HBase集群备份方法--Replication机制
1.简介
HBase备份的方法在HBase集群备份方法文章中已经有些介绍,但是这些方法都不是HBase本身的特性在支持,都是通过MR计算框架结合HBase客户端的方式,或者直接拷贝HBase的底层hdfs数据的方式进行备份的,但从操作上来说也比较繁琐复杂,数据完整性和及时性上也做的并不是很好。
本文介绍另外一种集群间的数据自动备份特性,这个特性是HBase的内部特性,用户数据备份和数据容灾和集群功能划分。
数据容灾可以认为只是为了数据的保存的措施,除此之外我们也可以灵活使用这种机制通常其能够适用于如下场景:
-
数据备份和容灾恢复
-
数据归集
-
数据地理分布
-
在线数据服务和线下数据分析
2.前准备
既然是集群间的备份那么我们至少需要准备两个HBase集群来进行试验,准备如下HBase集群。在测试环境上准备有两套HBase集群,资源有限原因他们共享一个hdfs集群和zookeeper,通过配置不同node路径和hdfs上数据路径来区别开。
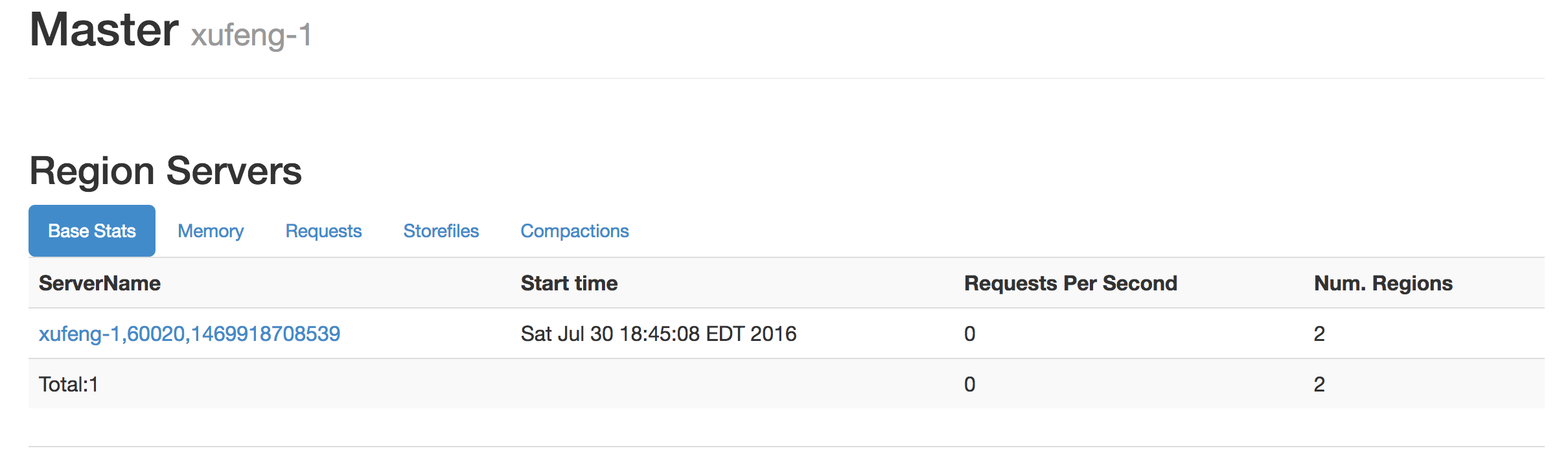
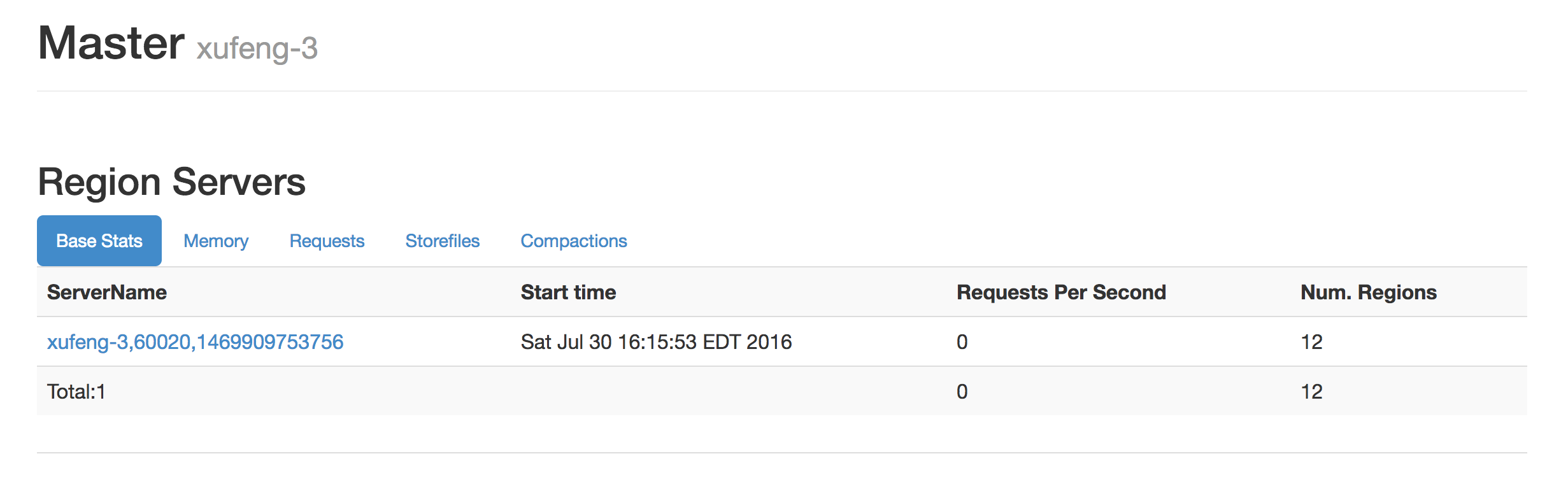

其中xufeng-3作为源集群,xufeng-1作为目标集群
1.集群间版本需要一致 2.集群间服务器需要互通 3.相关表及表结构在两个集群上存在且相同
3.启用Replication步骤
1. HBase默认此特性是关闭的,需要在集群上(所有集群)进行设定并重启集群,将hbase.replication参数设定为true
<property>
<name>hbase.replication</name>
<value>true</value>
</property>
2.在源集群上和目标集群上都新建表:
hbase(main):006:0> create 'replication_source_table','f1','f2'
0 row(s) in 0.3920 seconds
=> Hbase::Table - replication_source_table
3.在源集群的表上标注出需要备份的列族信息,如下将进行对于f1列族下数据的replication
