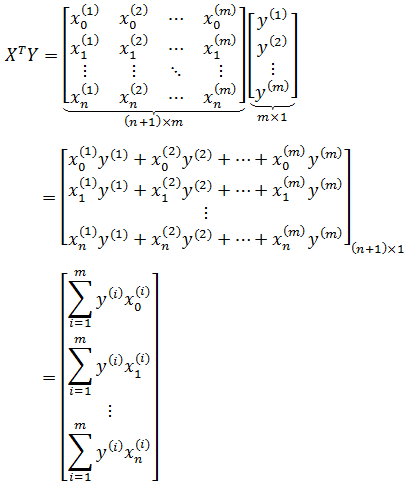
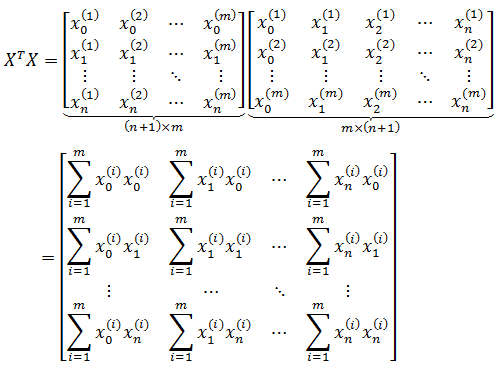
最终得到和代数结果吻合的矩阵形式:
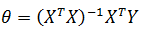
更简单的方法是直接把损失函数写成矩阵形式,然后对矩阵偏导,具体推导过程将在后续线性代数部分补充。
梯度下降和最小二乘的对比
既然最小二乘法的实现更加简单,是否我们可以总是使用它呢?当然不是,最主要的原因就是矩阵的乘法和求逆十分耗时,当X是n×n矩阵时,对(XTX)-1的运算耗时是O(n3)。在实际应用中,如果n > 10000,就应该考虑体地下降。
|
梯度下降 |
最小二乘法 |
|
需要选择学习率α |
不需要学习率 |
|
需要多次迭代 |
不需要迭代 |
|
当n很大时,能够有效运行 O(kn2) |
当n很大时,无法有效工作 O(n3) |
数据预处理
在房价的例子中,房子的总价过于庞大,每次迭代都使用这种大数计算将会减慢速度;对于梯度下降来说,将会导致收敛速度变慢,从而增加迭代次数。如果把所有房价都除以10000,将得到这样的数据:
|
m2 |
Price |
|
123 |
225 |
|
86 |
185 |
|
76 |
128 |
|
179 |
286 |
|
120 |
205 |
|
123 |
235 |
|
90 |
130 |
根据这样的值计算,会使算法速度加快。需要注意的是,由于改变的是因变量的值,所以最终预测结果要再乘以10000。
更一般的数据整理方法是一种被称“归一化”的方法,它能使所有维度的数据都转换为同一量级,其公式是:
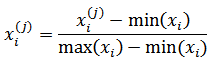
max(xi) – min(xi)表示所有样本集中最大xi和最小xi之间的差值,该方法也称为max-min归一化。
代码实现
这里给出了python和Matlab两种实现,二者使用的训练集一致,都使用梯度下降。在Python中使用普通代数法循环计算,Matlab中使用矩阵直接计算。
训练数据ex1data1.txt:


1 6.1101,17.592 2 5.5277,9.1302 3 8.5186,13.662 4 7.0032,11.854 5 5.8598,6.8233 6 8.3829,11.886 7 7.4764,4.3483 8 8.5781,12 9 6.4862,6.5987 10 5.0546,3.8166 11 5.7107,3.2522 12 14.164,15.505 13 5.734,3.1551 14 8.4084,7.2258 15 5.6407,0.71618 16 5.3794,3.5129 17 6.3654,5.3048 18 5.1301,0.56077 19 6.4296,3.6518 20 7.0708,5.3893 21 6.1891,3.1386 22 20.27,21.767 23 5.4901,4.263 24 6.3261,5.1875 25 5.5649,3.0825 26 18.945,22.638 27 12.828,13.501 28 10.957,7.0467 29 13.176,14.692 30 22.203,24.147 31 5.2524,-1.22 32 6.5894,5.9966 33 9.2482,12.134 34 5.8918,1.8495 35 8.2111,6.5426 36 7.9334,4.5623 37 8.0959,4.1164 38 5.6063,3.3928 39 12.836,10.117 40 6.3534,5.4974 41 5.4069,0.55657 42 6.8825,3.9115 43 11.708,5.3854 44 5.7737,2.4406 45 7.8247,6.7318 46 7.0931,1.0463 47 5.0702,5.1337 48 5.8014,1.844 49 11.7,8.0043 50 5.5416,1.0179 51 7.5402,6.7504 52 5.3077,1.8396 53 7.4239,4.2885 54 7.6031,4.9981 55 6.3328,1.4233 56 6.3589,-1.4211 57 6.2742,2.4756 58 5.6397,4.6042 59 9.3102,3.9624 60 9.4536,5.4141 61 8.8254,5.1694 62 5.1793,-0.74279 63 21.279,17.929 64 14.908,12.054 65 18.959,17.054 66 7.2182,4.8852 67 8.2951,5.7442 68 10.236,7.7754 69 5.4994,1.0173 70 20.341,20.992 71 10.136,6.6799 72 7.3345,4.0259 73 6.0062,1.2784 74 7.2259,3.3411 75 5.0269,-2.6807 76 6.5479,0.29678 77 7.5386,3.8845 78 5.0365,5.7014 79 10.274,6.7526 80 5.1077,2.0576 81 5.7292,0.47953 82 5.1884,0.20421 83 6.3557,0.67861 84 9.7687,7.5435 85 6.5159,5.3436 86 8.5172,4.2415 87 9.1802,6.7981 88 6.002,0.92695 89 5.5204,0.152 90 5.0594,2.8214 91 5.7077,1.8451 92 7.6366,4.2959 93 5.8707,7.2029 94 5.3054,1.9869 95 8.2934,0.14454 96 13.394,9.0551 97 5.4369,0.61705
Python
