Hadoop2.7.7_HA高可用部署
1. Hadoop的HA机制
前言:正式引入HA机制是从hadoop2.0开始,之前的版本中没有HA机制
1.1. HA的运作机制
(1)hadoop-HA集群运作机制介绍
所谓HA,即高可用(7*24小时不中断服务)
实现高可用最关键的是消除单点故障
hadoop-ha严格来说应该分成各个组件的HA机制——HDFS的HA、YARN的HA
(2)HDFS的HA机制详解
通过双namenode消除单点故障
双namenode协调工作的要点:
A、元数据管理方式需要改变:
内存中各自保存一份元数据
Edits日志只能有一份,只有Active状态的namenode节点可以做写操作
两个namenode都可以读取edits
共享的edits放在一个共享存储中管理(qjournal和NFS两个主流实现)
B、需要一个状态管理功能模块
实现了一个zkfailover,常驻在每一个namenode所在的节点
每一个zkfailover负责监控自己所在namenode节点,利用zk进行状态标识
当需要进行状态切换时,由zkfailover来负责切换
切换时需要防止brain split现象的发生
1.2. HDFS-HA图解

2. 主机规划
|
主机名称 |
外网IP |
内网IP |
操作系统 |
备注 |
安装软件 |
运行进程 |
|
mini01 |
10.0.0.111 |
172.16.1.111 |
CentOS 7.4 |
ssh port:22 |
jdk、hadoop |
NameNode、DFSZKFailoverController(zkfc) |
|
mini02 |
10.0.0.112 |
172.16.1.112 |
CentOS 7.4 |
ssh port:22 |
jdk、hadoop |
NameNode、DFSZKFailoverController(zkfc) |
|
mini03 |
10.0.0.113 |
172.16.1.113 |
CentOS 7.4 |
ssh port:22 |
jdk、hadoop、zookeeper |
ResourceManager |
|
mini04 |
10.0.0.114 |
172.16.1.114 |
CentOS 7.4 |
ssh port:22 |
jdk、hadoop、zookeeper |
ResourceManager |
|
mini05 |
10.0.0.115 |
172.16.1.115 |
CentOS 7.4 |
ssh port:22 |
jdk、hadoop、zookeeper |
DataNode、NodeManager、JournalNode、QuorumPeerMain |
|
mini06 |
10.0.0.116 |
172.16.1.116 |
CentOS 7.4 |
ssh port:22 |
jdk、hadoop、zookeeper |
DataNode、NodeManager、JournalNode、QuorumPeerMain |
|
mini07 |
10.0.0.117 |
172.16.1.117 |
CentOS 7.4 |
ssh port:22 |
jdk、hadoop、zookeeper |
DataNode、NodeManager、JournalNode、QuorumPeerMain |
|
1
|
注意:针对HA模式,就不需要SecondaryNameNode了,因为STANDBY状态的namenode会负责做checkpoint |
Linux添加hosts信息,保证每台都可以相互ping通

1 [root@mini01 ~]# cat /etc/hosts 2 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 3 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 4 5 10.0.0.111 mini01 6 10.0.0.112 mini02 7 10.0.0.113 mini03 8 10.0.0.114 mini04 9 10.0.0.115 mini05 10 10.0.0.116 mini06 11 10.0.0.117 mini07
Windows的hosts文件修改
1 # 文件位置C:\Windows\System32\drivers\etc 在hosts中追加如下内容 2 ………………………………………… 3 10.0.0.111 mini01 4 10.0.0.112 mini02 5 10.0.0.113 mini03 6 10.0.0.114 mini04 7 10.0.0.115 mini05 8 10.0.0.116 mini06 9 10.0.0.117 mini07
3. 添加用户账号
1 # 使用一个专门的用户,避免直接使用root用户 2 # 添加用户、指定家目录并指定用户密码 3 useradd -d /app yun && echo '123456' | /usr/bin/passwd --stdin yun 4 # sudo提权 5 echo "yun ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers 6 # 让其它普通用户可以进入该目录查看信息 7 chmod 755 /app/
4. 实现yun用户免秘钥登录
1 要求:根据规划实现 mini01 到 mini01、mini02、mini03、mini04、mini05、mini06、mini07 免秘钥登录 2 实现 mini02 到 mini01、mini02、mini03、mini04、mini05、mini06、mini07 免秘钥登录 3 实现 mini03 到 mini01、mini02、mini03、mini04、mini05、mini06、mini07 免秘钥登录 4 实现 mini04 到 mini01、mini02、mini03、mini04、mini05、mini06、mini07 免秘钥登录 5 实现 mini05 到 mini01、mini02、mini03、mini04、mini05、mini06、mini07 免秘钥登录 6 实现 mini06 到 mini01、mini02、mini03、mini04、mini05、mini06、mini07 免秘钥登录 7 实现 mini07 到 mini01、mini02、mini03、mini04、mini05、mini06、mini07 免秘钥登录 8 9 # 可以使用ip也可以是hostname 但是由于我们计划使用的是 hostname 方式交互,所以使用hostname 10 # 同时hostname方式分发,可以通过hostname远程登录,也可以IP远程登录
具体过程就不多说了,请参见 Hadoop2.7.6_01_部署
5. Jdk【java8】
具体过程就不多说了,请参见 Hadoop2.7.6_01_部署
6. Zookeeper部署
根据规划zookeeper部署在mini03、mini04、mini05、mini06、mini07上
6.1. 配置信息