hbase(main):008:0> alter 'replication_source_table',{NAME=>'f1', REPLICATION_SCOPE=>'1'}
Updating all regions with the new schema...
0/1 regions updated.
1/1 regions updated.
Done.
0 row(s) in 2.2830 seconds
4.现在设定需要向那个集群上replication数据,在hbase shell中执行命令。下面的命令指明了目标集群的zookeeper地址,以及它在这个zookeeper上路径,有了这些信息
相当于就知道了整个目标集群的信息。
hbase(main):010:0> add_peer '1',"xufeng-1:2181:/hbase_backup" 0 row(s) in 0.1220 seconds
5.通过shell命令可以看到目标集群已经被 添加到了源集群的replication中。
hbase(main):013:0> list_peers PEER_ID CLUSTER_KEY STATE TABLE_CFS 1 xufeng-1:2181:/hbase_backup ENABLED 1 row(s) in 0.0450 seconds
6.现在我们在步骤3上被作为replication的表上进行数据的插入
hbase(main):005:0> scan 'replication_source_table' ROW COLUMN+CELL row1 column=f1:a, timestamp=1469939791335, value=f1-a row2 column=f1:b, timestamp=1469939801684, value=f1-b row3 column=f2:a, timestamp=1469939814071, value=f2-a row4 column=f2:b, timestamp=1469939821430, value=f2-b 4 row(s) in 0.0610 seconds
7.查看xufeng-1的目标集群上的同名的表上是否有数据产生?
