监听MySQL的binlog日志工具分析:Canal
Canal是阿里巴巴旗下的一款开源项目,利用Java开发。主要用途是基于MySQL数据库增量日志解析,提供增量数据订阅和消费,目前主要支持MySQL。
GitHub地址:https://github.com/alibaba/canal

在介绍Canal内部原理之前,首先来了解一下MySQL Master/Slave同步原理:
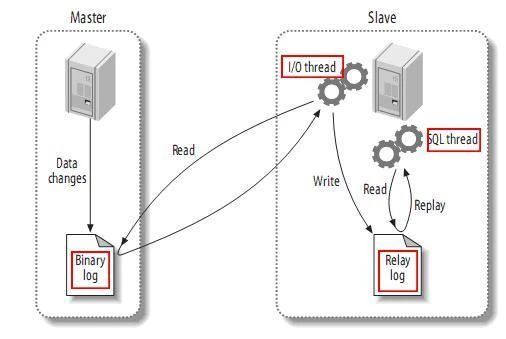
- MySQL master启动binlog机制,将数据变更写入二进制日志(binary log, 其中记录叫做二进制日志事件binary log events,可以通过show binlog events进行查看)
- MySQL slave(I/O thread)将master的binary log events拷贝到它的中继日志(relay log)
- MySQL slave(SQL thread)重放relay log中事件,将数据变更反映它自己的数据中
Canal工作原理:
- Canal模拟MySQL slave的交互协议,伪装自己为MySQL slave,向MySQL master发送dump协议
- MySQL master收到dump请求,开始推送binary log给slave(也就是canal)
- Canal解析binary log对象(原始为byte流)
简而言之,Canal是通过模拟成为MySQL的slave,监听MySQL的binlog日志来获取数据。当把MySQL的binlog设置为row模式以后,可以获取到执行的每一个Insert/Update/Delete的脚本,以及修改前和修改后的数据,基于这个特性,Canal就能高效的获取到MySQL数据的变更。
Canal架构:
说明:
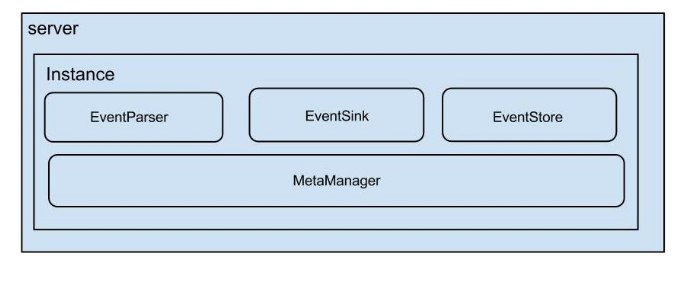
server代表一个Canal运行实例,对应于一个jvm
instance对应于一个数据队列(1个server对应1..n个instance)

