苏州市java岗位的薪资状况(1)
8月份已经正式离职,这两个月主要在做新书校对工作。9月份陆续投了几份简历,参加了两次半面试,第一次是家做办公自动化的公司,开的薪水和招聘信息严重不符,感觉实在是在浪费时间,你说你给不了那么多为什还往上发布?第二次是家做业务系统的中型公司,结果面试我的技术总监直接被我按在地上摩擦,估计没戏了。还有半次,是个研究所,电话和微信简单沟通了一下,结果感觉自己有点被摩擦的意思,不愧挂着研究俩字。后两家公司的薪水区间几乎相同,但人员的技术水平却相差很大,这让我有些好奇,忍不住想分析一下苏州类似岗位的薪资水平。
我在51job上搜索了一下苏州,计算机软件,互联网/电子商务,计算机服务,近一月的java相关职位,一共33页。
第1页的URL是:
第2页是:
不同之处在 java2,1.html 和 java2,2.html 看来那个不同的数字就是翻页信息。
在浏览器F12一下,页面dom布局大概是这样:
于是爬取了一下全部数据:
1 from urllib.request import urlopen 2 from urllib.error import HTTPError 3 from bs4 import BeautifulSoup 4 import csv 5 from itertools import chain 6 import threading 7 8 def get_jobs(url): 9 ''' 10 根据url爬取职位信息 11 :param url: 12 :return: 职位列表,每个元素是一个四元组(职位名, 薪资,发布时间,详情页面url) 13 ''' 14 try: 15 html = urlopen(url) 16 except HTTPError as e: 17 print('Page was not found') 18 return [] 19 20 jobs = [] 21 try: 22 bsObj = BeautifulSoup(html.read()) 23 jobs_div = bsObj.find('div', {'id': 'resultList'}).findAll('div', {'class':'el'}) 24 for div in jobs_div[1:]: 25 span_list = div.findAll('span') 26 job_name = span_list[0].a.get_text().strip() # 职位名称 27 job_url = span_list[0].a.attrs['href'].strip() # 职位详情url 28 job_comp = span_list[1].a.get_text().strip() #公司名称 29 job_salary = span_list[3].get_text().strip() # 薪资 30 job_date = span_list[4].get_text().strip() # 日期 31 jobs.append((job_comp, job_name, job_salary, job_date, job_url)) 32 except AttributeError as e: 33 print(e) 34 return [] 35 return jobs 36 37 def crawl(): 38 ''' 39 分页苏州市近一月内的java相关职位 40 :return: 职位列表,每个元素是一个四元组(职位名, 薪资,发布时间,详情页面url) 41 ''' 42 # 查询条件:java;苏州;计算机软件、计算机服务(系统、数据服务、维修)、互联网/电子商务;近一月 43 url = 'https://search.51job.com/list/070300,000000,0000,01%252C38%252C32,9,99,java,2,{0}.html?' \ 44 'lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99' \ 45 '&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1' \ 46 '&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=' 47 all_jobs = [] 48 49 def _crawl(page_start, page_end): 50 ''' 51 分页爬取数据 52 :param page_start: 起始页 53 :param page_end: 终止页 54 :return: 55 ''' 56 print('crawl {0}~{1} start...'.format(page_start, page_end)) 57 for i in range(page_start, page_end): 58 # 翻页url 59 page_url = url.format(str(i)) 60 jobs = get_jobs(page_url) 61 if len(jobs) == 0: 62 break 63 all_jobs.append(jobs) 64 print('crawl {0}~{1} over'.format(page_start, page_end)) 65 66 # 线程列表 67 thread_list = [] 68 start_nums = list(range(0, 45, 5)) 69 end_nums = list(range(5, 50, 5)) 70 # 每5页一个线程, 最多50页 71 for i in range(len(start_nums)): 72 t = threading.Thread(target=_crawl, args=(start_nums[i], end_nums[i])) 73 thread_list.append(t) 74 75 print('开始爬取数据...') 