hbase(main):007:0> scan 'replication_source_table' ROW COLUMN+CELL row1 column=f1:a, timestamp=1469939791335, value=f1-a row2 column=f1:b, timestamp=1469939801684, value=f1-b 2 row(s) in 0.0340 seconds hbase(main):008:0>
可以看到源集群表上的f1列族下的数据都被replication到了目标集群的对应表中。(f2列族并没有设定replication的scope,所以不会被赋值)
8.进一步的我们在源集群表上删除一行row1行这个数据:
hbase(main):009:0> delete 'replication_source_table','row1','f1:a' 0 row(s) in 0.0200 seconds
查看对应的目标集群表数据,数据同样被删除
hbase(main):009:0> scan 'replication_source_table' ROW COLUMN+CELL row2 column=f1:b, timestamp=1469939801684, value=f1-b 1 row(s) in 0.0230 seconds
9.如果要停止对于某个集群的replication,可以执行disable_peer,同样的要想再次开启可使用enable_peer,更多关于使用方法可在hbase shell中的help中查看:
Group name: replication
Commands: add_peer, append_peer_tableCFs, disable_peer, enable_peer, list_peers, list_replicated_tables, remove_peer, remove_peer_tableCFs, set_peer_tableCFs, show_peer_tableCF
4.replication应用场景
数据容灾可以认为只是为了数据的保存的措施,除此之外我们也可以灵活使用这种机制通常其能够适用于如下场景:
-
数据备份和容灾恢复
-
数据归集
-
数据地理分布
-
在线数据服务和线下数据分析
多个集群间的互相备份可以形成集群间的拓扑结构:如下不同地域间的集群合一将数据放置到某个中心备份集群上,中心备份集群会将需要做分析的数据同步到数据分析集群,经过数据分析后将结果同步到其他业务集群上。

5.Replication原理
5.1 概要:
Replication是使用协处理器的Endpoint来实现的,基本原理是将源集群的regionserver会将WAL日志按顺序读取,并将WAL日志读取日志offset等信息通过zookeeper记录,读取之后主动的想目标集群的regionserver发送这些信息,在目标集群的regionserver接收到信息后会使用HTable客户端将这些信息插入的对应的表中。源集群的regionserver是endpoint的客户端,目标集群上的regionserver有endpoint的服务端实现,两者通过protobuf协议实现RPC通信,基于这一点所以需要集群间的版本一致,网络互通。
官方上给出的原理图如下:

对于Replication机制来说他是通过Endpint来时实现的,这一点从其源代码上既能看出:

对于其原理上来说官方的说明图并不清晰,这里我自己画了一个尝试去解释:
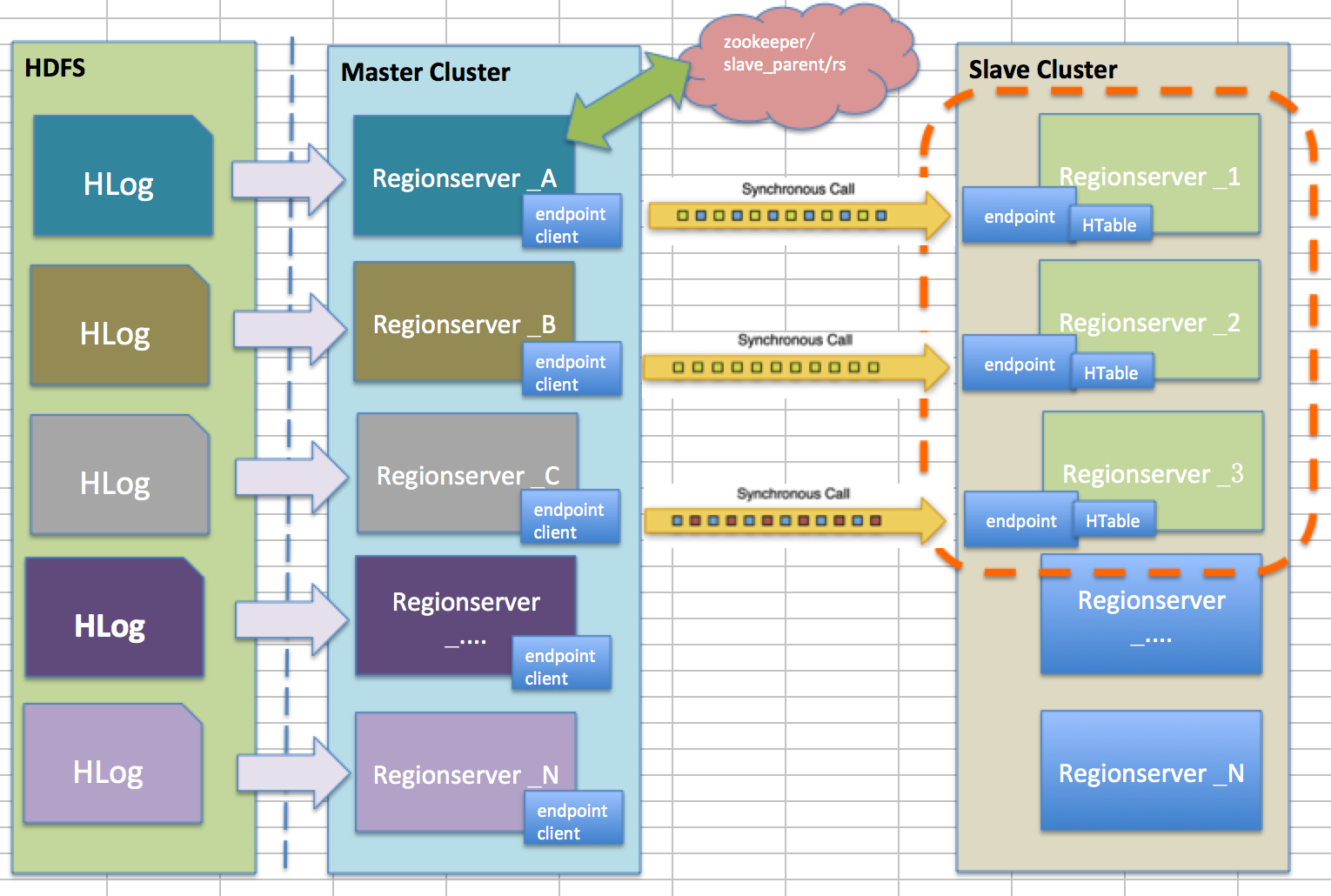
