

最近在做MMSE均衡器的实现,很耗时间。有如下建议
1. loop 循环里面最好不要加各种判断If else. 可以制表代替。比如说下图代码所示,每个ue被分配一个rbmap, 每一次我们进入到该rb中,我们要判断它里面的每个re是不是rs re, 是不是pbch re, 是不是pss/sss re, 然后我们才能做接下来的动作。最死板的做法就是下面的代码,用了大量的if else, 每一次进入rb, 都有判断几下。

我们可以用制表法重写该部分,如下图所示, 我们通过查表得到rb的类型(pRBPool[rb_idx]),然后根据该类型去找到我们要去的re的位置(gpREMap)以及要做数值变化的指数(mmseREMap)。
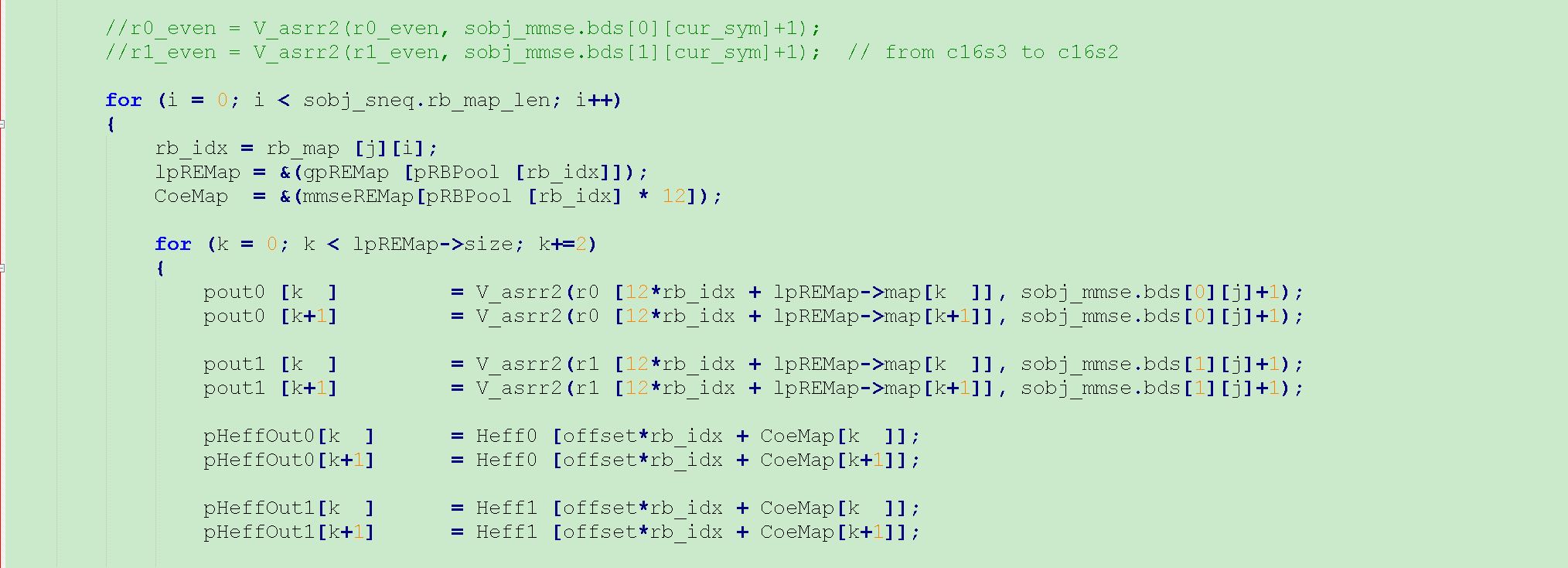