1 [yun@mini03 conf]$ pwd 2 /app/zookeeper/conf 3 [yun@mini03 conf]$ vim zoo.cfg 4 #单个客户端与单台服务器之间的连接数的限制,是ip级别的,默认是60,如果设置为0,那么表明不作任何限制。 5 maxClientCnxns=1500 6 # The number of milliseconds of each tick 7 tickTime=2000 8 # The number of ticks that the initial 9 # synchronization phase can take 10 initLimit=10 11 # The number of ticks that can pass between 12 # sending a request and getting an acknowledgement 13 syncLimit=5 14 # the directory where the snapshot is stored. 15 # do not use /tmp for storage, /tmp here is just 16 # example sakes. 17 # dataDir=/tmp/zookeeper 18 dataDir=/app/bigdata/zookeeper/data 19 # the port at which the clients will connect 20 clientPort=2181 21 # 22 # Be sure to read the maintenance section of the 23 # administrator guide before turning on autopurge. 24 # 25 # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance 26 # 27 # The number of snapshots to retain in dataDir 28 #autopurge.snapRetainCount=3 29 # Purge task interval in hours 30 # Set to "0" to disable auto purge feature 31 #autopurge.purgeInterval=1 32 33 # leader和follow通信端口和投票选举端口 34 server.3=mini03:2888:3888 35 server.4=mini04:2888:3888 36 server.5=mini05:2888:3888 37 server.6=mini06:2888:3888 38 server.7=mini07:2888:3888
6.2. 添加myid文件
1 [yun@mini03 data]$ pwd 2 /app/bigdata/zookeeper/data 3 [yun@mini03 data]$ vim myid # 其中mini03的myid 为3;mini04的myid 为4;mini05的myid 为5;mini06的myid 为6;mini07的myid 为7 4 3
6.3. 启动zk服务
1 # 依次在启动mini03、mini04、mini05、mini06、mini07 zk服务 2 [yun@mini03 ~]$ cd zookeeper/bin/ 3 [yun@mini03 bin]$ pwd 4 /app/zookeeper/bin 5 [yun@mini03 bin]$ ll 6 total 56 7 -rwxr-xr-x 1 yun yun 238 Oct 1 2012 README.txt 8 -rwxr-xr-x 1 yun yun 1909 Oct 1 2012 zkCleanup.sh 9 -rwxr-xr-x 1 yun yun 1049 Oct 1 2012 zkCli.cmd 10 -rwxr-xr-x 1 yun yun 1512 Oct 1 2012 zkCli.sh 11 -rwxr-xr-x 1 yun yun 1333 Oct 1 2012 zkEnv.cmd 12 -rwxr-xr-x 1 yun yun 2599 Oct 1 2012 zkEnv.sh 13 -rwxr-xr-x 1 yun yun 1084 Oct 1 2012 zkServer.cmd 14 -rwxr-xr-x 1 yun yun 5467 Oct 1 2012 zkServer.sh 15 -rw-rw-r-- 1 yun yun 17522 Jun 28 21:01 zookeeper.out 16 [yun@mini03 bin]$ ./zkServer.sh start 17 JMX enabled by default 18 Using config: /app/zookeeper/bin/../conf/zoo.cfg 19 Starting zookeeper ... STARTED
6.4. 查询运行状态
1 # 其中mini03、mini04、mini06、mini07状态如下 2 [yun@mini03 bin]$ ./zkServer.sh status 3 JMX enabled by default 4 Using config: /app/zookeeper/bin/../conf/zoo.cfg 5 Mode: follower 6 7 # 其中mini05 状态如下 8 [yun@mini05 bin]$ ./zkServer.sh status 9 JMX enabled by default 10 Using config: /app/zookeeper/bin/../conf/zoo.cfg 11 Mode: leader
PS:4个follower 1个leader
7. Hadoop部署与配置修改
注意:每台机器的Hadoop以及配置相同
7.1. 部署
1 [yun@mini01 software]$ pwd 2 /app/software 3 [yun@mini01 software]$ ll 4 total 194152 5 -rw-r--r-- 1 yun yun 198811365 Jun 8 16:36 CentOS-7.4_hadoop-2.7.6.tar.gz 6 [yun@mini01 software]$ tar xf CentOS-7.4_hadoop-2.7.6.tar.gz 7 [yun@mini01 software]$ mv hadoop-2.7.6/ /app/ 8 [yun@mini01 software]$ cd 9 [yun@mini01 ~]$ ln -s hadoop-2.7.6/ hadoop 10 [yun@mini01 ~]$ ll 11 total 4 12 lrwxrwxrwx 1 yun yun 13 Jun 9 16:21 hadoop -> hadoop-2.7.6/ 13 drwxr-xr-x 9 yun yun 149 Jun 8 16:36 hadoop-2.7.6 14 lrwxrwxrwx 1 yun yun 12 May 26 11:18 jdk -> jdk1.8.0_112 15 drwxr-xr-x 8 yun yun 255 Sep 23 2016 jdk1.8.0_112