EventParser:数据源接入,模拟slave协议和master进行交互,协议解析
EventSink:Parser和Store连接器,主要进行数据过滤,加工,分发的工作
EventStore:负责存储
MemoryMetaManager:增量订阅和消费信息管理器
Event Parser设计:
整个parser过程大致可分为以下几步:
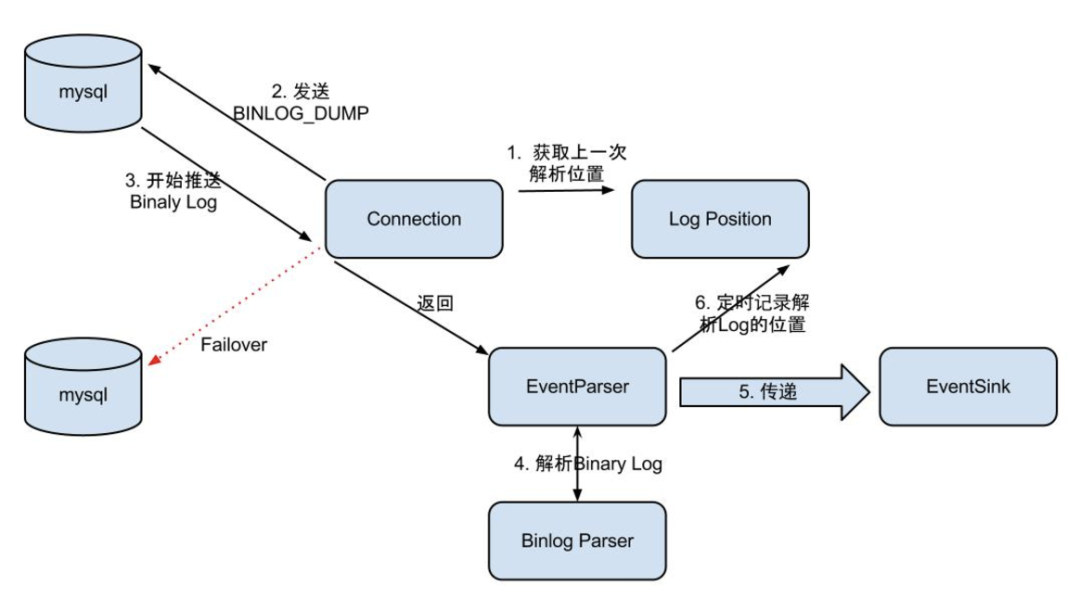
- Connection获取上一次解析成功的log position(如果是第一次启动,则获取初始指定的位置或者是当前数据库的binlog log position)
- Connection建立连接,向MySQL master发送BINLOG_DUMP请求
- MySQL开始推送binary Log接收到的binary Log
- 通过BinlogParser进行协议解析,补充一些特定信息。如补充字段名字、字段类型、主键信息、unsigned类型处理等
- 将解析后的数据传入到EventSink组件进行数据存储(这是一个阻塞操作,直到存储成功)
- 定时记录binary Log位置,以便重启后继续进行增量订阅
如果需要同步的master宕机,可以从它的其他slave节点继续同步binlog日志,避免单点故障。
Event Sink设计:
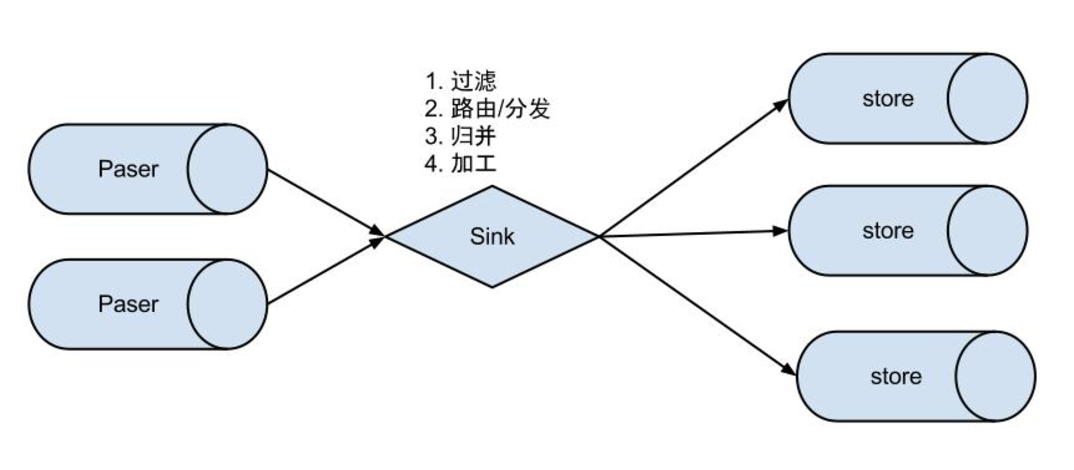
EventSink主要作用如下:
数据过滤:支持通配符的过滤模式,表名,字段内容等
数据路由/分发:解决1:n(1个parser对应多个store的模式)
数据归并:解决n:1(多个parser对应1个store)
数据加工:在进入store之前进行额外的处理,比如join
数据1:n业务
为了合理的利用数据库资源, 一般常见的业务都是按照schema进行隔离,然后在MySQL上层或者dao这一层面上,进行一个数据源路由,屏蔽数据库物理位置对开发的影响,阿里系主要是通过cobar/tddl来解决数据源路由问题。所以,一般一个数据库实例上,会部署多个schema,每个schema会有由1个或者多个业务方关注。
