集成学习之AdaBoost
AdaBoost
当做出重要决定时,大家可能会考虑吸取多个专家而不只是一个人的意见,机器学习也是如此,这就是集成学习的基本思想。使用集成方法时有多种形式:可以是不同算法的集成,也可以是同一算法在不同设置下的集成,还可以是数据集不同部分分配给不同分类器之后的集成。
由于集成学习有效地考虑了多个不同的模型,一般而言能够获得较好的性能,因此在很多注重算法性能的场合,集成学习一般是首选。例如,在很多数据挖掘的竞赛中,获胜的算法一般都是使用集成学习将多个模型聚合而成。
与单个模型相比,集成学习的缺点包括:
(1)计算复杂度较大。因为在集成学习中需要训练多个模型,所以计算复杂度会有较大程度的提高;
(2)一般而言,所得的模型很难解释。如单个决策树模型很容易解释,而由多个决策树组成的随机森林(random forest)却不大容易解释。
根据基学习器的生成策略,集成学习的方法可以分为两类:
(1)并行方法(parallel method),以bagging为主要代表;
(2)顺序方法(sequential method),以boosting为主要代表。
Bagging
bootstrap aggregating方法也称为bagging方法,是从原始数据集进行随机放回抽样后得到彼此独立的M个新数据集的技术。新数据集中可以有重复的数据,原数据集中的部分数据可能不会在新数据集中出现。
在M个数据集建立好后,将分类器算器(可以使用多种不同算法)分别作用于M个数据集,这样就得到了M个模型。当对新数据分类时,就可以应用这M个分类模型分类,对结果进行投票,得票最多的即是最后结果。随机森林是一种更先进的bagging方法。
Bagging算法过程如下:
- 每轮从原始训练集中有放回地抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中)。共进行M轮抽取,得到M个训练集。(M个训练集之间是相互独立的)
- 每次使用一个训练集得到一个模型,M个训练集共得到M个模型。(这里并没有具体的分类算法或回归方法,我们可以根据具体问题采用不同的分类或回归方法,如决策树、感知器等)
- 对分类问题:将上步得到的M个模型采用投票的方式得到分类结果;对回归问题,计算上述模型的均值作为最后的结果。(所有模型的重要性相同)
Boosting
Boosting是与Bagging相似的一种技术,其核心思想是针对同一个训练集训练出不同的弱分类器,然后把这些弱分类器集合起来,构造一个更强的最终分类器。
所谓弱分类器,意味着分类器的正确性比随机猜测略好,但是不会好太多。这就意味着在二分类的情况下弱分类器的错误率可能高于50%,而强分类器的错误率就会低很多。
多个弱分类器的意思并不是指每种分类器都使用了不同的分类算法,而是使用了同一分类算法,但是经过训练得出不同的模型。例如,使用线性分类器对一维特征集进行分类,由于训练数据不同,将得到f(x)=2x+3和f(x)=2.5x+2两个分类模型。
在PAC(概率近似正确)学习框架下,一定可以将弱分类器组装成一个强分类器。PAC 定义了学习算法的强弱:
- 弱学习算法---识别错误率小于1/2(即准确率仅比随机猜测略高的学习算法)
- 强学习算法---识别准确率很高并能在多项式时间内完成的学习算法
Valiant和 Kearns首次提出了PAC学习模型中弱学习算法和强学习算法的等价性问题,即任意给定仅比随机猜测略好的弱学习算法,是否可以将其提升为强学习算法? 如果二者等价,那么只需找到一个比随机猜测略好的弱学习算法就可以将其提升为强学习算法 ,而不必寻找很难获得的强学习算法。也就是这种猜测,让无数牛人去设计算法来验证PAC理论的正确性。
AdaBoost
上面提到了对PAC模型的猜测,不过很长一段时间都没有一个切实可行的办法来实现这个理想。细节决定成败,再好的理论也需要有效的算法来执行。终于功夫不负有心人,Schapire在1996年提出一个有效的算法真正实现了这个夙愿,它的名字叫AdaBoost。AdaBoost把多个不同的决策树用一种非随机的方式组合起来,表现出惊人的性能!第一,把决策树的准确率大大提高,可以与SVM媲美。第二,速度快,且基本不用调参数。第三,几乎不Overfitting。我估计当时Breiman和Friedman肯定高兴坏了,因为眼看着他们提出的CART正在被SVM比下去的时候,AdaBoost让决策树起死回生!Breiman情不自禁地在他的论文里赞扬AdaBoost是最好的现货方法(off-the-shelf,即“拿下了就可以用”的意思)。
AdaBoost是adaptive boosting的缩写,是众多Boosting算法中较为流行的一种。