7.2. 环境变量
1 [root@mini01 profile.d]# pwd 2 /etc/profile.d 3 [root@mini01 profile.d]# vim hadoop.sh 4 export HADOOP_HOME="/app/hadoop" 5 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH 6 7 [root@mini01 profile.d]# source /etc/profile # 生效
7.3. core-site.xml
1 [yun@mini01 hadoop]$ pwd 2 /app/hadoop/etc/hadoop 3 [yun@mini01 hadoop]$ vim core-site.xml 4 <?xml version="1.0" encoding="UTF-8"?> 5 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> 6 <!-- 7 …………………… 8 --> 9 10 <!-- Put site-specific property overrides in this file. --> 11 12 <configuration> 13 <!-- 指定hdfs的nameservice为bi --> 14 <property> 15 <name>fs.defaultFS</name> 16 <value>hdfs://bi/</value> 17 </property> 18 19 <!-- 指定hadoop临时目录 --> 20 <property> 21 <name>hadoop.tmp.dir</name> 22 <value>/app/hadoop/tmp</value> 23 </property> 24 25 <!-- 指定zookeeper地址 --> 26 <property> 27 <name>ha.zookeeper.quorum</name> 28 <value>mini03:2181,mini04:2181,mini05:2181,mini06:2181,mini07:2181</value> 29 </property> 30 31 </configuration>
7.4. hdfs-site.xml
1 [yun@mini01 hadoop]$ pwd 2 /app/hadoop/etc/hadoop 3 [yun@mini01 hadoop]$ vim hdfs-site.xml 4 <?xml version="1.0" encoding="UTF-8"?> 5 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> 6 <!-- 7 …………………… 8 --> 9 10 <!-- Put site-specific property overrides in this file. --> 11 12 <configuration> 13 <!--指定hdfs的nameservice为bi,需要和core-site.xml中的保持一致 --> 14 <property> 15 <name>dfs.nameservices</name> 16 <value>bi</value> 17 </property> 18 19 <!-- bi下面有两个NameNode,分别是nn1,nn2 --> 20 <property> 21 <name>dfs.ha.namenodes.bi</name> 22 <value>nn1,nn2</value> 23 </property> 24 25 <!-- nn1的RPC通信地址 --> 26 <property> 27 <name>dfs.namenode.rpc-address.bi.nn1</name> 28 <value>mini01:9000</value> 29 </property> 30 <!-- nn1的http通信地址 --> 31 <property> 32 <name>dfs.namenode.http-address.bi.nn1</name> 33 <value>mini01:50070</value> 34 </property> 35 36 <!-- nn2的RPC通信地址 --> 37 <property> 38 <name>dfs.namenode.rpc-address.bi.nn2</name> 39 <value>mini02:9000</value> 40 </property> 41 <!-- nn2的http通信地址 --> 42 <property> 43 <name>dfs.namenode.http-address.bi.nn2</name> 44 <value>mini02:50070</value> 45 </property> 46 47 <!-- 指定NameNode的edits元数据在JournalNode上的存放位置 --> 48 <property> 49 <name>dfs.namenode.shared.edits.dir</name> 50 <value>qjournal://mini05:8485;mini06:8485;mini07:8485/bi</value> 51 </property> 52 53 <!-- 指定JournalNode在本地磁盘存放数据的位置 --> 54 <property> 55 <name>dfs.journalnode.edits.dir</name> 56 <value>/app/hadoop/journaldata</value> 57 </property> 58 59 <!-- 开启NameNode失败自动切换 --> 60 <property> 61 <name>dfs.ha.automatic-failover.enabled</name> 62 <value>true</value> 63 </property> 64 65 <!-- 配置失败自动切换实现方式 --> 66 <property> 67 <name>dfs.client.failover.proxy.provider.bi</name> 68 <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> 69 </property> 70 71 <!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行--> 72 <!-- 其中shell(/bin/true) 表示可执行一个脚本 比如 shell(/app/yunwei/hadoop_fence.sh) --> 73 <property> 74 <name>dfs.ha.fencing.methods</name> 75 <value> 76 sshfence 77 shell(/bin/true) 78 </value> 79 </property> 80 81 <!-- 使用sshfence隔离机制时需要ssh免登陆 --> 82 <property> 83 <name>dfs.ha.fencing.ssh.private-key-files</name> 84 <value>/app/.ssh/id_rsa</value> 85 </property> 86 87 <!-- 配置sshfence隔离机制超时时间 单位:毫秒 --> 88 <property> 89 <name>dfs.ha.fencing.ssh.connect-timeout</name> 90 <value>30000</value> 91 </property> 92 93 94 </configuration>