数据n:1业务
同样,当一个业务的数据规模达到一定的量级后,必然会涉及到水平拆分和垂直拆分的问题,针对这些拆分的数据需要处理时,就需要链接多个store进行处理,消费的位点就会变成多份,而且数据消费的进度无法得到尽可能有序的保证。所以,在一定业务场景下,需要将拆分后的增量数据进行归并处理,比如按照时间戳/全局id进行排序归并。
Event Store设计:
支持多种存储模式,比如Memory内存模式。采用内存环装的设计来保存消息,借鉴了Disruptor的RingBuffer的实现思路。
RingBuffer设计:
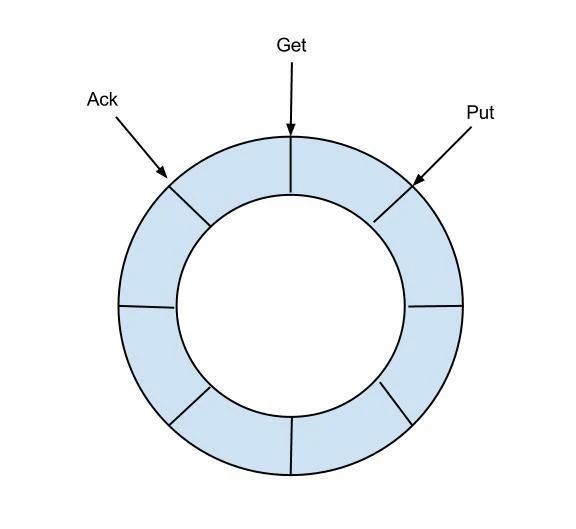
定义了3个cursor:
put:Sink模块进行数据存储的最后一次写入位置(同步写入数据的cursor)
get:数据订阅获取的最后一次提取位置(同步获取的数据的cursor)
ack:数据消费成功的最后一次消费位置
借鉴Disruptor的RingBuffer的实现,将RingBuffer拉直来看:
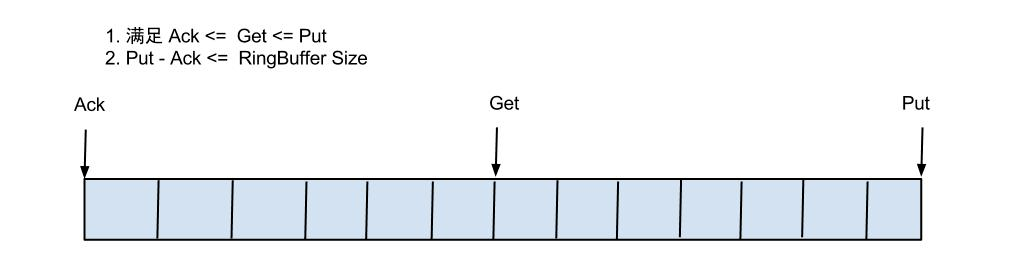
实现说明:
- put/get/ack cursor用于递增,采用long型存储。三者之间的关系为put>=get>=ack
- buffer的get操作,通过取余或者&操作。(&操作:cusor & (size - 1) , size需要为2的指数,效率比较高)
Instance设计:
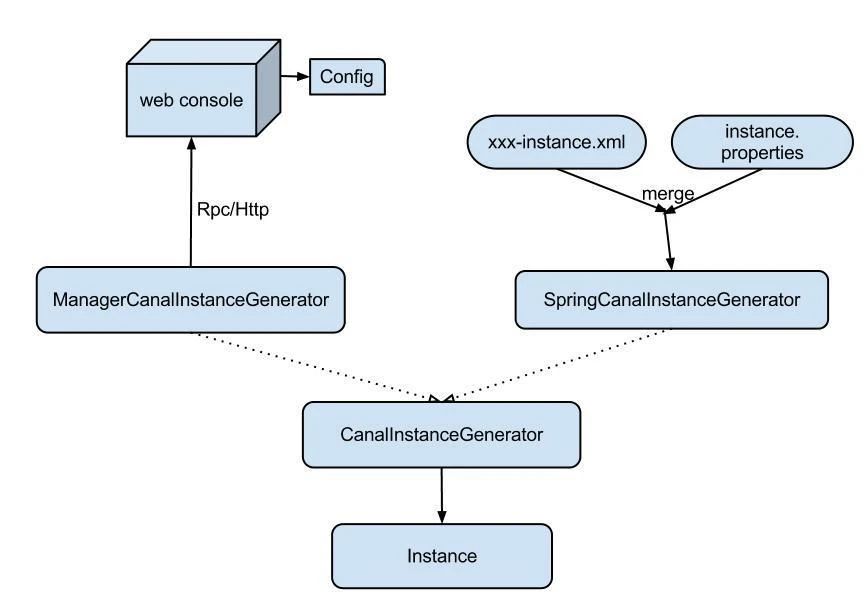
instance代表了一个实际运行的数据队列,包括了EventPaser、EventSink、EventStore等组件。抽象了CanalInstanceGenerator,主要是考虑配置的管理方式:
manager方式:和你自己的内部web console/manager系统进行对接。(目前主要是公司内部使用)
