
大白话详解大数据hive知识点,老刘真的很用心(2)

前言:老刘不敢说写的有多好,但敢保证尽量用大白话把自己复习的内容详细解释出来,拒绝资料上的生搬硬套,做到有自己的了解!
1. hive知识点(2)
第12点:hive分桶表
hive知识点主要偏实践,很多人会认为基本命令不用记,但是万丈高楼平地起,基本命令无论多基础,都要好好练习,多实践。
在hive中,分桶是相对分区进行更加细粒的划分。其中分区针对的是数据的存储路径,而分桶针对的是数据文件,老刘用两张相关的图对比一下,就能明白刚刚说的区别了。
第一张是表进行分区后变化:
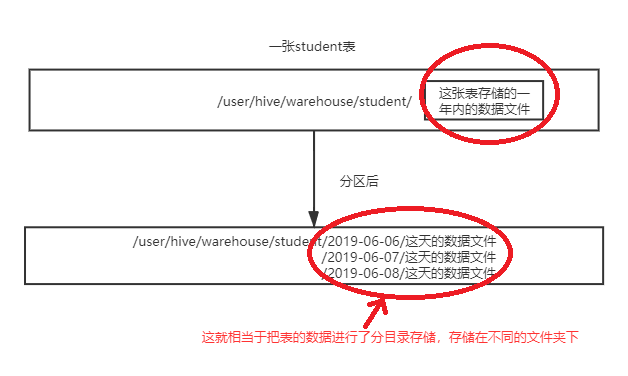 第二张是表进行分桶后的变化:
第二张是表进行分桶后的变化:

根据这两张图,大致可以理解分区和分桶的区别。
那既然看了这两张图,分桶到底是什么,也应该大致清楚了!
什么是分桶?
分桶就是将整个数据内容按照某列属性值取hash值进行区分,具有相同hash值的数据进入到同一个文件中。
举例说明一下:比如按照name属性分为3个桶,就是对name属性值的hash值对3取模,按照取模结果对数据进行分桶。
取模结果为0的数据记录存放到一个文件;
取模结果为1的数据记录存放到一个文件;
取模结果为2的数据记录存放到一个文件;取模结果为3的数据记录存放到一个文件;
至于分桶表的案例太多了,大家自己可搜一个练练手。
第13点:hive修改表结构
这一点,其实没有什么好说的,资料上提到了,老刘也说一说,记住几个命令就行。
修改表的名称
alter table stu3 rename to stu4;
表的结构信息
desc formatted stu4;
第14点:hive数据导入
这部分挺重要的,因为创建表后,要做的事就是把数据导入表中,如果连数据导入的基本命令都不会的话,那绝对是不合格的,这是非常重要的基础!
1、通过load方式加载数据(必须记下来)
通过load方式加载数据
load data local inpath '/kkb/install/hivedatas/score.csv' overwrite into table score3 partition(month='201806');
2、通过查询方式加载数据(必须记下来)
通过查询方式加载数据
create table score5 like score;
insert overwrite table score5 partition(month = '201806') select s_id,c_id,s_score from score;
第15点:hive数据导出
1、insert导出