在具体一点,我们把rb分成三类 0: pbch/pss/sss symbol, 1个rb里面12re都不放数据 1:正常rb 12re里面都放数据 2:rs symbol, 中间空4个re, 8 re放数据。pRBPool这个table里面有所有rb的类型(0, 1 or 2)。
然后根据rb类型,得到可以放数据的re的位置(gpREMap, 它的结构体是glt_MMSEDMap_REMap_v_shift_0 or glt_MMSEDMap_REMap_v_shift_1 or glt_MMSEDMap_REMap_v_shift_2)。
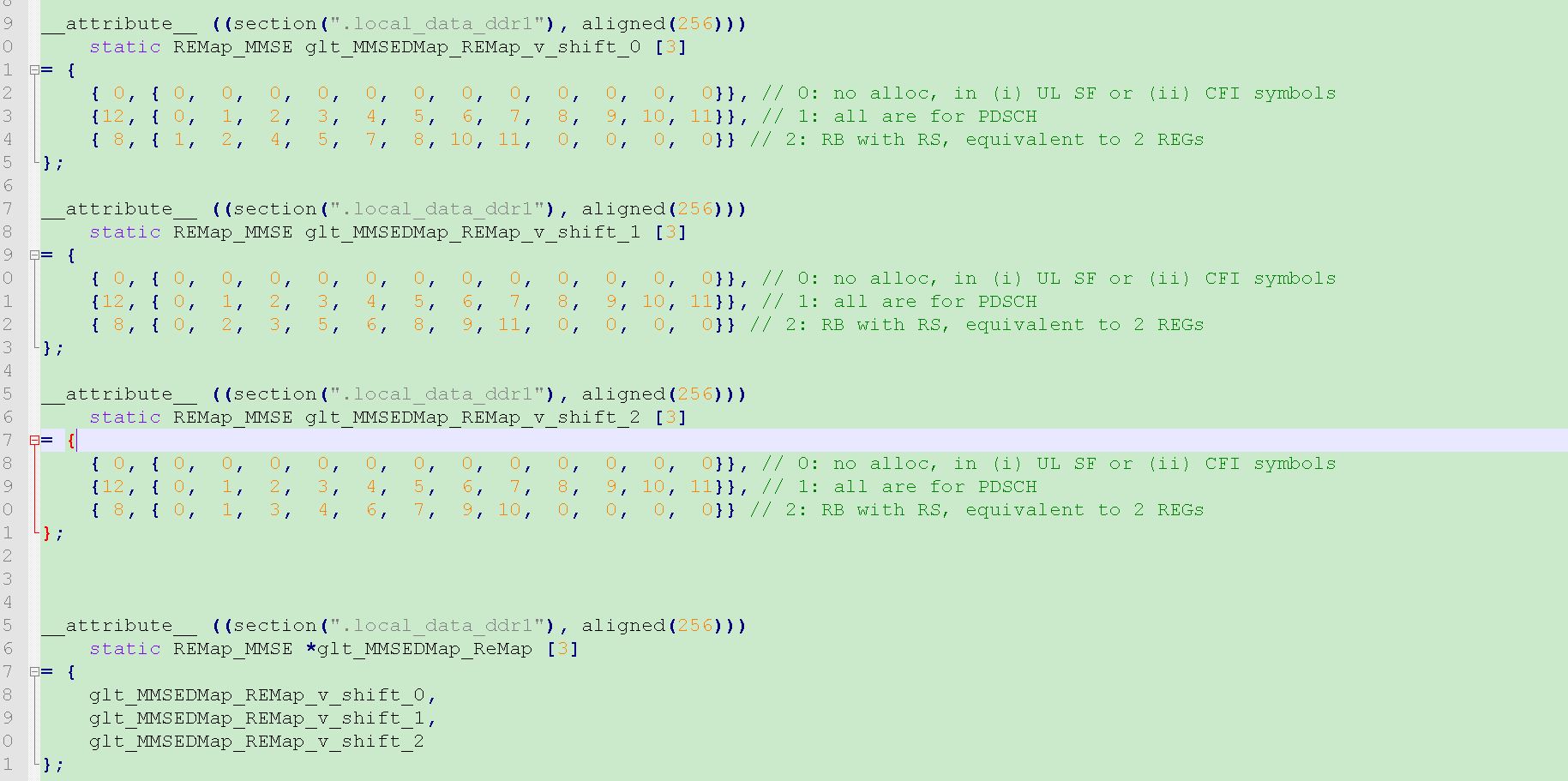
这样写代码是不是很简洁,而且看起来是不是有些水准,比if else那种代码要好很多。测试过,第二种风格的代码比第一种的代码执行起来大概节约一半的processing cycles.