7.5. mapred-site.xml
1 [yun@mini01 hadoop]$ pwd 2 /app/hadoop/etc/hadoop 3 [yun@mini01 hadoop]$ cp -a mapred-site.xml.template mapred-site.xml 4 [yun@mini01 hadoop]$ vim mapred-site.xml 5 <?xml version="1.0"?> 6 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> 7 <!-- 8 …………………… 9 --> 10 11 <!-- Put site-specific property overrides in this file. --> 12 13 <configuration> 14 <!-- 指定mr框架为yarn方式 --> 15 <property> 16 <name>mapreduce.framework.name</name> 17 <value>yarn</value> 18 </property> 19 20 </configuration>
7.6. yarn-site.xml
1 [yun@mini01 hadoop]$ pwd 2 /app/hadoop/etc/hadoop 3 [yun@mini01 hadoop]$ vim yarn-site.xml 4 <?xml version="1.0"?> 5 <!-- 6 …………………… 7 --> 8 <configuration> 9 10 <!-- Site specific YARN configuration properties --> 11 <!-- 开启RM高可用 --> 12 <property> 13 <name>yarn.resourcemanager.ha.enabled</name> 14 <value>true</value> 15 </property> 16 17 <!-- 指定RM的cluster id --> 18 <property> 19 <name>yarn.resourcemanager.cluster-id</name> 20 <value>yrc</value> 21 </property> 22 23 <!-- 指定RM的名字 --> 24 <property> 25 <name>yarn.resourcemanager.ha.rm-ids</name> 26 <value>rm1,rm2</value> 27 </property> 28 29 <!-- 分别指定RM的地址 --> 30 <property> 31 <name>yarn.resourcemanager.hostname.rm1</name> 32 <value>mini03</value> 33 </property> 34 <property> 35 <name>yarn.resourcemanager.hostname.rm2</name> 36 <value>mini04</value> 37 </property> 38 39 <!-- 指定zk集群地址 --> 40 <property> 41 <name>yarn.resourcemanager.zk-address</name> 42 <value>mini03:2181,mini04:2181,mini05:2181,mini06:2181,mini07:2181</value> 43 </property> 44 45 <!-- reduce 获取数据的方式 --> 46 <property> 47 <name>yarn.nodemanager.aux-services</name> 48 <value>mapreduce_shuffle</value> 49 </property> 50 51 52 </configuration>
7.7. 修改slaves
slaves是指定子节点的位置,因为要在mini01上启动HDFS、在mini03启动yarn,所以mini01上的slaves文件指定的是datanode的位置,mini03上的slaves文件指定的是nodemanager的位置
1 [yun@mini01 hadoop]$ pwd 2 /app/hadoop/etc/hadoop 3 [yun@mini01 hadoop]$ vim slaves 4 mini05 5 mini06 6 mini07
PS:改后配置后,将这些配置拷到其他Hadoop机器
8. 启动相关服务
注意:第一次启动时严格按照下面的步骤!!!!!!!
8.1. 启动zookeeper集群
前面已经启动了,这里就不说了
8.2. 启动journalnode
1 # 根据规划在mini05、mini06、mini07 启动 2 # 在第一次格式化的时候需要先启动journalnode 之后就不必了 3 [yun@mini05 ~]$ hadoop-daemon.sh start journalnode # 已经配置环境变量,所以不用进入到响应的目录 4 starting journalnode, logging to /app/hadoop-2.7.6/logs/hadoop-yun-journalnode-mini05.out 5 [yun@mini05 ~]$ jps 6 1281 QuorumPeerMain 7 1817 Jps 8 1759 JournalNode
8.3. 格式化HDFS
1 # 在mini01上执行命令 2 [yun@mini01 ~]$ hdfs namenode -format 3 18/06/30 18:29:12 INFO namenode.NameNode: STARTUP_MSG: 4 /************************************************************ 5 STARTUP_MSG: Starting NameNode 6 STARTUP_MSG: host = mini01/10.0.0.111 7 STARTUP_MSG: args = [-format] 8 STARTUP_MSG: version = 2.7.6 9 STARTUP_MSG: classpath = ……………… 10 STARTUP_MSG: build = Unknown -r Unknown; compiled by 'root' on 2018-06-08T08:30Z 11 STARTUP_MSG: java = 1.8.0_112 12 ************************************************************/ 13 18/06/30 18:29:12 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT] 14 18/06/30 18:29:12 INFO namenode.NameNode: createNameNode [-format] 15 Formatting using clusterid: CID-2385f26e-72e6-4935-aa09-47848b5ba4be 16 18/06/30 18:29:13 INFO namenode.FSNamesystem: No KeyProvider found. 