AdaBoost算法针对不同的训练集训练同一个(使用相同算法)基本分类器(弱分类器),然后把这些在不同训练集上得到的分类器集合起来,构成一个更强的最终的分类器(强分类器)。理论证明,只要每个弱分类器分类能力比随机猜测要好,当其个数趋向于无穷个数时,强分类器的错误率将趋向于零。这点可以用直观感觉判断,只要每个分类器的正确率比错误率稍高一点点,当分类器足够多的时候,正确的数量就会压倒错误的数量。
需要注意都是,AdaBoost训练的所有分类器,在训练集上的正确率都应当高于50%,否则这个分类器将比随机猜测还要差,可能根本就是一个错误的分类器,上面的结论(当分类器足够多的时候,正确的数量就会压倒错误的数量)也不成立。
AdaBoost算法中不同的训练集是通过调整每个样本对应的权重实现的。一开始的时候每个样本的权重相等,由此训练处一个基本分类器C1。对于C1分错和分对的样本,分别增大和减小其权重,再计算出C1的权重;重复该操作M轮,以使得权重大的样本更倾向于分类正确,最终得出总分类器。从直观上讲,后面的弱分类器集中处理前面被错分的样本,这样使得分类器犯的错误各不相同,因此聚合之后能够得到较好的效果。

具体过程如下:
- 共有N个训练样本
- 训练集中的每个样本的权重为W,Wi表示第i个样本的权重系数,W的初始值是1/N
- 共训练M轮,每轮得到得到一个弱分类器C,Cm表示第m轮训练后得到的弱分类器
- 开始迭代,计算每个弱分类器的权重,并更新样本的权重系数
4.1.每轮中分类器的加权误差率为:
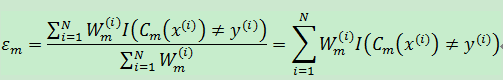
该误差率也是每轮基本分类器的损失函数,训练的目标是使损失函数最小。上式中下标m表示第m轮训练;上标i表示第i个训练样本;分母值为1。其中εm表示在第m轮训练中,弱分类器Cm的加权误差率,介于[0,1]之间; I(Cm(x(i))≠y(i))是一个指示函数,具体如下:
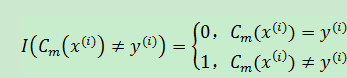
4.2.计算弱分类器Cm的权重系数,也就是Cm在整个算法中的话语权:
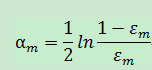
函数曲线如下:
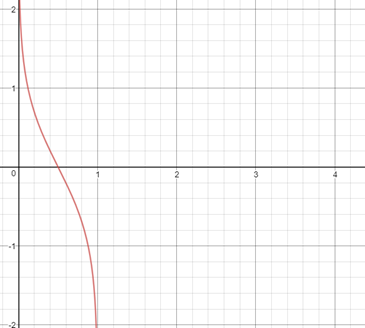
由此可见,分类器加权误差率越小,其权重越大;方误差率超过0.5时,权重降为负值,这也是我们需要舍弃错误率在50%以上的分类器的原因。
4.3.更新训练集中每个训练样本的权重系数:
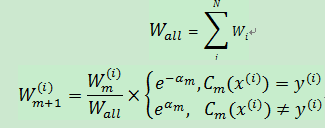
由于αm>0,故而exp(-αm)<1,当样本被基本分类器正确分类时,其权重在减小,反之权重在增大。
4.4.跳转到4.1直到迭代结束。
5.得到最后的总分类器,总分类器是由每轮迭代产生的弱分类器综合而来:
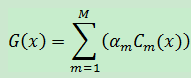
如果是二分类:

实质上,在整个训练的过程中,每轮训练得到的弱分类器可能一直会存在分类错误的问题(不论训练了多少轮,生成的单个弱分类器都有分类错误),然而整个AdaBoost框架却有可能快速收敛(整个AdaBoost框架的错误率为0)。造成这个现象的原因是:
每轮训练结束后,AdaBoost框架会对样本的权重进行调整,该调整的结果是越到后面被错误分类的样本权重会越高。这样到后面,单个弱分类器为了达到较低的带权分类误差都会把样本权重高的样本分类正确。虽然单独来看,单个弱分类器仍会造成分类错误,但这些被错误分类的样本的权重都较低,在AdaBoost框架的最后输出时会被前面正确分类的高权重弱分类器“平衡”掉。这样造成的结果就是,虽然每个弱分类器可能都有分错的样本,然而整个AdaBoost框架却能保证对每个样本进行正确分类,从而实现快速收敛。
Bagging与Boosting的区别
1.样本选择:
Bagging:每一轮的训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2.样例权重:
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3.预测函数:
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4.并行计算:
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
示例
给定训练集中有10个训练样本:
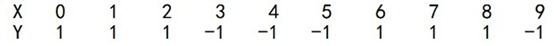
如果进行3轮迭代,根据上面的介绍:M=3,N=10,基础分类器为决策树。
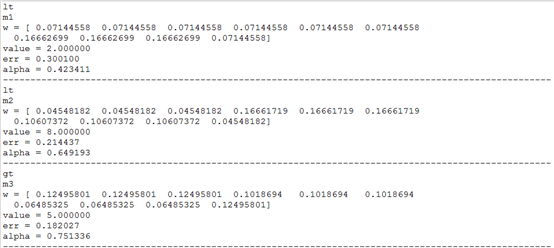
第1轮迭代,M=1
样本权值W1(i)=1/10=0.1,