2. 运用一些底层指令集时,要注意有些平台可以一个cycle做4个assembly 指令。那么我们可以把四个指令放在一起,但是里面的参数不能互相依赖,否则不能并行处理。如果是大量并行数据处理的话,最好要处理的数据内存连续,同时loop循环里面不要出现if else,这样compiler 会自动帮我们优化。
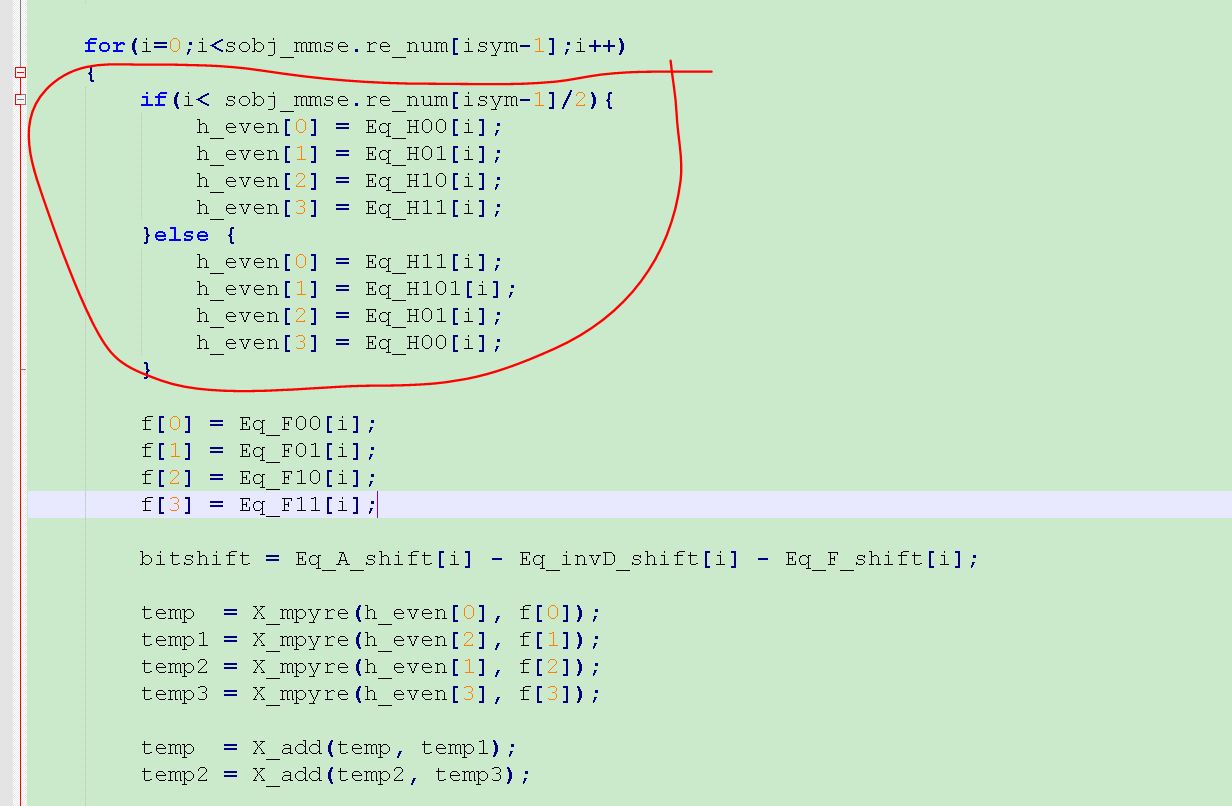
上图不可取,loop循环里面加入了ifelse, 会影响compiler优化。可以分为两个loop来把if else 拿开。
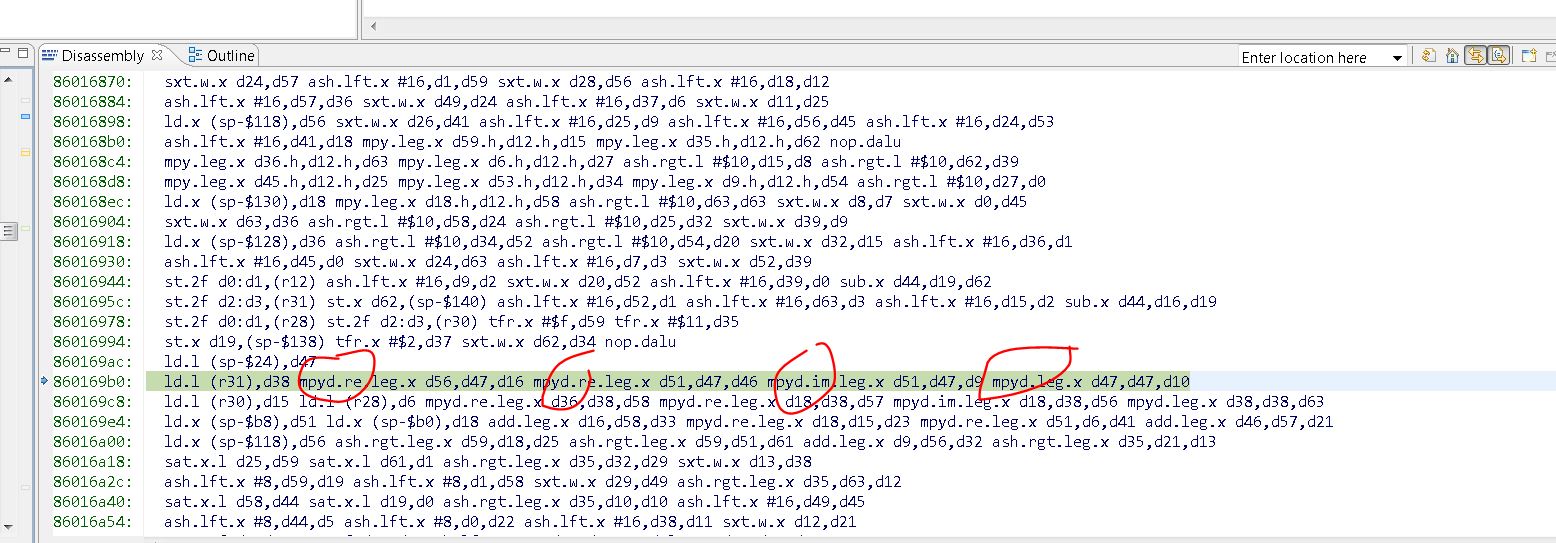
上图,我们可以看到,assembly里面一次性执行了4个乘法(mpyd),速度直接快了4倍。如果想尽可能地优化的话,不理算法层面的缩减,那么我们可以走进assembly,一句一句看是否可以并行运行4次。
3. 运用一些restrict等关键词告诉complier做一些优化。比如说, 关于restrict的用法,从wifi摘抄如下
If the compiler knows that there is only one pointer to a memory block, it can produce better optimized code. For instance:
void updatePtrs(size_t *ptrA, size_t *ptrB, size_t *val)
{
*ptrA += *val;
*ptrB += *val;
}
In the above code, the pointers ptrA, ptrB, and val might refer to the same memory location, so the compiler may generate less optimal code:
load R1 ← *val ; Fetch from memory the value at address val
load R2 ← *ptrA ; Fetch from memory the value at address ptrA
add R2 += R1 ; Perform addition
store R2 → *ptrA ; Update the value in memory location at ptrA
load R2 ← *ptrB ; 'load' may have to wait until preceding 'store' completes
load R1 ← *val ; Have to load a second time to ensure consistency
add R2 += R1
store R2 → *ptrB
However, if the restrict keyword is used and the above function is declared as
void updatePtrs(size_t *restrict ptrA, size_t *restrict ptrB, size_t *restrict val);
then the compiler is allowed to assume that ptrA, ptrB, and val point to different locations and updating one pointer will not affect the other pointers. The programmer, not the compiler, is responsible for ensuring that the pointers do not point to identical locations. The compiler can e.g. rearrange the code, first loading all memory locations, then performing the operations before committing the results back to memory.