17 18/06/30 18:29:13 INFO namenode.FSNamesystem: fsLock is fair: true 18 18/06/30 18:29:13 INFO namenode.FSNamesystem: Detailed lock hold time metrics enabled: false 19 18/06/30 18:29:13 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit=1000 20 18/06/30 18:29:13 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true 21 18/06/30 18:29:13 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000 22 18/06/30 18:29:13 INFO blockmanagement.BlockManager: The block deletion will start around 2018 Jun 30 18:29:13 23 18/06/30 18:29:13 INFO util.GSet: Computing capacity for map BlocksMap 24 18/06/30 18:29:13 INFO util.GSet: VM type = 64-bit 25 18/06/30 18:29:13 INFO util.GSet: 2.0% max memory 966.7 MB = 19.3 MB 26 18/06/30 18:29:13 INFO util.GSet: capacity = 2^21 = 2097152 entries 27 18/06/30 18:29:13 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false 28 18/06/30 18:29:13 INFO blockmanagement.BlockManager: defaultReplication = 3 29 18/06/30 18:29:13 INFO blockmanagement.BlockManager: maxReplication = 512 30 18/06/30 18:29:13 INFO blockmanagement.BlockManager: minReplication = 1 31 18/06/30 18:29:13 INFO blockmanagement.BlockManager: maxReplicationStreams = 2 32 18/06/30 18:29:13 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000 33 18/06/30 18:29:13 INFO blockmanagement.BlockManager: encryptDataTransfer = false 34 18/06/30 18:29:13 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000 35 18/06/30 18:29:13 INFO namenode.FSNamesystem: fsOwner = yun (auth:SIMPLE) 36 18/06/30 18:29:13 INFO namenode.FSNamesystem: supergroup = supergroup 37 18/06/30 18:29:13 INFO namenode.FSNamesystem: isPermissionEnabled = true 38 18/06/30 18:29:13 INFO namenode.FSNamesystem: Determined nameservice ID: bi 39 18/06/30 18:29:13 INFO namenode.FSNamesystem: HA Enabled: true 40 18/06/30 18:29:13 INFO namenode.FSNamesystem: Append Enabled: true 41 18/06/30 18:29:13 INFO util.GSet: Computing capacity for map INodeMap 42 18/06/30 18:29:13 INFO util.GSet: VM type = 64-bit 43 18/06/30 18:29:13 INFO util.GSet: 1.0% max memory 966.7 MB = 9.7 MB 44 18/06/30 18:29:13 INFO util.GSet: capacity = 2^20 = 1048576 entries 45 18/06/30 18:29:13 INFO namenode.FSDirectory: ACLs enabled? false 46 18/06/30 18:29:13 INFO namenode.FSDirectory: XAttrs enabled? true 47 18/06/30 18:29:13 INFO namenode.FSDirectory: Maximum size of an xattr: 16384 48 18/06/30 18:29:13 INFO namenode.NameNode: Caching file names occuring more than 10 times 49 18/06/30 18:29:13 INFO util.GSet: Computing capacity for map cachedBlocks 50 18/06/30 18:29:13 INFO util.GSet: VM type = 64-bit 51 18/06/30 18:29:13 INFO util.GSet: 0.25% max memory 966.7 MB = 2.4 MB 52 18/06/30 18:29:13 INFO util.GSet: capacity = 2^18 = 262144 entries 53 18/06/30 18:29:13 INFO namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033 54 18/06/30 18:29:13 INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0 