76 for t in thread_list: 77 t.start() 78 for t in thread_list: 79 t.join() 80 print('爬取结束') 81 82 return all_jobs 83 84 def save_data(all_jobs): 85 ''' 86 将职位信息保存到joblist.csv 87 :param all_jobs: 二维列表,每个元素是一页的职位信息 88 ''' 89 print('正在保存数据...') 90 with open('joblist.csv', 'w', encoding='utf-8', newline='') as fp: 91 w = csv.writer(fp) 92 # 将二维列表转换成一维 93 t = list(chain(*all_jobs)) 94 w.writerows(t) 95 print('保存结束,共{}条数据'.format(len(t))) 96 97 if __name__ == '__main__': 98 # 爬取数据 99 all_jobs = crawl() 100 # 保存数据 101 save_data(all_jobs)
为了爬的快点,开了多个线程,最后把数据保存在joblist.csv中。近一个月共有967个java相关职位:

打开csv,发现里面的数据并不太好:
……
江苏未至科技股份有限公司,实施工程师(苏州),4-8千/月,09-25,https://jobs.51job.com/suzhou-gxq/105762963.html?s=01&t=0
江苏未至科技股份有限公司,交付工程师,6-7千/月,09-25,https://jobs.51job.com/suzhou-gxq/104253078.html?s=01&t=0
易程创新科技有限公司苏州分公司,高级软件工程师,1-2万/月,09-25,https://jobs.51job.com/suzhou-gxq/100292396.html?s=01&t=0
江苏未至科技股份有限公司,项目经理,0.8-1.6万/月,09-25,https://jobs.51job.com/suzhou-gxq/85646230.html?s=01&t=0
达内时代教育集团,咨询顾问底薪4-7K+五险一金,1-1.5万/月,09-25,https://jobs.51job.com/suzhou-gsq/113505714.html?s=01&t=0
达内时代教育集团,搜索顾问底薪4-7K-上市企业,1-1.5万/月,09-25,https://jobs.51job.com/suzhou-gsq/113505583.html?s=01&t=0
苏州工业园区测绘地理信息有限公司...,Web前端开发工程师,6-15万/年,09-25,https://jobs.51job.com/suzhou-gyyq/86942466.html?s=01&t=0
江苏云坤信息科技有限公司,项目经理,1-1.8万/月,09-25,https://jobs.51job.com/suzhou-gyyq/112994728.html?s=01&t=0
江苏云坤信息科技有限公司,前端开发工程师,0.8-1.5万/月,09-25,https://jobs.51job.com/suzhou-gyyq/70761080.html?s=01&t=0
苏州智享云信息科技有限公司,系统架构师,1.6-2.5万/月,09-25,https://jobs.51job.com/suzhou/108411172.html?s=01&t=0
英诺赛科(苏州)半导体有限公司,MES 工程师,0.6-1万/月,09-25,https://jobs.51job.com/suzhou-wjq/115142646.html?s=01&t=0
苏州麦芒软件科技有限公司,软件测试助理工程师,4-6千/月,09-25,https://jobs.51job.com/suzhou/115511688.html?s=01&t=0
三门峡崤云信息服务股份有限公司,大数据挖掘工程师,0.8-2万/月,09-25,https://jobs.51job.com/sanmenxia/110394655.html?s=01&t=0
苏州春慷咨询管理有限公司,软件实施工程师,0.3-1万/月,09-25,https://jobs.51job.com/suzhou-gsq/115617730.html?s=01&t=0
苏州佑捷科技有限公司,高级开发工程师,1.5-2万/月,09-25,https://jobs.51job.com/suzhou-gxq/114727492.html?s=01&t=0
苏州佑捷科技有限公司,Android开发工程师,1-2.5万/月,09-25,https://jobs.51job.com/suzhou-gxq/114726758.html?s=01&t=0