load R1 ← *val ; Note that val is now only loaded once
load R2 ← *ptrA ; Also, all 'load's in the beginning ...
load R3 ← *ptrB
add R2 += R1
add R3 += R1
store R2 → *ptrA ; ... all 'store's in the end.
store R3 → *ptrB
The above assembly code is shorter because val is loaded only once. Also, since the compiler can rearrange the code more freely, the compiler can generate code that executes faster. In the second version of the above example, the store operations are all taking place after the loadoperations, ensuring that the processor won't have to block in the middle of the code to wait until the store operations are complete.
4. 把一些耗时的工作放在初始化时做,不要放在run time 做。比如第一点中的pRBpool, 我们在初始化的时候,cell id确定后,就可以推导出pRBpool里面的内容(0, 1, or 2).
5. 尽量让处理时间保持平稳, 不要在有些时候处理时间长,有的时候处理时间短, 这样有利于准确的去评估系统的性能。举个例子, 一个单元模块在某种条件下, 要花1ms做完, 另外条件下,要花100ms, 同时有很大的variance, 这样对于real-time系统来说是不可控的。当然, 比如说,对于不同的调制方式,qpsk, 16qam, 64qam, 那64qam的处理时间肯定比其他两个长, 那么,我们只需要保证,qpsk, 16qam, 64qam 的处理时间分别保持一致,qpsk 用100 cycles左右, 16qam用200cycles左右, 64qam用1000cycles 左右。如何做?比如说,
if (a == 0)
b = b * constant2 //一次操作
else
b = b * 2
b = b * constant2 // 两次操作
--------------------rewrite-----------------------
table = [1, 2]
idx=(a==0)?0:1;
b = b * table[idx]
b = b * const2
在上面的例子,重写之后,不管a是不是0,操作次数就固定住了,时间也就稳定了。 虽然多做些操作,但是当循环很多次时,便于编译器优化,速度其实会更快的,
table = [1, 2]
idx=(a==0)?0:1;
for(i=0;i<100000;i++){
b = b * table[idx]
b = b * const2
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号