当选择x<=2为1进行分类时,[[6],[7],[8]]分错,此时得到最佳误差率ε1 = 0.300100
分类器
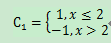
α1 = 0.423411
第2轮迭代,M=2
新一轮的样本权值W2=[0.07144558 0.07144558 0.07144558 0.07144558 0.07144558 0.07144558 0.16662699 0.16662699 0.16662699 0.07144558],上轮分错的[[6],[7],[8]]权值增大,其余减小。
当选择x<=8为1进行分类时,[[3],[4],[5]]分错,此时得到最佳误差率ε2 =0.214437
分类器
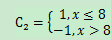
α2 = 0.649193
第3轮迭代,M=3
新一轮的样本权值W3=[ 0.04548182 0.04548182 0.04548182 0.16661719 0.16661719 0.16661719 0.10607372 0.10607372 0.10607372 0.04548182],上轮分错的[[3],[4],[5]]权值增大,其余减小。
当选择x>5为1进行分类时,[[0],[1],[2],[9]]分错,此时得到最佳误差率ε3 =0.182027
分类器
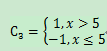
α3 = 0.751336
总分类器
H(x) = sign(0.423C1(x)+0.649C2(x)+ 0.182C3(x))
代码
1 MIN_ERR = 0.0001 2 class MyAdaBoost: 3 def __init__(self, x_features, y_labels, classifer): 4 #总训练集features 5 self.x_features = np.array(x_features) 6 #总训练集labels, 取值 -1, 1 7 self.y_labels = np.array(y_labels) 8 #共N个训练集 9 self.N = self.x_features.shape[0] 10 #基础分类器,分类器的预测结果返回-1或1 11 self.classifer = classifer 12 #初始化每个训练集的加权值 13 self.W = np.ones((self.N, 1)) / self.N 14 15 16 def train(self, M:'迭代次数'=3): 17 #每次迭代形成的分类器 18 self.C = {} 19 #分类器权重 20 self.alpha = {} 21 22 #迭代M次 23 for i in range(M): 24 #本轮分类器 25 self.C[i] = self.classifer(self.x_features, self.y_labels) 26 #本轮分类器的加权误差率 27 err = self.C[i].train(self.W) 28 #self.C[i] 的权重 29 self.alpha[i] = 1 / 2 * np.log((1 - err) / err) 30 #分类器C[i]的预测结果 31 pred_y = np.array(self.C[i].pred(self.x_features)) 32 #flatten返回一个叠成一维的数组,预测结果与实际结果相乘,相同为1,相异为-1 33 pred_compare = pred_y.flatten() * self.y_labels.flatten() 34 #重新计算训练样本的权值 35 Z = self.W.flatten() * np.exp(-self.alpha[i] * pred_compare) 36 self.W = (Z / Z.sum()).reshape(self.N, 1) 37 38 print('m%d'%(i+1)) 39 print('w =', self.W.flatten()) 40 print('value = %f' % self.C[i].item_value) 41 print('err = %f' % err) 42 print('alpha = %f' % self.alpha[i]) 43 print('-' * 100) 44 45 if err <= MIN_ERR: 46 break 47 48 def pred(self, test_x): 49 sums = 0 50 for i in self.C: 51 sums += self.C[i].pred(test_x) * self.alpha[i] 52 53 return np.sign(sums) 