55 18/06/30 18:29:13 INFO namenode.FSNamesystem: dfs.namenode.safemode.extension = 30000 56 18/06/30 18:29:13 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10 57 18/06/30 18:29:13 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10 58 18/06/30 18:29:13 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25 59 18/06/30 18:29:13 INFO namenode.FSNamesystem: Retry cache on namenode is enabled 60 18/06/30 18:29:13 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis 61 18/06/30 18:29:13 INFO util.GSet: Computing capacity for map NameNodeRetryCache 62 18/06/30 18:29:13 INFO util.GSet: VM type = 64-bit 63 18/06/30 18:29:13 INFO util.GSet: 0.029999999329447746% max memory 966.7 MB = 297.0 KB 64 18/06/30 18:29:13 INFO util.GSet: capacity = 2^15 = 32768 entries 65 18/06/30 18:29:14 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1178102935-10.0.0.111-1530354554626 66 18/06/30 18:29:14 INFO common.Storage: Storage directory /app/hadoop/tmp/dfs/name has been successfully formatted. 67 18/06/30 18:29:14 INFO namenode.FSImageFormatProtobuf: Saving image file /app/hadoop/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression 68 18/06/30 18:29:14 INFO namenode.FSImageFormatProtobuf: Image file /app/hadoop/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 320 bytes saved in 0 seconds. 69 18/06/30 18:29:15 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 70 18/06/30 18:29:15 INFO util.ExitUtil: Exiting with status 0 71 18/06/30 18:29:15 INFO namenode.NameNode: SHUTDOWN_MSG: 72 /************************************************************ 73 SHUTDOWN_MSG: Shutting down NameNode at mini01/10.0.0.111 74 ************************************************************/
拷贝到mini02
1 #格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,这里我配置的是/app/hadoop/tmp,然后将/app/hadoop/tmp拷贝到mini02的/app/hadoop/下。 2 # 方法1: 3 [yun@mini01 hadoop]$ pwd 4 /app/hadoop 5 [yun@mini01 hadoop]$ scp -r tmp/ yun@mini02:/app/hadoop 6 VERSION 100% 202 189.4KB/s 00:00 7 seen_txid 100% 2 1.0KB/s 00:00 8 fsimage_0000000000000000000.md5 100% 62 39.7KB/s 00:00 9 fsimage_0000000000000000000 100% 320 156.1KB/s 00:00 10 11 ##########################3 12 # 方法2:##也可以这样,建议hdfs namenode -bootstrapStandby # 不过需要mini02的Hadoop起来才行
8.4. 格式化ZKFC
1 #在mini01上执行一次即可 2 [yun@mini01 ~]$ hdfs zkfc -formatZK 3 18/06/30 18:54:30 INFO tools.DFSZKFailoverController: Failover controller configured for NameNode NameNode at mini01/10.0.0.111:9000 4 18/06/30 18:54:30 INFO zookeeper.ZooKeeper: Client environment:zookeeper.version=3.4.6-1569965, built on 02/20/2014 09:09 GMT 5 18/06/30 18:54:30 INFO zookeeper.ZooKeeper: Client environment:host.name=mini01 6 18/06/30 18:54:30 INFO zookeeper.ZooKeeper: Client environment:java.version=1.8.0_112 7 18/06/30 18:54:30 INFO zookeeper.ZooKeeper: Client environment:java.vendor=Oracle Corporation 8 18/06/30 18:54:30 INFO zookeeper.ZooKeeper: Client environment:java.home=/app/jdk1.8.0_112/jre 9 18/06/30 18:54:30 INFO zookeeper.ZooKeeper: Client environment:java.class.path=…………………… 10 18/06/30 18:54:30 INFO zookeeper.ZooKeeper: Client environment:java.library.path=/app/hadoop-2.7.6/lib/native 11 18/06/30 18:54:30 