1 from __future__ import division 2 import numpy as np 3 import random 4 import matplotlib.pyplot as plt 5 6 def train(X, Y, iterateNum=1500, alpha=0.01): 7 ''' 8 :param X: 9 :param Y: 10 :param iterateNum: 梯度下降的迭代次数 11 :param alpha: 学习率 12 :return:theta 13 ''' 14 m, n = np.shape(X) 15 # 在第一列添加x0 16 X_new = np.c_[np.ones(m), X] 17 theta = np.zeros((n + 1, 1)) 18 19 for i in range(iterateNum): 20 h = h_function(X_new, theta) 21 theta -= (alpha / m) * np.dot(X_new.T, h - Y) 22 23 return theta 24 25 # 计算假设函数的值 26 def h_function(X, theta): 27 ''' 28 :param X: 训练集的特征,m * n矩阵 29 :param theta: θ列向量, n * 1矩阵 30 :return: m * 1矩阵,每一行都是假设函数的值, hθ(x) 31 ''' 32 return np.dot(X, theta) 33 34 def plot_datas(X, Y, theta): 35 # paint line g = θ0 + θ1x1 36 x = [5, 25] 37 # y = θ0 + θ1x1 38 y = [h_function([1, 5], theta), h_function([1, 25], theta)] 39 plt.plot(x, y) 40 41 plt.xlabel('x') 42 plt.ylabel('y') 43 # paint scatter points 44 plt.scatter(X, Y, c='r', marker='x') 45 46 label = ['Training data', 'Linear regression'] 47 plt.legend(label) 48 plt.show() 49 50 if __name__ == '__main__': 51 train_datas = np.loadtxt("ex1data1.txt", delimiter=',') 52 X = train_datas[:, [0]] 53 Y = train_datas[:, [1]] 54 theta = train(X, Y) 55 print(theta) 56 plot_datas(X, Y, theta) 57 58 # [-3.6302914394043602, 1.166362350335582]
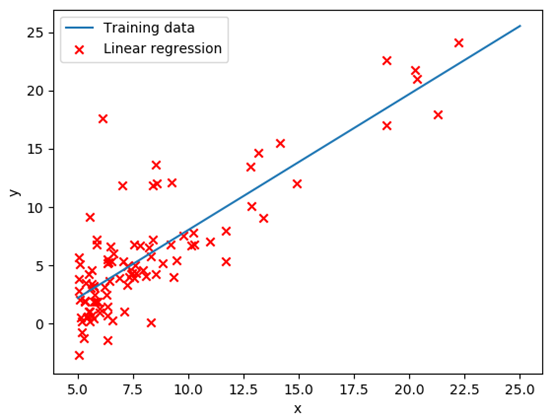
Θ = [-3.6302914394043602, 1.166362350335582]
sklearn
1 sklearn 2 from sklearn.linear_model import LinearRegression 3 import numpy as np 4 5 if __name__ == '__main__': 6 train_datas = np.loadtxt("ex1data1.txt", delimiter=',') 7 X_train = train_datas[:,[0]] 8 Y_train = train_datas[:,[1]] 9 linear = LinearRegression() 10 linear.fit(X_train, Y_train) 11 12 theta = [linear.intercept_[0], linear.coef_[0][0]] 13 print(theta)
Matlab
%% =======================Load data and Plotting =======================
fprintf('Plotting Data ...\n')
data = load('ex1data1.txt');
X = data(:, 1); y = data(:, 2);
m = length(y); % number of training examples
% Plot Data
figure;
plot(x, y, 'rx', 'MarkerSize', 10);
xlabel('x');
ylabel('y');
fprintf('Program paused. Press enter to continue.\n');
pause;
%% =================== Cost and Gradient descent ===================
X = [ones(m, 1), data(:,1)]; % Add a column of ones to x
theta = zeros(2, 1); % initialize fitting parameters
% Some gradient descent settings
iterations = 1500;
alpha = 0.01;
fprintf('\nRunning Gradient Descent ...\n')
% run gradient descent
theta = [0;0];
m = length(y); % number of training examples
for iter = 1:num_iters
theta -= (alpha / m) * (X' * (X * theta - y));
end;
% print theta to screen
fprintf('Theta found by gradient descent:\n');
fprintf('%f\n', theta);
% Plot the linear fit
hold on; % keep previous plot visible
plot(X(:,2), X*theta, '-')
legend('Training data', 'Linear regression')
hold off
作者:我是8位的
出处:http://www.cnblogs.com/bigmonkey
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
扫描二维码关注公众号“我是8位的”



 浙公网安备 33010602011771号
浙公网安备 33010602011771号