
图解SparkStreaming与Kafka的整合,这些细节大家要注意!
前言

老刘是一名即将找工作的研二学生,写博客一方面是复习总结大数据开发的知识点,一方面是希望帮助更多自学的小伙伴。由于老刘是自学大数据开发,肯定会存在一些不足,还希望大家能够批评指正,让我们一起进步!
今天讲述的是SparkStreaming与Kafka的整合,这篇文章非常适合刚入门的小伙伴,也欢迎大家前来发表意见,老刘这次会用图片的形式讲述别人技术博客没有的一些细节,这些细节对刚入门的小伙伴是非常有用的!!!
正文
为什么有SparkStreaming与Kafka的整合?
首先我们要知道为什么会有SparkStreaming与Kafka的整合,任何事情的出现都不是无缘无故的!
我们要知道Spark作为实时计算框架,它仅仅涉及到计算,并没有涉及到数据的存储,所以我们后期需要使用spark对接外部的数据源。SparkStreaming作为Spark的一个子模块,它有4个类型的数据源:
- socket数据源(测试的时候使用)
- HDFS数据源(会用到,但是用得不多)
- 自定义数据源(不重要,没怎么见过别人会自定义数据源)
- 扩展的数据源(比如kafka数据源,它非常重要,面试中也会问到)
下面老刘图解SparkStreaming与Kafka的整合,但只讲原理,代码就不贴了,网上太多了,老刘写一些自己理解的东西!