INFO zookeeper.ZooKeeper: Client environment:java.io.tmpdir=/tmp 12 18/06/30 18:54:30 INFO zookeeper.ZooKeeper: Client environment:java.compiler=<NA> 13 18/06/30 18:54:30 INFO zookeeper.ZooKeeper: Client environment:os.name=Linux 14 18/06/30 18:54:30 INFO zookeeper.ZooKeeper: Client environment:os.arch=amd64 15 18/06/30 18:54:30 INFO zookeeper.ZooKeeper: Client environment:os.version=3.10.0-693.el7.x86_64 16 18/06/30 18:54:30 INFO zookeeper.ZooKeeper: Client environment:user.name=yun 17 18/06/30 18:54:30 INFO zookeeper.ZooKeeper: Client environment:user.home=/app 18 18/06/30 18:54:30 INFO zookeeper.ZooKeeper: Client environment:user.dir=/app/hadoop-2.7.6 19 18/06/30 18:54:30 INFO zookeeper.ZooKeeper: Initiating client connection, connectString=mini03:2181,mini04:2181,mini05:2181,mini06:2181,mini07:2181 sessionTimeout=5000 watcher=org.apache.hadoop.ha.ActiveStandbyElector$WatcherWithClientRef@7f3b84b8 20 18/06/30 18:54:30 INFO zookeeper.ClientCnxn: Opening socket connection to server mini04/10.0.0.114:2181. Will not attempt to authenticate using SASL (unknown error) 21 18/06/30 18:54:30 INFO zookeeper.ClientCnxn: Socket connection established to mini04/10.0.0.114:2181, initiating session 22 18/06/30 18:54:30 INFO zookeeper.ClientCnxn: Session establishment complete on server mini04/10.0.0.114:2181, sessionid = 0x4644fff9cb80000, negotiated timeout = 5000 23 18/06/30 18:54:30 INFO ha.ActiveStandbyElector: Session connected. 24 18/06/30 18:54:30 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/bi in ZK. 25 18/06/30 18:54:30 INFO zookeeper.ZooKeeper: Session: 0x4644fff9cb80000 closed 26 18/06/30 18:54:30 INFO zookeeper.ClientCnxn: EventThread shut down
8.5. 启动HDFS
1 # 在mini01上执行 2 [yun@mini01 ~]$ start-dfs.sh 3 Starting namenodes on [mini01 mini02] 4 mini01: starting namenode, logging to /app/hadoop-2.7.6/logs/hadoop-yun-namenode-mini01.out 5 mini02: starting namenode, logging to /app/hadoop-2.7.6/logs/hadoop-yun-namenode-mini02.out 6 mini07: starting datanode, logging to /app/hadoop-2.7.6/logs/hadoop-yun-datanode-mini07.out 7 mini06: starting datanode, logging to /app/hadoop-2.7.6/logs/hadoop-yun-datanode-mini06.out 8 mini05: starting datanode, logging to /app/hadoop-2.7.6/logs/hadoop-yun-datanode-mini05.out 9 Starting journal nodes [mini05 mini06 mini07] 10 mini07: journalnode running as process 1691. Stop it first. 11 mini06: journalnode running as process 1665. Stop it first. 12 mini05: journalnode running as process 1759. Stop it first. 13 Starting ZK Failover Controllers on NN hosts [mini01 mini02] 14 mini01: starting zkfc, logging to /app/hadoop-2.7.6/logs/hadoop-yun-zkfc-mini01.out 15 mini02: starting zkfc, logging to /app/hadoop-2.7.6/logs/hadoop-yun-zkfc-mini02.out
8.6. 启动YARN
1 #####注意#####:是在mini03上执行start-yarn.sh,把namenode和resourcemanager分开是因为性能问题 2 # 因为他们都要占用大量资源,所以把他们分开了,他们分开了就要分别在不同的机器上启动 3 [yun@mini03 ~]$ start-yarn.sh 4 starting yarn daemons 5 starting resourcemanager, logging to /app/hadoop-2.7.6/logs/yarn-yun-resourcemanager-mini03.out 6 mini06: starting nodemanager, logging to /app/hadoop-2.7.6/logs/yarn-yun-nodemanager-mini06.out 7 mini07: starting nodemanager, logging to /app/hadoop-2.7.6/logs/yarn-yun-nodemanager-mini07.out 8 mini05: starting nodemanager, logging to /app/hadoop-2.7.6/logs/yarn-yun-nodemanager-mini05.out 9 10 11 ################################ 12 # 在mini04启动 resourcemanager 13 [yun@mini04 ~]$ yarn-daemon.sh start resourcemanager # 也可用start-yarn.sh 14 starting resourcemanager, logging to /app/hadoop-2.7.6/logs/yarn-yun-resourcemanager-mini04.out