对于源集群上的Regionserver来说其自身就是Endpoint的客户端,她通过读取自己所持有的hlog日志(当其他机器死掉时候也会接管其他regionserver的hlog日志)然后同步调用rpc机制去向远端目标集群上的regionserver发送信息并等待相应,目标集群上并不是所有的regionserver都参与到接受信息的活动中,源集群会通过zookeeper来watch到目标集群上的所有rs信息然后根据比例(可配)的服务器个数来参与到replication中。目标集群上的regionserver的endpoint服务端接受到这些信息就会通过普通的htable客户端API进行数据的put,最后会返回结果给源集群的调用者,调用者会记录下hlog日志的offset信息保存。然后继续读取和发送。所以总体而言replication需要hlog作为数据源,解析hlog发送到远端regionserver,远端regionserver通过api将数据插入到对应表中去。
对于以上分为两部分,一部分是源集群是如何运行的,目标集群上是如何相应的来解释。
5.2 Replication机制
zookeeper节点介绍:
对于目标集群或者说slave集群来说,他是服务端,被动的接受来自客户端也就是源集群或者说master集群的请求,接受到请求后再包装成操作进行API的调用将数据插入到自身集群。
从这一点来看,主要工作都是master集群来完成的,前面也介绍replication机制是通过读取hlog来记性数据重建的。并且通过zookeeper来记录当前replication的进度,所以我们先看一下在zookeeper中是如何定义Replication的:

从上图可以看到/peers中记录着master集群要向哪些slave集群进行replication,并且知道某个slave集群上需要replication哪些表的那些列族信息。
/rs中节点记录着当前master集群的所有regionserver信息,每一个regionserver中又记录着这个regionserver上需要向哪些slave集群replication信息,并且知道向某个salve集群上那些hlog需要被replication,和当前某个hlog被replication的进度信息。
master集群regionserver的宕机处理:
master集群的每一个regionserver都会负责其所持有的hlog日志,但是当某台宕机之后会做什么处理呢?
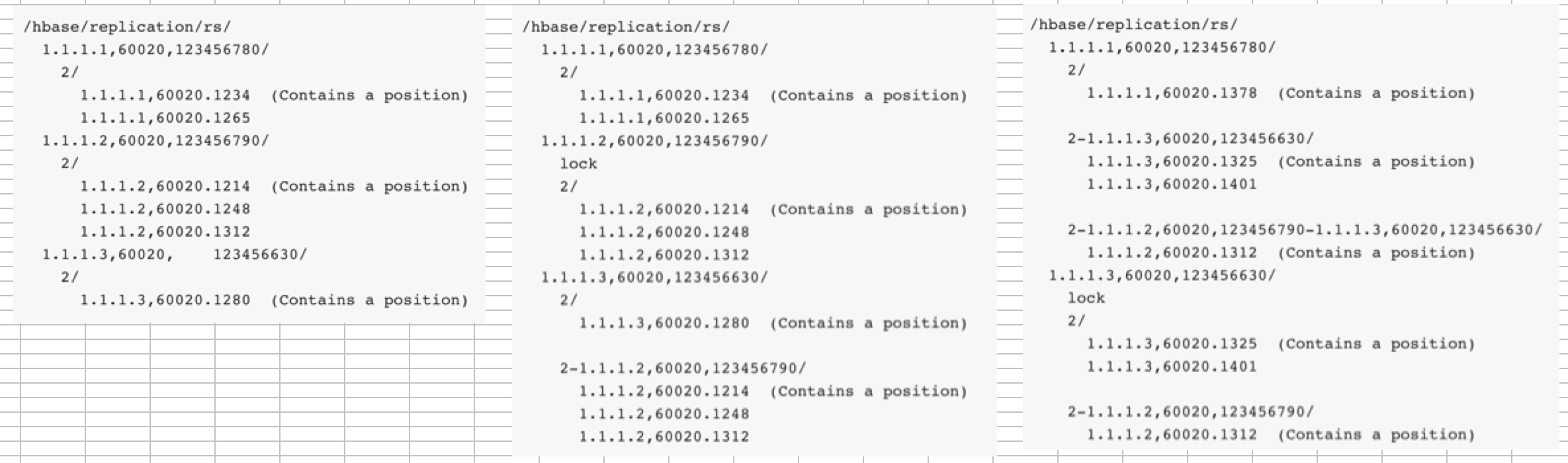
1. master集群上的regionserver都会通过zookeeper来相互watch。
2.当某台宕机后,其他rs会去其节点下抢注lock节点,如上图,1.1.1.2宕机,1.1.1.3注册到了lock节点,他会将1.1.1.2的信息赋值到其几点下,1.1.1.2的节点信息将会以peer_id-1.1.1.2rs信息为节点被写入1.1.1.3节点下,他会开启一个新线程去处理1.1.1.2的hlog信息。
3.但是如果1.1.1.3也宕机了,那么1.1.1.1最为最后的rs将会写入lock节点,然后按照同样的方式去处理。
master集群rs上hlog归档机制:
hlog会被RS进行归档,也就是说hlog的路径会被修改,当归档后,记录在zookeeper上的hlog节点信息会更新其路径,一般的:
1.当这个hlog文件还没有被replication被读取,那么会更新路径。
2.当hlog正在被replication读取中,则不会更新路径信息,因为hlog路径的改变只是一个namenode上逻辑信息的改变,既然已经在读取了,去块分布式不会被修改的。
3.只要master集群开启的replication机制,并且add了peer,那么即使这个peer是disable,hlog都不会被删除,而是需要等待replication对这些hlog读取完毕后才能被删除。
5.3 shell命令详解:
shell环境我们提供了很多方法去操作replication特性:
Group name: replication
Commands: add_peer, append_peer_tableCFs, disable_peer, enable_peer, list_peers, list_replicated_tables, remove_peer, remove_peer_tableCFs, set_peer_tableCFs, show_peer_tableCFs