SparkStreaming整合Kafka-0.8
SparkStreaming与Kafka的整合要看Kafka的版本,首先要讲的是SparkStreaming整合Kafka-0.8。
在SparkStreaming整合kafka-0.8中,要想保证数据不丢失,最简单的就是靠checkpoint的机制,但是checkpoint机制有一个毛病,对代码进行升级后,checkpoint机制就失效了。所以如果想实现数据不丢失,那么就需要自己管理offset。
大家对代码升级会不会感到陌生,老刘对它好好解释一下!
我们在日常开发中常常会遇到两个情况,代码一开始有问题,改一下,然后重新打包,重新提交;业务逻辑发生改变,我们也需要重新修改代码!
而我们checkpoint第一次持久化的时候会整个相关的jar给序列化成一个二进制文件,这是一个独一无二的值做目录,如果SparkStreaming想通过checkpoint恢复数据,但如果代码发生改变,哪怕一点点,就找不到之前打包的目录,就会导致数据丢失!
所以我们需要自己管理偏移量!
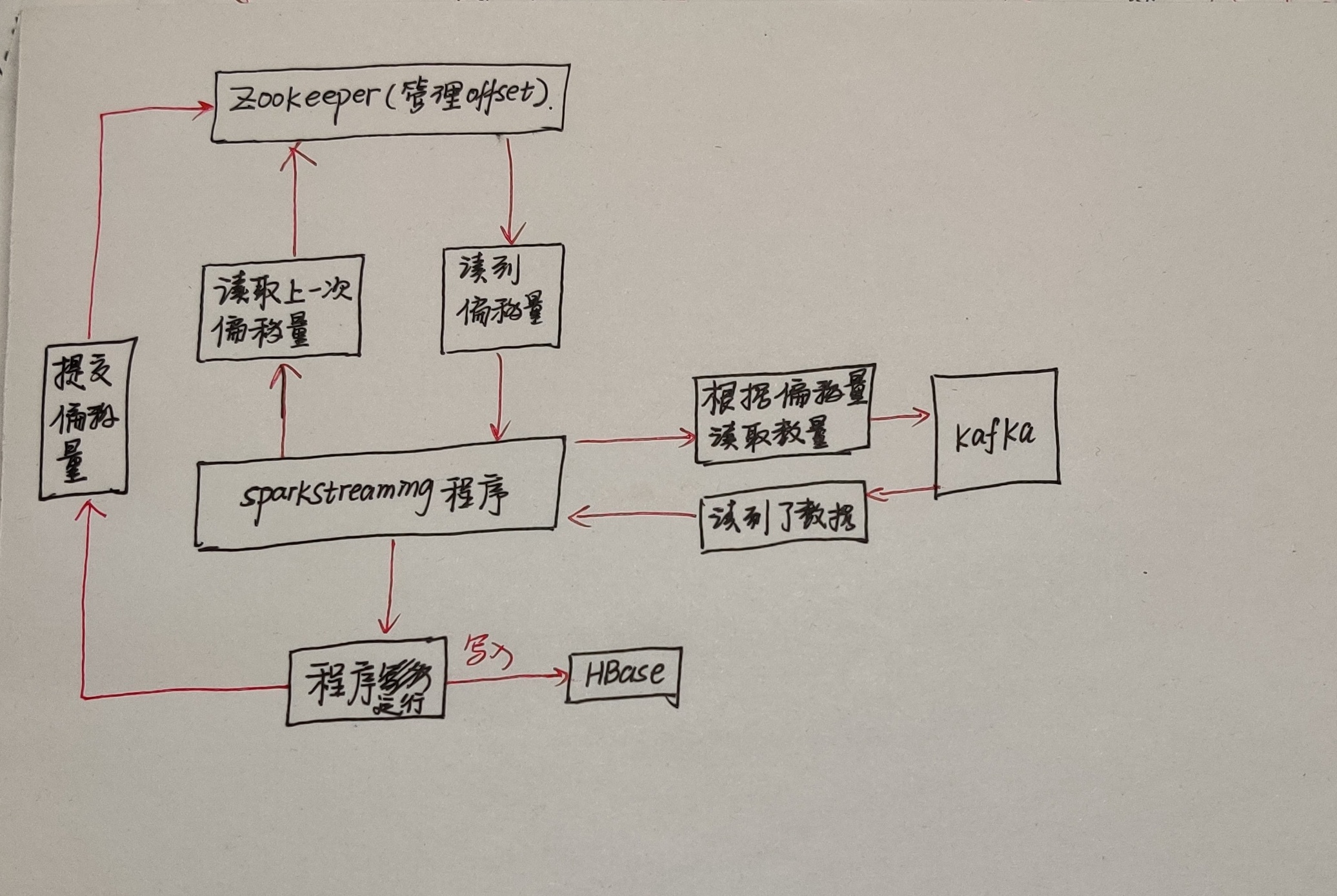