将查询的结果导出到本地
insert overwrite local directory '/kkb/install/hivedatas/stu' select * from stu;
将查询的结果格式化导出到本地
insert overwrite local directory '/kkb/install/hivedatas/stu2' row format delimited fields terminated by ',' select * from stu;
将查询的结果导出到HDFS上(没有local)
insert overwrite directory '/kkb/hivedatas/stu' row format delimited fields terminated by ',' select * from stu;
第16点:静态分区和动态分区
Hive有两种分区,一种是静态分区,也就是普通的分区。另一种是动态分区。
静态分区:在加载分区表的时候,往某个分区表通过查询的方式加载数据,必须要指定分区字段值。
这里举一个小例子,演示下两者的区别。
1、创建分区表
use myhive;
create table order_partition(
order_number string,
order_price double,
order_time string
)
partitioned BY(month string)
row format delimited fields terminated by '\t';
2、准备数据
cd /kkb/install/hivedatas
vim order.txt
10001 100 2019-03-02
10002 200 2019-03-02
10003 300 2019-03-02
10004 400 2019-03-03
10005 500 2019-03-03
10006 600 2019-03-03
10007 700 2019-03-04
10008 800 2019-03-04
10009 900 2019-03-04
3、加载数据到分区表
load data local inpath '/kkb/install/hivedatas/order.txt' overwrite into table order_partition partition(month='2019-03');
4、查询结果数据
select * from order_partition where month='2019-03';
结果为:
10001 100.0 2019-03-02 2019-03
10002 200.0 2019-03-02 2019-03
10003 300.0 2019-03-02 2019-03
10004 400.0 2019-03-03 2019-03
10005 500.0 2019-03-03 2019-03
10006 600.0 2019-03-03 2019-03
10007 700.0 2019-03-04 2019-03
10008 800.0 2019-03-04 2019-03
10009 900.0 2019-03-04 2019-03
动态分区:按照需求实现把数据自动导入到表的不同分区中,不需要手动指定。
如果需要一次性插入多个分区的数据,可以使用动态分区,不用指定分区字段,系统自动查询。
动态分区的个数是有限制的,它一定要从已经存在的表里面来创建。
首先必须说的是,动态分区表一定是在已经创建的表里来创建
1、创建普通标
create table t_order(
order_number string,
order_price double,
order_time string
)row format delimited fields terminated by '\t';
2、创建目标分区表
create table order_dynamic_partition(
order_number string,
order_price double
)partitioned BY(order_time string)
row format delimited fields terminated by '\t';
3、准备数据
cd /kkb/install/hivedatas
vim order_partition.txt
10001 100 2019-03-02
10002 200 2019-03-02
10003 300 2019-03-02
10004 400 2019-03-03
10005 500 2019-03-03
10006 600 2019-03-03
10007 700 2019-03-04
10008 800 2019-03-04
10009 900 2019-03-04
4、动态加载数据到分区表中
要想进行动态分区,需要设置参数
开启动态分区功能
set hive.exec.dynamic.partition=true;
设置hive为非严格模式
set hive.exec.dynamic.partition.mode=nonstrict;
insert into table order_dynamic_partition partition(order_time) select order_number,order_price,order_time from t_order;
5、查看分区
show partitions order_dynamic_partition;
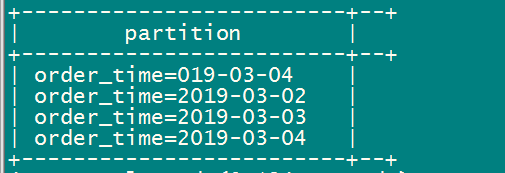
静态分区和动态分区的例子讲述的差不多了,大家好好体会下。
第17点:hive的基本查询语法
老刘之前就说过,hive的基本查询语法是非常重要的,很多人认为压根不用记,需要的时候看看笔记就行,但是在老刘看来,这是非常错误的想法。
有句话说基础不牢,地动山摇,我们最起码要掌握常用的查询语法。
1、基本语法查询:
因为limit语句和where语句用的特别多,单独拿出来,大家好好记记!
limit 语句
select * from score limit 5;
接下来是where语句,单独拿出来,是想表达出where语句很重要。我们使用where语句,将不满足条件的行过滤掉。
select * from score where s_score > 60;
2、分组语句
group by语句
group by语句通常和聚合函数一起使用,按照一个或者多个列结果进行分组,然后对每个组执行聚合操作。有个重点必须注意,select的字段,必须在group by字段后面挑选,除了聚合函数max,min,avg。
举两个小例子:
(1)计算每个学生的平均分数
select s_id,avg(s_score) from score group by s_id;
(2)计算每个学生最高的分数
select s_id,max(s_score) from score group by s_id;
having语句
先说说having语句和where不同点
① where是针对于表中的列,查询数据;having针对于查询结果中的列,刷选数据。
② where后面不能写分组函数,而having后面可以使用分组函数。
③ having只用于group by分组统计语句。
举两个小例子:
求每个学生的平均分数
select s_id,avg(s_score) from score group by s_id;
求每个学生平均分数大于60的人
select s_id,avg(s_score) as avgScore from score group by s_id having avgScore > 60;
3、join语句

等值join
hive中支持通常的SQL JOIN语句,但是只支持等值连接,不支持非等值连接。
使用join的时候,可以给表起别名,也可以不用起。起别名的好处就是可以简化查询,方便。
根据学生和成绩表,查询学生姓名对应的成绩
select * from stu left join score on stu.id = score.s_id;
合并老师与课程表
select * from teacher t join course c on t.t_id = c.t_id;
内连接inner join
当两个表进行内连接的时候,只有两个表中都存在与连接条件相匹配的数据的时候,数据才会保留下来,并且join默认就是inner join。
select * from teacher t inner join course c on t.t_id = c.t_id;
左外连接left outer join
进行左外连接的时候,join左边表中符合where子句的所有记录将会返回。
查询老师对应的课程
select * from teacher t left outer join course c on t.t_id = c.t_id;
右外连接right outer join
进行右外连接的时候,join右边表中符合where子句的所有记录将会返回。
查询老师对应的课程
select * from teacher t right outer join course c on t.t_id = c.t_id;
4、排序
order by全局排序
使用order by进行排序时候,asc表示升序,这是默认的;desc表示降序。
查询学生的成绩,并按照分数降序排列
select * from score s order by s_score desc ;
2. hive总结
hive知识点(2)就分享的差不多了,这部分偏于实践,需要好好练习。在老刘看来分桶表以及静态分区和动态分区的概念需要好好记住,剩下的就是hive的基本查询操作,由于命令实在太多了,老刘只分享出了一些常用的命令,limit语句,where语句,分组语句,join语句等要熟记于心。
最后,如果觉得有哪里写的不好或者有错误的地方,可以联系公众号:努力的老刘,进行交流。希望能够对大数据开发感兴趣的同学有帮助,希望能够得到同学们的指导。
如果觉得写的不错,给老刘点个赞!

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步