015年4月1日(星期二)
晴 南风
今天是愚人节,我们给同事过愚人节,爬虫也让我们技术部过了愚人节。通过对抓取数据的分析,发现有20%的数据都是重复数据。开会讨论,原来有两个问题,一个爬虫引擎有重大bug;另外一个问题,竟然对网页没有做去重处理。啊!My GOD!
通过和群里进行技术交流,大概明白了解决问题的思路。爬虫爬下的网页在通过ETL工具抽取到搜索引擎时候需要对内容进行去重的操作。评价网页内容重复的问题,大体上分为4种:
1、完全重复 文档内容和布局格式上毫无差别;
2、内容重复 文档内容相同,布局格式不同;
3、布局重复 文档重要的内容相同,布局相同;
4、部分重复 文档重要内容相同,布局格式不同。
我们出现的问题的原因,是因为爬虫组,只是对内容进行了简单的md5加密,作为索引。
不专业害死人呀!
我翻了翻网上的资料,网页去重流程大体如下图:
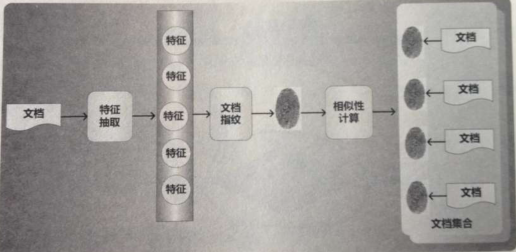
(上附图是我从网站找的)
去重的算法还不太复杂。大体上有Shingle算法、SuperShinge算法、I-Match算法和SimHash算法。在后面的几个章节,我会一一娓娓道来。
版权声明:本文为博主原创文章,未经博主允许不得转载。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号