用ZooKeeper集群管理偏移量,程序启动后,就会读取上一次的偏移量,读取到数据后,SparkStreaming就会根据偏移量从kafka中读取数据,读到数据后,程序会运行。运行完后,就会提交偏移量到ZooKeeper集群,但有一个小问题,程序运行挂了,但偏移量未提交,结果已经部分到HBase,再次重新读取的时候,会有数据重复,但只影响一批次,对大数据来说,影响太小!
但是有个非常严重的问题,当有特别多消费者消费数据的时候,需要读取偏移量,但ZooKeeper作为分布式协调框架,它不适合大量的读写操作,尤其是写操作。所以高并发的请求ZooKeeper是不适合的,它只能作为轻量级的元数据存储,不能负责高并发读写作为数据存储。
根据上述内容,就引出了SparkStreaming整合Kafka-1.0。
SparkStreaming整合Kafka-1.0
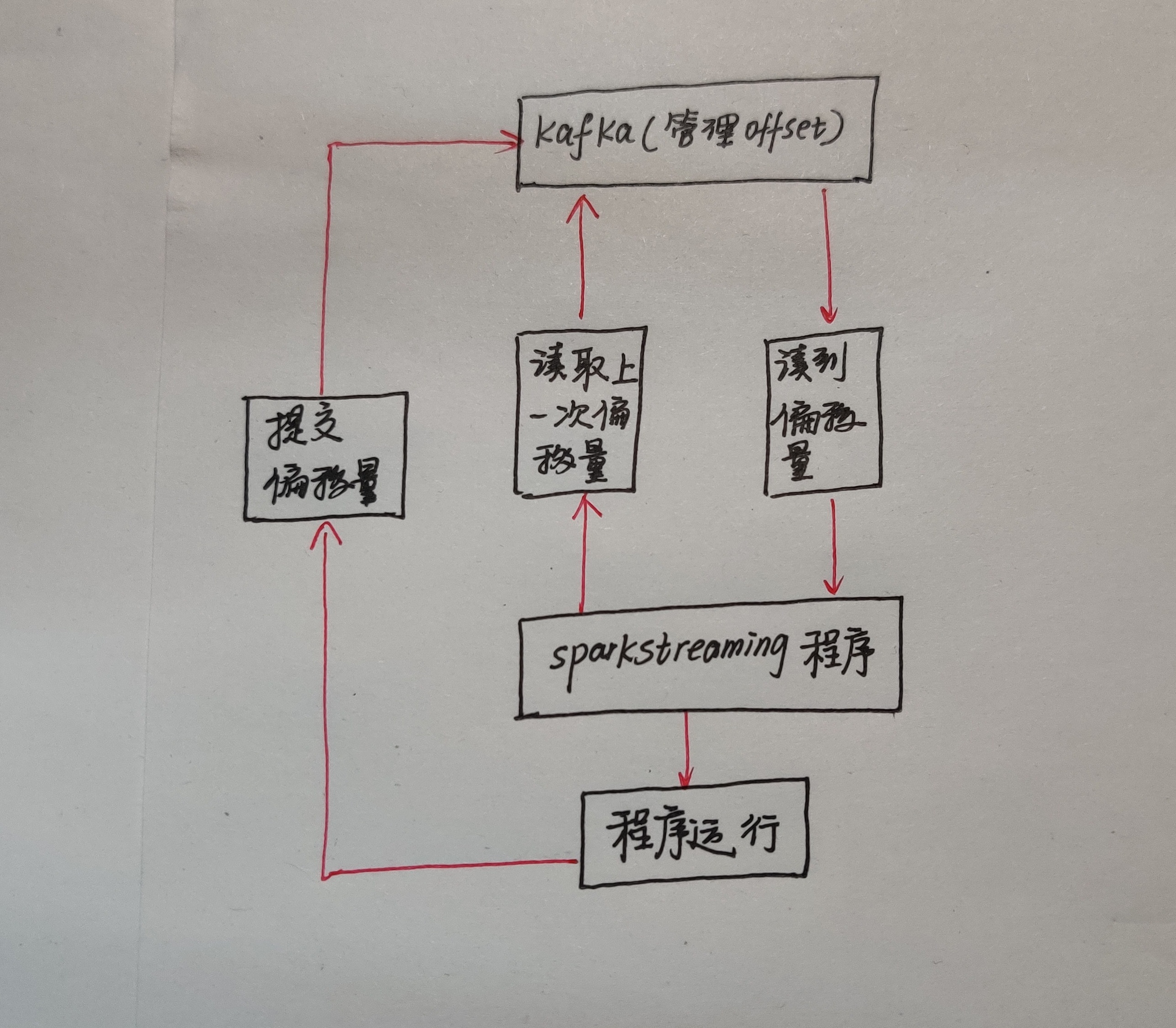
直接利用kafka保存offset偏移量,可以避免利用ZooKeeper存储offset偏移量带来的风险,这里也有一个注意的地方,kafka有一个自动提交偏移量的功能,但会导致数据丢失。
因为设置自动提交就会按照一定的频率,比如每隔2秒自动提交一次偏移量。但我截获一个数据后,还没来得及处理,刚好到达2秒就把偏移量提交了,于是就导致数据丢失,所以我们一般手动提交偏移量!
如何设计监控告警方案?
在日常开发工作中,我们需要对实时任务设计一个监控方案,因为实时任务没有监控,程序就在裸奔,任务是否有延迟等情况无法获取,这是非常可怕的情况!