瑞泰信息技术有限公司,.NET开发工程师(实习生),6.5-8.5千/月,09-25,https://jobs.51job.com/suzhou/108055469.html?s=01&t=0
北京直真科技股份有限公司,前端开发工程师(苏州),1.1-1.7万/月,09-25,https://jobs.51job.com/suzhou/113018219.html?s=01&t=0
……
职位包含测试、项目经理、售前、Android,还有一部分.net也混进来了,所以分析前需要过滤掉这些数据。'测试', '.Net', '运维', '嵌入式','前端',这些职位都不要,’总监', '主管', '技术', '研发', '开发', '经理', 'java', 'JAVA', 'Java', '工程师’ ,这些需要保留。
薪资的单位也不统一,有万/年,万/月,千/月, 统一转换成万/年,没写薪资的也不要。
1 import csv 2 from decimal import Decimal 3 import pandas as pd 4 import numpy as np 5 6 def load_datas(): 7 ''' 8 从joblist.csv中装载数据 9 :return: 数据集 datas 10 ''' 11 datas = [] 12 with open('joblist.csv', encoding='utf-8') as fp: 13 r = csv.reader(fp) 14 for row in r: 15 datas.append(row) 16 return datas 17 18 def clear(datas): 19 ''' 20 数据清洗 21 规则: 22 1.没有标明薪资的,直接去掉; 23 2.万/月和千/月转换成万/年 24 :param datas: 原始数据 25 :return: 清洗后的数据 26 ''' 27 result = [] 28 for d in datas: 29 # 清洗后的数据 30 new_d = [] 31 new_d.append(d[0]) # 公司 32 job = filter_job(d[1]) # 公司 33 # 去掉公司不符合的数据 34 if job == '': 35 continue 36 new_d.append(d[1]) # 职位 37 salary_start, salary_end = salary_trans(d[2]) 38 # 去掉没写薪资的数据 39 if salary_start == '': 40 continue 41 else: 42 new_d.append(salary_start) 43 new_d.append(salary_end) 44 new_d.append(d[3]) # 发布日期 45 new_d.append(d[4]) # 详细页面URL 46 result.append(new_d) 47 return result 48 49 def filter_job(job): 50 ''' 51 过滤职位名称 52 :param job: 职位 53 :return: 如果被过滤掉,返回'' 54 ''' 55 # 黑名单 56 black = ['测试', '.Net', '运维', '嵌入式', '前端'] 57 # job在黑名单中 58 if [job.find(x, 0, len(job)) for x in black].count(-1) < len(black): 59 return '' 60 # job在白名单 61 white = ['总监', '主管', '技术', '研发', '开发', '经理', 'java', 'JAVA', 'Java', '工程师'] 62 if [job.find(x, 0, len(job)) for x in white].count(-1) > 0: 63 return job 64 return '' 65 66 def salary_trans(salary): 67 ''' 68 对薪资进行转换 69 :param salary: 薪资 70 :return: 二元组(起始年薪(万/年), 终止年薪(万/年)) 71 ''' 72 start, end = '', '' # 起始年薪, 终止年薪 73 # 将所有薪资单位转换成 万/年 74 if salary.endswith('万/年'): 75 s = salary.replace('万/年', '').split('-') 76 start, end = s[0], s[1] 77 elif salary.endswith('万/月'): 78 s = salary.replace('万/月', '').split('-') 79 start = (Decimal(s[0]) * 12).normalize() 80 end = (Decimal(s[1]) * 12).normalize() 81 elif salary.endswith('千/月'): 82 s = salary.replace('千/月', '').split('-') 83 start = (Decimal(s[0]) * 12 / 10).normalize() 84 end = (Decimal(s[1]) * 12 / 10).normalize() 85 return str(start), str(end) 86 87 if __name__ == '__main__': 88 # 读取并清洗数据 89 datas = np.array(clear(load_datas())) 90 print(len(datas))