54 55 class DumpClassifier: 56 def __init__(self, x_features, y_labels): 57 self.x_features = x_features 58 self.y_features = y_labels 59 #分裂项的下标 60 self.item_idx = 0 61 #分裂项的值 62 self.item_value = 0 63 #训练集的权值 64 self.W = None 65 66 self.threshIneq = 'lt' 67 68 def train(self, W): 69 self.W = W 70 #最小误差值 71 minErr = 9999999 72 #分裂项缓存,存储分裂项下标和分裂项值组成的元组 73 descItem = {} 74 75 #按列循环 76 for idx in range(self.x_features.shape[1]): 77 #根据这一列的每个值尝试对数据集进行拆分 78 for value in self.x_features.T[idx]: 79 if (idx, value) in descItem: 80 minErr = descItem[(idx, value)] 81 continue 82 83 #寻找最佳决策树 84 thisErr_gt = self.getThisErr(idx, value, 'gt') 85 thisErr_lt = self.getThisErr(idx, value, 'lt') 86 thisErr = min(thisErr_gt, thisErr_lt) 87 if thisErr < minErr: 88 self.item_idx, self.item_value, minErr = idx, value, thisErr 89 self.threshIneq = 'lt' if thisErr_lt < thisErr_gt else 'gt' 90 91 descItem[(idx, value)] = minErr 92 93 print(self.threshIneq) 94 return minErr 95 96 def getThisErr(self, idx, value, threshIneq): 97 thisErr = MIN_ERR 98 #循环所有训练集,取得最佳分裂值,i表示第i个训练样本 99 for i in range(self.x_features.shape[0]): 100 x, y = self.x_features[i], y_labels[i] 101 y_pred = self._pred(x, idx, value, threshIneq) 102 if y_pred != y[0]: 103 thisErr += self.W[i] 104 105 return thisErr 106 107 108 def _pred(self, x, item_idx, item_value, threshIneq): 109 if threshIneq == 'lt': 110 return 1 if x[item_idx] <= item_value else -1 111 else: 112 return 1 if x[item_idx] > item_value else -1 113 114 # #连续型数据 115 # if item_idx == 0: 116 # if threshIneq == 'gt': 117 # return 1 if item_value >= x[item_idx] else -1 118 # else: 119 # return 1 if item_value < x[item_idx] else -1 120 # #离散型数据 121 # else: 122 # return 1 if item_value == x[item_idx] else -1 123 124 def pred(self, x_features): 125 y = [] 126 for x in x_features: 127 y.append([self._pred(x, self.item_idx, self.item_value, self.threshIneq)]) 128 129 return y
控制台结果:
出处:微信公众号 "我是8位的"
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
扫描二维码关注作者公众号“我是8位的”



 浙公网安备 33010602011771号
浙公网安备 33010602011771号