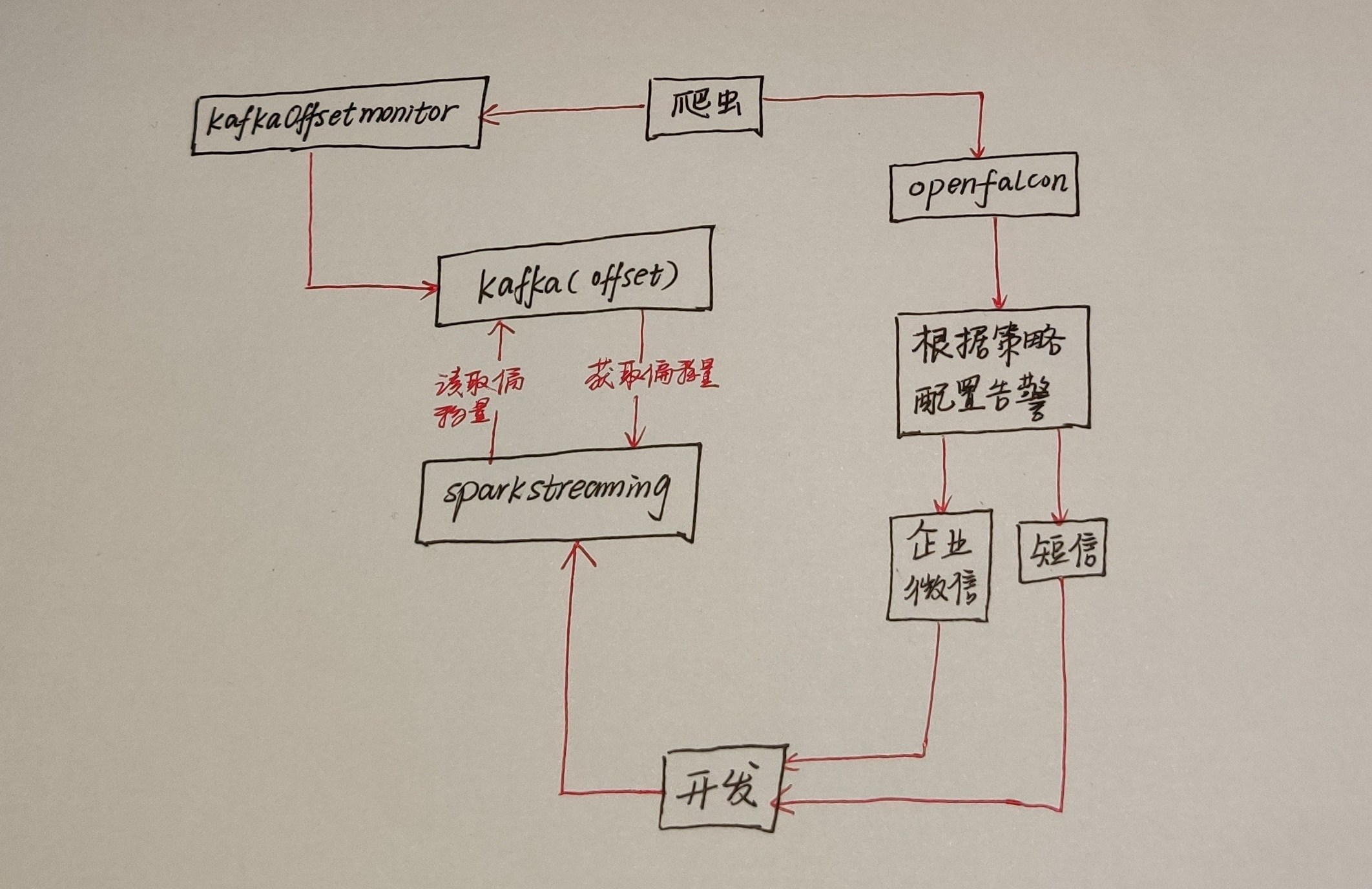
这个只是利用KafkaOffsetmonitor设计的一个方案,利用它对任务进行监控,接着利用爬虫技术获取监控的信息,再把数据导入到openfalcon里面,在openfalcon里根据策略配置告警或者自己研发告警系统,最后把信息利用企业微信或者短信发送给开发人员!
总结
好啦!本篇主要讲解了SparkStreaming和Kafka的整合过程,老刘花了很多心思讲了很多细节,对大数据感兴趣的伙伴记得给老刘点赞关注。最后,如果有疑问联系公众号:努力的老刘,进行愉快的交流!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号