spring方式:基于spring xml + properties进行定义,构建spring配置。
Server设计:
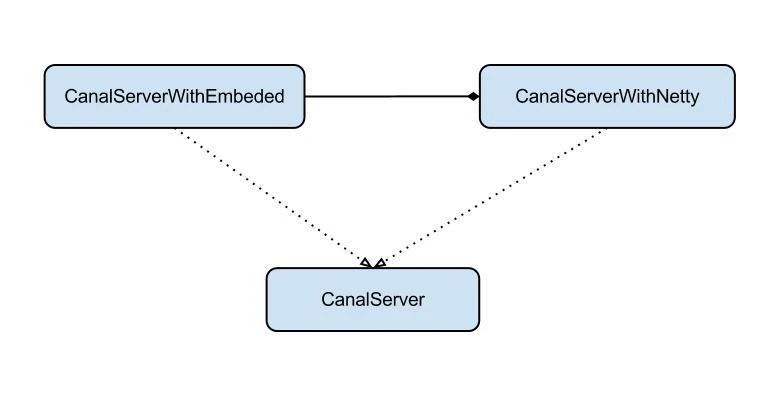
server代表了一个Canal运行实例,为了方便组件化使用,特意抽象了Embeded(嵌入式)/Netty(网络访问)的两种实现。
增量订阅/消费设计:
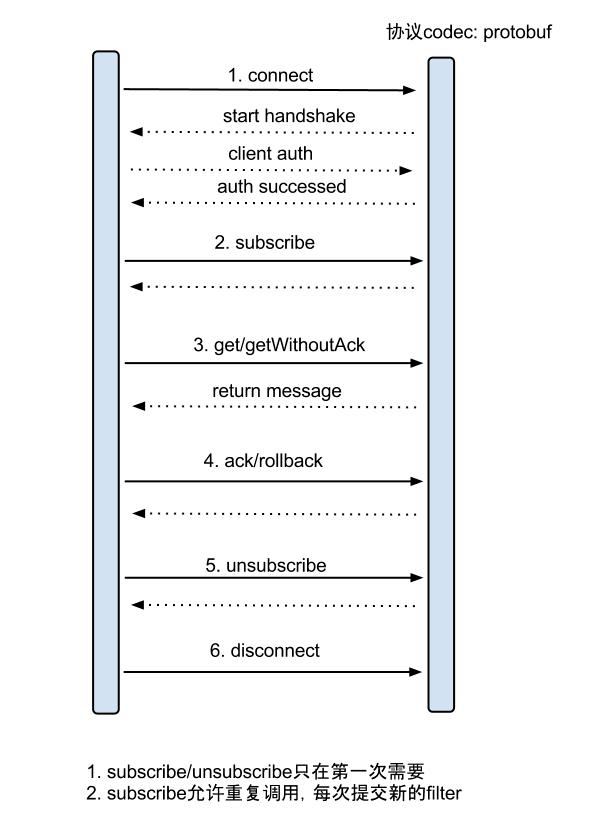
具体的协议格式,可参见:CanalProtocol.proto。数据对象格式:EntryProtocol.proto
Entry Header logfileName [binlog文件名] logfileOffset [binlog position] executeTime [binlog里记录变更发生的时间戳] schemaName [数据库实例] tableName [表名] eventType [insert/update/delete类型] entryType [事务头BEGIN/事务尾END/数据ROWDATA] storeValue [byte数据,可展开,对应的类型为RowChange] RowChange isDdl [是否是ddl变更操作,比如create table/drop table] sql [具体的ddl sql] rowDatas [具体insert/update/delete的变更数据,可为多条,1个binlog event事件可对应多条变更,比如批处理] beforeColumns [Column类型的数组] afterColumns [Column类型的数组] Column index [column序号] sqlType [jdbc type] name [column name] isKey [是否为主键] updated [是否发生过变更] isNull [值是否为null] value [具体的内容,注意为文本]
针对上述的补充说明:
1.可以提供数据库变更前和变更后的字段内容,针对binlog中没有的name、isKey等信息进行补全
2.可以提供ddl的变更语句
Canal HA机制:
Canal的HA实现机制是依赖zookeeper实现的,主要分为Canal server和Canal client的HA。
Canal server:为了减少对MySQL dump的请求,不同server上的instance要求同一时间只能有一个处于running状态,其他的处于standby状态。
Canal client:为了保证有序性,一份instance同一时间只能由一个Canal client进行get/ack/rollback操作,否则客户端接收无法保证有序。
Canal Server HA架构图:
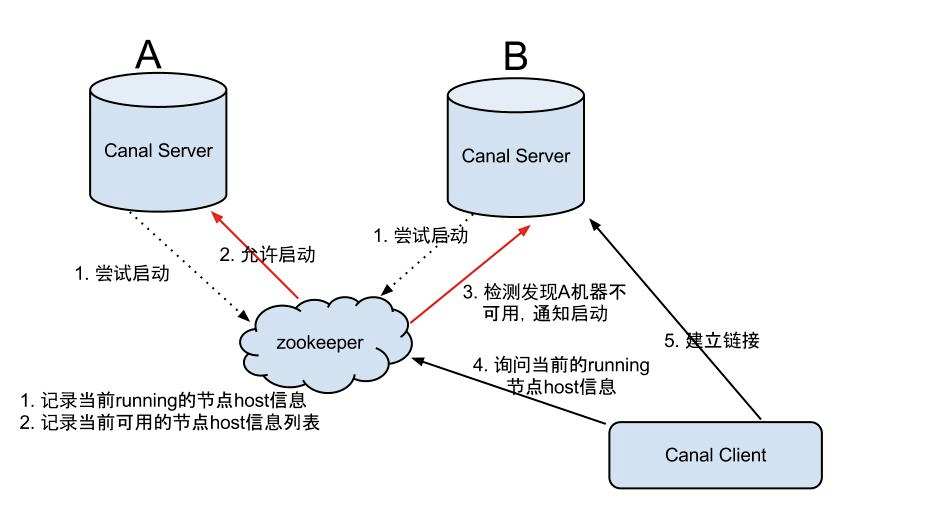
大致步骤:
- Canal server要启动某个Canal instance时都先向Zookeeper进行一次尝试启动判断 (实现:创建EPHEMERAL节点,谁创建成功就允许谁启动)
- 创建Zookeeper节点成功后,对应的Canal server就启动对应的Canal instance,没有创建成功的Canal instance就会处于standby状态
- 一旦Zookeeper发现Canal server A创建的节点消失后,立即通知其他的Canal server再次进行步骤1的操作,重新选出一个Canal server启动instance
- Canal client每次进行connect时,会首先向Zookeeper询问当前是谁启动了Canal instance,然后和其建立链接,一旦链接不可用,会重新尝试connect
Canal Client的方式和Canal server方式类似,也是利用Zookeeper的抢占EPHEMERAL节点的方式进行控制。
关注微信公众号:大数据学习与分享,获取更对技术干货

 浙公网安备 33010602011771号
浙公网安备 33010602011771号