
最近看到一个实现crc16的小程序,刚开始,不明觉厉,于是花了一个周末去know how。
CRC(Cyclic Redundancy Check)循环冗余校验是常用的数据校验方法。
先说说什么是数据校验。数据在传输过程(比如通过网线在两台计算机间传文件)中,由于传输信道的原因,可能会有误码现象(比如说发送数字5但接收方收到的却是6),如何发现误码呢?方法是发送额外的数据让接收方校验是否正确,这就是数据校验。最容易想到的校验方法是和校验,就是将传送的数据(按字节方式)加起来计算出数据的总和,并将总和传给接收方,接收方收到数据后也计算总和,并与收到的总和比较看是否相同。如果传输中出现误码,那么总和一般不会相同,从而知道有误码产生,可以让发送方再发送一遍数据。
CRC校验也是添加额外数据做为校验码,这就是CRC校验码,那么CRC校验码是如何得到的呢?
非常简单,CRC校验码就是将数据除以某个固定的数(比如ANSI-CRC16中,这个数是0x18005),所得到的余数就是CRC校验码。
那这里就有一个问题,我们传送的是一串字节数据,而不是一个数据,怎么将一串数字变成一个数据呢?这也很简单,比如说2个字节B1,B2,那么对应的数就是(B1<<8)+B2;如果是3个字节B1,B2,B3,那么对应的数就是((B1<<16)+(B2<<8)+B3),比如数字是0x01,0x02,0x03,那么对应的数字就是0x10203;依次类推。如果字节数很多,那么对应的数就非常非常大,不过幸好CRC只需要得到余数,而不需要得到商。
从上面介绍的原理我们可以大致知道CRC校验的准确率,在CRC8中出现了误码但没发现的概率是1/256,CRC16的概率是1/65536,而CRC32的概率则是1/2^32,那已经是非常小了,所以一般在数据不多的情况下用CRC16校验就可以了,而在整个文件的校验中一般用CRC32校验。【1】
对于lte通信系统, 我们一般采用生成多项式: x16+x12+x5+1, crc16的计算流程可以按照下面的手动计算得到:
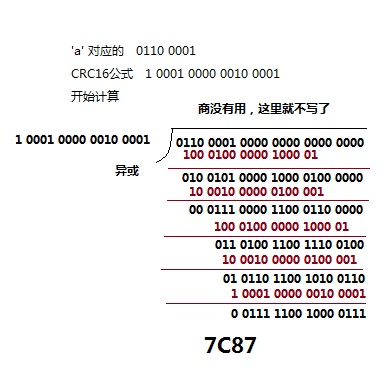 【2】
【2】
根据上图,我们得到按照bit来计算的算法:
1.扩大数据流(左移16位)
2.创建一个16位的寄存器,初始值为数据流前16位
3.
while(比特流最后一位未读入寄存器)
{
if(首位为0)
{
左移一位,低位从比特流中下一位读取
}
else
{
和h(x)进行异或运算
}
}
这样最后16位寄存器中的数据就是求得的16位CRC码。
代码实现如下:
/* input: 1)data: data ptr in unsigned char type
2) data_len_bit: data len in bits
output: crc: crc16 result
*/
unsigned short crc16(unsigned char* data, unsigned short data_len_bit)
{
int i;
unsigned short crc;
unsigned char temp;
unsigned short bit_shift;
// initialize crc little endian
*((char *)&crc) = *(data+1);
*((char *)&crc + 1) = *data;
for(i=0;i<data_len_bit;i++){
if (i<data_len_bit-16){
temp = *(data+2+(i>>3)); // calculate the position of bit in which byte
}else{
temp = 0x00;
}
bit_shift = 7 - (i%8); // calculate bit shift of bit in the specified byte
if (crc>>15)
{
crc = (crc << 1) | (temp>>bit_shift & 0x01); // shift crc one bit and fi ll in a data bit
crc ^= CRC16_POLY; // xor with poly equations.
}else{
crc = (crc << 1) | (temp>>bit_shift & 0x01);
}
}
return crc;
}
对于上面按照bit来计算的程序来说,如果source data bit太多, 就显得不够有效。于是按照字节的算法被提出。 原理理解可以看【3】
简单来讲, 就是假如有byte[0], byte[1]两个source bytes. 可以先将byte[0]后面加16个0,然后做crc16,得到一个16bit的crc. 做完byte[0]后,得到16bit的crc后,该16个bit的左8bit和byte[1]做异或, 然后对该异或的8bit后面加16bit,再做crc16,得到第二个crc, 但是不要忘记,该crc的左8bit 和第一个crc的右8bit有位置重合,那么就需要将重合的8bit做异或,得到最后的crc.
字节型算法的一般描述为:本字节的CRC码,等于上一字节CRC码的低8位左移8位,与上一字节CRC右移8位同本字节异或后所得的CRC码异或。
字节型算法如下:
1)CRC寄存器组初始化为全"0"(0x0000)。(注意:CRC寄存器组初始化全为1时,最后CRC应取反。)
2)CRC寄存器组向左移8位,并保存到CRC寄存器组。
3)原CRC寄存器组高8位(右移8位)与数据字节进行异或运算,得出一个指向值表的索引。
4)索引所指的表值与CRC寄存器组做异或运算。
5)数据指针加1,如果数据没有全部处理完,则重复步骤2)。
6)得出CRC。【4】
代码实现:
unsigned short CRC16_LUT[256];
// to calculate the value in CRC16_LUT
void crc16_init(){
unsigned short data;
unsigned short temp;
unsigned short i;
unsigned short crc;
for (data=0;data<256;data++)
{
crc = 0x0000;
temp = data << 8;
crc = crc ^ temp;
for (i=0;i<8;i++){
if (crc&0x8000){
crc = crc << 1;
crc = crc ^ CRC16_POLY;
}else {
crc = crc << 1;
}
}
CRC16_LUT[data] = crc;
}
return;
}
unsigned short crc16_byte(unsigned char *data, unsigned short data_len)
{
unsigned short crc;
unsigned short data_len_byte, data_len_bit;
unsigned short i, crc16_lut_idx;
unsigned short crc_high, crc_low;
unsigned char temp_data;
data_len_byte = data_len >> 3;
data_len_bit = data_len & 0x0007;
crc=0x0000;
for(i=0;i<data_len_byte;i++){
crc_high = crc >> 8;
temp_data=*(data+i);
crc16_lut_idx = crc_high ^ temp_data;
crc_low = crc << 8;
crc = crc_low ^ CRC16_LUT[crc16_lut_idx];
}
if (data_len_bit != 0){
crc_high = crc >> (16 - data_len_bit);
temp_data=(*(data+data_len_byte)) >> (8-data_len_bit);
crc16_lut_idx = crc_high ^ temp_data;
crc_low = crc << data_len_bit;
crc = crc_low ^ CRC16_LUT[crc16_lut_idx];
}
return crc;
}
【1】https://www.cnblogs.com/sparkbj/articles/6027670.html
【2】http://wdhdmx.iteye.com/blog/1464269
【3】https://blog.csdn.net/huang_shiyang/article/details/50881305
【4】http://www.cnblogs.com/wlei588/p/5993287.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号