add_peer:增加一个slave集群,一旦add那么master集群就会向这个slave集群上replication那些在master集群上表列族制定了REPLICATION_SCOPE=>'1'的信息。
add_peer '1','xufeng-1:2181:/hbase_backup'
list_peers:显示当前master集群一共向哪些集群进行replication
hbase(main):009:0> list_peers PEER_ID CLUSTER_KEY STATE TABLE_CFS 1 xufeng-1:2181:/hbase_backup ENABLED 1 row(s) in 0.0110 seconds
disable_peer:停止向某个slave集群进行replication
hbase(main):010:0> disable_peer '1' 0 row(s) in 0.0110 seconds hbase(main):011:0> list_peers PEER_ID CLUSTER_KEY STATE TABLE_CFS 1 xufeng-1:2181:/hbase_backup DISABLED 1 row(s) in 0.0070 seconds
enable_peer:与disable_peer意义相反
hbase(main):031:0> enable_peer '1' 0 row(s) in 0.0070 seconds hbase(main):032:0> list list list_labels list_namespace list_namespace_tables list_peers list_quotas list_replicated_tables list_snapshots hbase(main):032:0> list_peers PEER_ID CLUSTER_KEY STATE TABLE_CFS 1 xufeng-1:2181:/hbase_backup ENABLED 1 row(s) in 0.0080 seconds
set_peer_tableCFs:重写设定想slave集群replication哪些表的哪些列族,只对列族REPLICATION_SCOPE=>'1'有效
append_peer_tableCFs:与set_peer_tableCFs相比是增量设定,不会覆盖原有信息。
remove_peer_tableCFs:与append_peer_tableCFs操作相反。
list_replicated_tables:列出在master集群上所有设定为REPLICATION_SCOPE=>'1'的信息
hbase(main):065:0> list_replicated_tables TABLE:COLUMNFAMILY ReplicationType replication_source_table:f1 GLOBAL replication_source_table:f2 GLOBAL replication_test_table:f1 GLOBAL 3 row(s) in 0.0190 seconds
show_peer_tableCFs:观察某个slave集群上呗replication的表和列族信息
hbase(main):066:0> show_peer_tableCFs '1' replication_source_table:f1;replication_test_table:f1
5.4 注意点
1. 当replicaion不成功的时候回造成hlog日志积压。即使当前replication都disable状态。
2. replication不会根据实际插入的顺序来进行,只保证和master集群最终一致性。
3. 所有对于replication的shell操作,只对列族为REPLICATION_SCOPE=>'1'才有效。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号