8.7. 启动说明
1 # 第一次启动的时候请严格按照上面的步骤【第一次涉及格式化问题】 2 # 第二次以及之后,步骤为: 启动zookeeper、HDFS、YARN
9. 浏览访问
9.1. Hdfs访问
9.1.1. 正常情况访问
1 http://mini01:50070
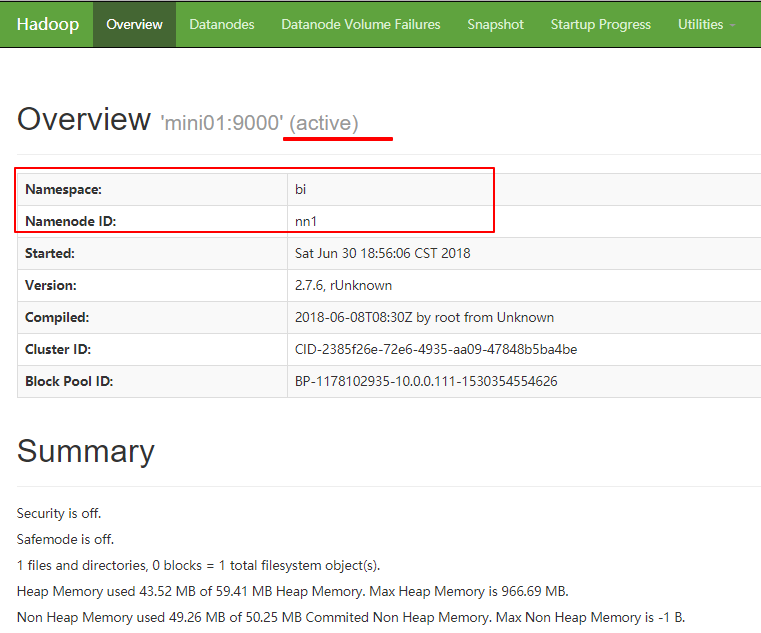
1 http://mini02:50070
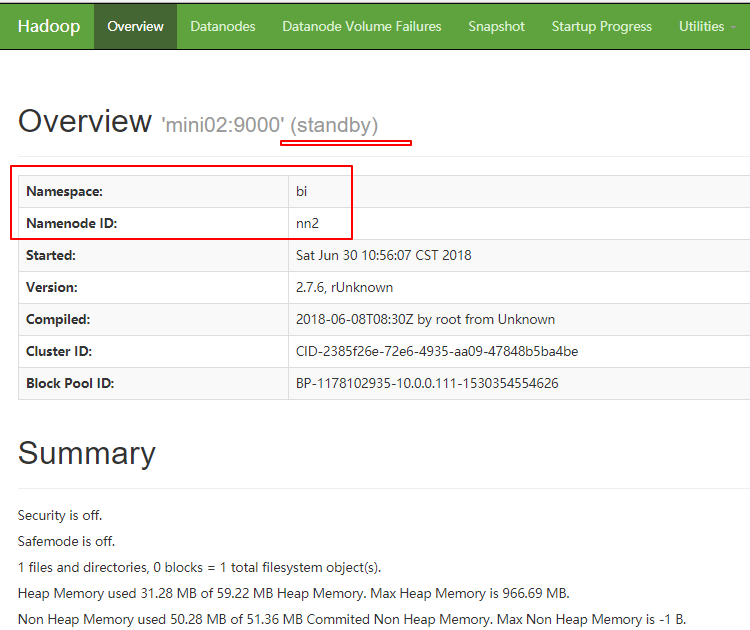
9.1.2. mini01挂了Active自动切换
1 # mini01操作 2 [yun@mini01 ~]$ jps 3 3584 DFSZKFailoverController 4 3283 NameNode 5 5831 Jps 6 [yun@mini01 ~]$ kill 3283 7 [yun@mini01 ~]$ jps 8 3584 DFSZKFailoverController 9 5893 Jps
Namenode挂了所以mini01不能访问
1 http://mini02:50070
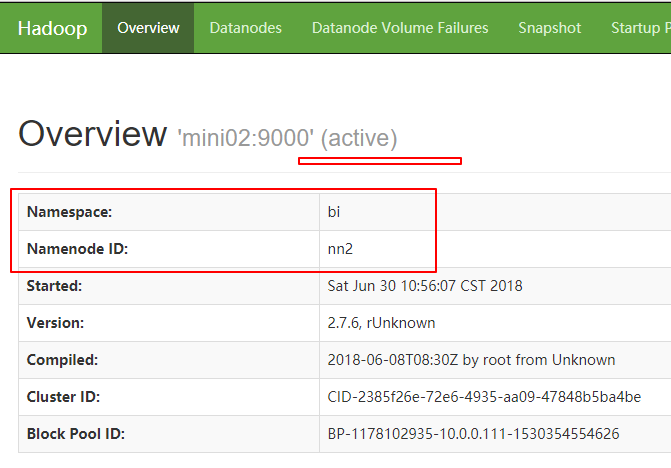
可见Hadoop已经切换过去了,之后mini01即使起来了,状态也只能为standby 。
9.2. Yarn访问
1 http://mini03:8088
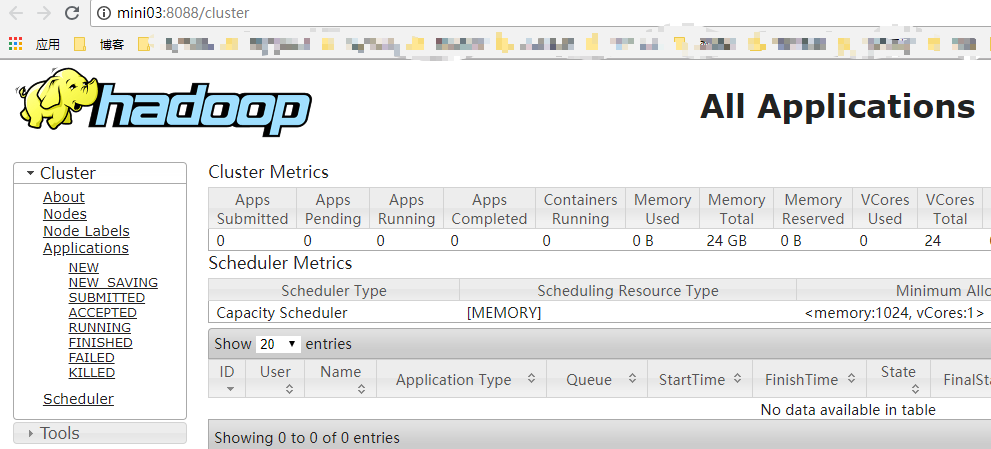
1 http://mini04:8088 2 会直接跳转到http://mini03:8088/

# 该图从其他地方截取,所以不怎么匹配
1 # Linux下访问 2 [yun@mini01 ~]$ curl mini04:8088 3 This is standby RM. The redirect url is: http://mini03:8088/
HA完毕
10. 集群运维测试
10.1. Haadmin与状态切换管理
1 [yun@mini01 ~]$ hdfs haadmin 2 Usage: haadmin 3 [-transitionToActive [--forceactive] <serviceId>] 4 [-transitionToStandby <serviceId>] 5 [-failover [--forcefence] [--forceactive] <serviceId> <serviceId>] 6 [-getServiceState <serviceId>] 7 [-checkHealth <serviceId>] 8 [-help <command>] 9 10 Generic options supported are 11 -conf <configuration file> specify an application configuration file 12 -D <property=value> use value for given property 13 -fs <local|namenode:port> specify a namenode 14 -jt <local|resourcemanager:port> specify a ResourceManager 15 -files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster 16 -libjars <comma separated list of jars> specify comma separated jar files to include in the classpath. 17 -archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines. 18 19 The general command line syntax is 20 bin/hadoop command [genericOptions] [commandOptions]
可以看到,状态操作的命令示例:
1 # 查看namenode工作状态 2 hdfs haadmin -getServiceState nn1 3 4 # 将standby状态namenode切换到active 5 hdfs haadmin -transitionToActive nn1 6 7 # 将active状态namenode切换到standby 8 hdfs haadmin -transitionToStandby nn2
10.2. 测试集群工作状态的一些指令
1 测试集群工作状态的一些指令 : 2 hdfs dfsadmin -report 查看hdfs的各节点状态信息 3 hdfs haadmin -getServiceState nn1 # hdfs haadmin -getServiceState nn2 获取一个namenode节点的HA状态 4 hadoop-daemon.sh start namenode 单独启动一个namenode进程 5 hadoop-daemon.sh start zkfc 单独启动一个zkfc进程
10.3. Datanode动态上下线
Datanode动态上下线很简单,步骤如下:
a) 准备一台服务器,设置好环境
b) 部署hadoop的安装包,并同步集群配置
c) 联网上线,新datanode会自动加入集群
d) 如果是一次增加大批datanode,还应该做集群负载重均衡
10.4. 数据块的balance
启动balancer的命令:
1 start-balancer.sh -threshold 8
运行之后,会有Balancer进程出现:
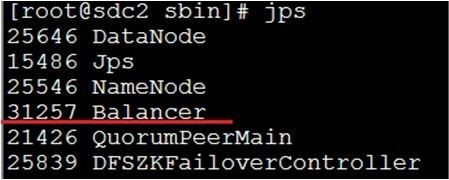
上述命令设置了Threshold为8%,那么执行balancer命令的时候,首先统计所有DataNode的磁盘利用率的均值,然后判断如果某一个DataNode的磁盘利用率超过这个均值Threshold,那么将会把这个DataNode的block转移到磁盘利用率低的DataNode,这对于新节点的加入来说十分有用。Threshold的值为1到100之间,不显示的进行参数设置的话,默认是10。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号