数据分析(4)——闲话抽样
中国的人口普查大名鼎鼎,这里的普查是指对总体的研究和调查,普查内容包括人的基本情况、迁移流动状况、人口素质情况,就业、社会保障状况、婚姻生育状况等多项内容。但是中国的人口过于庞大,不可能对每个人都进行调查,这样一来,抽样就显得十分重要。在抽样之前,先来看看数据是如何获取的。
获取数据
大多数时候,我们获取数据的方式仅仅是坐在计算机前查看某个数据库或解析某个流式文件,在进行这种行为时,并没有影响事件的发生——你在进行订单统计时,并没有对客户的下单产生任何影响。
这种获取数据的方法属于被动获取,你所做的仅仅是对主动上门的数据进行收集和分析。这种收集数据的方式操作起来十分简单,但存在一些缺陷。想像一下这样的场景:试验者想观察司机在面对突发状况时的反应。如果仍然是静待数据上门,那么这个试验有可能要进行数年或者数十年——毕竟突发状况极少遇见,我虽然驾驶了超过十万公里,但依然不记得有什么突发状况。
看来被动获取的方式只能收集到客户通过自然行为产生的事件,如果希望主动诱发某种行为,就需要主动出击了。
我们经常看到一些“996”的信息:某些公司变相鼓励加班,诱导员工自愿加班,也就逐渐形成了不得不加班的公司氛围或者是提倡以加班为荣、自愿加班的公司文化。一些企业甚至推行“996工作制”,即工作日早9时上班,晚9时下班,并且一周工作6天。
996到底好不好,汤姆·迪马可和蒂姆·李斯特早在1987年的《人件》上就给出了答案,咱们不对此发表评论,来看一个试验。
2018年3月,新西兰公司Perpetual Guardian在内部试行了四天工作制。试验期为8周,允许公司的240名员工在领取全薪的情况下只需上班四天。为了确保分析的客观,Perpetual Guardian公司首席执行官Andrew Barnes邀请了AUT人力资源管理教授、学术研究员Jarrod Haar,奥克兰大学商学院高级讲师Helen Delaney博士来观察试验对员工的影响。
一开始,试验的风险是存在的。减少工作时间会增加员工完成目标的压力,同时由于工作时间减少五分之一,导致产出水*降低。
但是,随着试验的推进,研究人员发现剧情出现了反转。员工的工作时间只花费了80%,工作效率却提升了20%,而且相比之前更加投入,工作热情也更高。
这种试验称为A/B测试,A代表为了诱发特定行为创造出的试验环境(员工每周工作四天),B代表用于比对的自然环境(每周仍然工作五天)。
Perpetual Guardian用了8周得出了A/B测试的结论,于是很多人把这个结论奉为圣经,对西方国家顶礼膜拜。该结论是否具有普遍性呢?不具备!具体原因要从数据抽样说起。
数据抽样
统计学研究的是总体中的样本,样本通过抽样产生。所谓抽样,就是选取总体中的部分样本作为子集,对该子集进行研究,用子集的数字特征*似地代表总体的数字特征。可以说,统计数字经常是由总体中的某个子集得出的。
随机抽样
关于抽签
提到抽样,总会联想到抽签。抽签属于随机抽样,是一种最常见的抽样方式。当然,抽签也有两种形式,一种是容器法,比如双色球的开奖,把所有球放进容器,每次弹出一个。

在对对大型抽样时,容器法就不管用了,此时可以为抽样空间的每个成员编号,先使用随机生成器生成编号,再通知编号对应的样本。
用计算机解释上述两种方法可能更好理解,第一种是实现准备一个存储了所有抽样空间中的实体的容器,第二是直接根据索引找到对应的实体(该实体可能直接位于总体中),不需要事先准备一单独的个容器。
值得注意的是,我们未必能够对所有的样本进行编号,比如对世界上的动物编号,毕竟人类还有包括深海和雨林在内的众多未涉足的地方。
样本偏差和干扰因子
随机抽样属于等概率抽样,所有样本被抽中的概率相等,这往往意味着随机抽样更加公*,统计结果更接*于总体的特征,但是随机抽样很容易受到干扰因子(confounding factor)的影响,面临样本偏差(sampling bias)的风险。
Perpetual Guardian公司在内部试行了四天工作制,得出的结论是工作效率提升了20%。Perpetual Guardian是一家金融咨询公司,公司的员工是该领域的精英,他们都有自驱意识,因此工作效率能够提升20%。如果把这个试样放在某机构的信访办,结果就不好说了。公司的性质和员工的背景就是实验的干扰因子,只能说这个试验对于像Perpetual Guardian这样的公司有效。如果真正想了解四天工作制是否能提升工作效率,需要随机选择不同行业的公司,并随机选择公司不同层级的员工。
缺乏随机性导致了样本偏差,很多原因都可能造成缺乏随机性。四天工作制的试验是由于抽样空间设计的过于狭窄。此外还有很多情况,人为的因素也是其中之一,比如某个大学的小伙子在街头上邀请路人填写调查问卷,他可能会故意寻找一些年轻漂亮的小姐姐,以便借机搭讪。

重复抽样和不重复抽样
随机抽样还包括重复抽样和不重复抽样。顾名思义,重复抽样指抽取一个样本并研究后把这个样本又放回了样本集,下次抽取时可能又抽到了同一个样本:小伙又拦下了一个小姐姐,但是忘记了这个小姐姐1小时前已经填写了一份相同的问卷。相对的,不重复抽样就是样本空间的每个样本最多只能有一次被抽中的机会,比如质监局对食品的调查,拆开的食品也只能吃掉了,不能再放回去接着卖。
不等概率抽样
随机往往意味着公*,然而看似公*的随机抽样是否真的公*?
某个公司想要组织一次户外运动,选项有真人CS、登山、户外野餐、漂流,由于公司人数太多,行政部的组织小组采用了随机抽样的方式选取了100人进行问询,最后选择真人CS作为本次户外活动。但是活动的结果并不那么令人满意,很多员工反应**,还有部分员工表示以后再也不想参加了。这可不是公司组织活动的初衷,于是组织小组重新收集了差评数据,发现这些差评几乎都来自女性员工。原来该公司女性仅占了20%,她们对户外野餐和漂流更感兴趣,性别因素构成了统计的干扰因子,随机抽样的结果永远是偏向于男性员工。
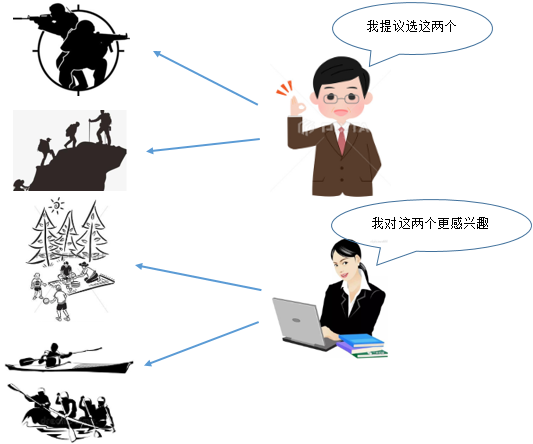
解决的办法是在抽样时适当增加女员工的占比,使得男女比例趋*于*衡。适当为随机抽样引入一些权重,对消除性别、民族、地域等干扰项是必要的,这也是国家统计局在统计数据时特意增加对少数民族的抽样的原因。
作者:我是8位的
出处:https://mp.weixin.qq.com/s/dkmOLBzYf0orSmRH831eCA
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
扫描二维码关注作者公众号“我是8位的”



 浙公网安备 33010602011771号
浙公网安备 33010602011771号