还剩789条。
分析开始。招聘信息上绝大多数都是以起薪资为准, 最高薪资就是做个样子,因此只分析起薪。先快速统计一下:
1 def analysis(datas): 2 ''' 数据分析 ''' 3 df = pd.DataFrame({'comp_name': datas[:, 0], 4 'job_name': datas[:, 1], 5 'salary_start': datas[:, 2], 6 'salary_end': datas[:, 3], 7 'publish_date': datas[:, 4], 8 'url': datas[:, 5]}) 9 # 全部起始薪资 10 salary_col = df['salary_start'] 11 print('按起始薪资快速统计'.center(60, '-'))

一共有789条记录,其中最多的是年薪12W,共出现了162次,大多数职位也就1W的月薪。
再看起薪出现次数最多的top10。
1 def analysis(datas): 2 ''' 数据分析 ''' 3 df = pd.DataFrame({'comp_name': datas[:, 0], 4 'job_name': datas[:, 1], 5 'salary_start': datas[:, 2], 6 'salary_end': datas[:, 3], 7 'publish_date': datas[:, 4], 8 'url': datas[:, 5]}) 9 # 全部起始薪资 10 salary_col = df['salary_start'] 11 print('按起始薪资快速统计'.center(60, '-')) 12 # 按起始薪资快速统计 13 print(salary_col.describe()) 14 # 起薪出现次数最多的top10 15 salary_count_top_n(salary_col, 10) 16 17 def salary_count_top_n(salary_col, n): 18 ''' 起薪出现次数最多的top n ''' 19 print(('起薪出现次数最多的top' + str(n)).center(60, '-')) 20 print('起薪\t数量') 21 # 起薪出现次数最多的top n 22 count_top_n = salary_col.value_counts(sort=True, ascending=False).head(n) 23 print(count_top_n) 24 count_top_n.plot(kind='bar') 25 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 26 plt.xlabel('薪资(万/年)') 27 plt.ylabel('职位数量') 28 plt.show()

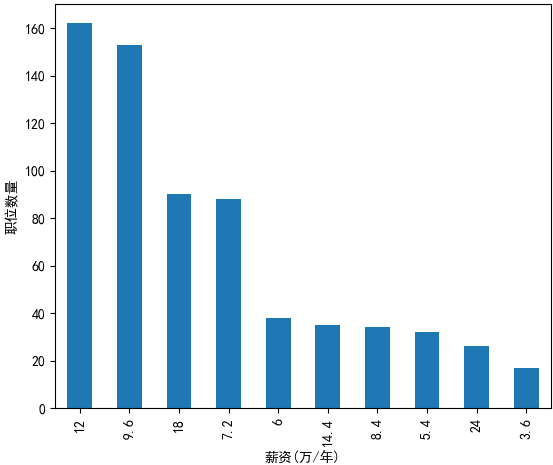
真是一看吓一跳,月薪1W以下大概有500条,约占总职位数量的65%。
再看起薪最高的top 10:
2 ''' 数据分析 ''' 3 df = pd.DataFrame({'comp_name': datas[:, 0], 4 'job_name': datas[:, 1], 5 'salary_start': datas[:, 2], 6 'salary_end': datas[:, 3], 7 'publish_date': datas[:, 4], 8 'url': datas[:, 5]}) 9 …… 10 # 起薪最高的top10 11 urls = salary_high_top_n(df, 10) 12 13 14 def salary_high_top_n(df, n): 15 ''' 起薪最高的top n ''' 16 print(('起薪最高的top' + str(n)).center(60, '-')) 17 salary_grp = df.groupby('salary_start') 18 # 按起薪分组 19 salary_top_n = sorted(salary_grp, reverse=True, key=lambda x: float(x[0]))[0:n] 20 print('%-16s%-20s' % ('起薪', '数量')) 21 # 职位对应的url 22 urls = [] 23 for salary, group in salary_top_n: 24 print('%-20s%-20d' % (salary, len(group))) 25 urls += group.url.values.tolist() 26 return urls
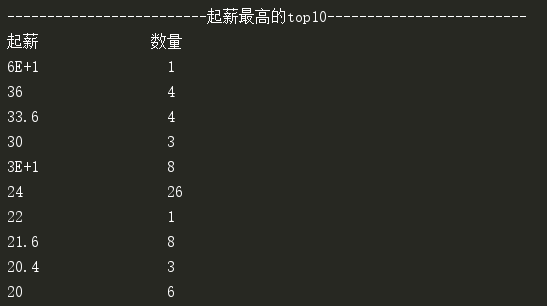
top 10中共64个职位,年薪24W的占了26个,约占top10的40%,24W以下的占了65%以上。月薪2W居然都是高薪了,还有前途吗?
作者:我是8位的
出处:http://www.cnblogs.com/bigmonkey
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
扫描二维码关注公作者众号“我是8位的”



 浙公网安备 33010602011771号
浙公网安备 33010602011771号