大数据各组件重要技术点总结
介绍
针对大数据组件特点归纳如下:
- 存储:HDFS,hudi,Hbase, Kafka
- 计算引擎:Spark,Flink
- OLAP: Doris
- 调度: Yarn
下面主要从架构、组件原理、业务场景等角度针对相关组件的技术要点进行总结. 主要以问题驱动.
组件技术要点
1.hudi的cow,mor区别和应用场景?
Cow:
写时复制技术就是不同进程在访问同一资源的时候,只有更新操作,才会去复制一份新的数据并更新替换,否则都是访问同一个资源
读多写少的数据,适合cow,离线批量更新场景
Mor:
新插入的数据存储在deltalog 中,定期再将delta log合并进行parquet数据文件。读取数据时,会将deltalog跟老的数据文件做merge,得到完整的数据返回
由于写入数据先写deltalog,且delta log较小,所以写入成本较低,适用实时高频更新场景
2. hdfs架构及各角色的作用,如何实现namenode 高可用?
Namenode: 管理节点,存储元数据、文件与数据块对应关系的节点,数据以fsimage和editlog存储在namenode本地磁盘
Datanode:文件系统工作节点,根据需要存储和检索数据块,定期向他们发送存储的块列表
双机热备份,standby和active, 备用namenode为活动的namenode设置周期性的检查点,判断活动namenode是否失效
3. hbase架构,如何解决写热点问题?
- RegionServer:负责数据的读写服务,用户通过与Region server交互来实现对数据的访问
- HBaseHMaster:负责Region的分配及数据库的创建和删除等操作
- ZooKeeper:负责维护集群的状态(某台服务器是否在线,服务器之间数据的同步操作及master的选举等)
热点:
创建表的指定多个region,默认情况下一个表一个region
对rowkey进行散列,把多个请求写分到不同的region上,需要对key进行md5,进行散列,这样就可以把写请求分到不同的region上面去
4.kafka rebalance机制,架构及写入存储机制?
rebalance机制:
当kafka遇到如下四种情况的时候,kafka会触发Rebalance机制:
消费组成员发生了变更,比如有新的消费者加入了消费组组或者有消费者宕机
消费者无法在指定的时间之内完成消息的消费
消费组订阅的Topic发生了变化
订阅的Topic的partition发生了变化
kafka中的重要概念:
Producer: 消息生产者,向 Kafka Broker 发消息的客户端。
Consumer: 消息消费者,从 Kafka Broker 取消息的客户端。
Consumer Group:消费者组(CG),消费者组内每个消费者负责消费不同分区的数据,提高消费能力。一个分区只能由组内一个消费者消费,消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
Broker: 一台 Kafka 机器就是一个 broker。一个集群由多个 broker 组成。一个 broker可以容纳多个 topic。
Topic: 可以理解为一个队列,topic 将消息分类,生产者和消费者面向的是同一个 topic。
Partition: 为了实现扩展性,提高并发能力,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个 有序的队列。
Replica: 副本,为实现备份的功能,保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且Kafka 仍然能够继续工作,Kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower。
Leader: 每个分区多个副本的“主”副本,生产者发送数据的对象,以及消费者消费数据的对象,都是 leader。
Follower: 每个分区多个副本的“从”副本,实时从 leader 中同步数据,保持和 leader数据的同步。leader 发生故障时,某个 follower 还会成为新的 leader。
offset:消费者消费的位置信息,监控数据消费到什么位置,当消费者挂掉再重新恢复的时候,可以从消费位置继续消费。
Zookeeper: Kafka 集群能够正常工作,需要依赖于 zookeeper,zookeeper 帮助 Kafka存储和管理集群信息。
写入存储机制:
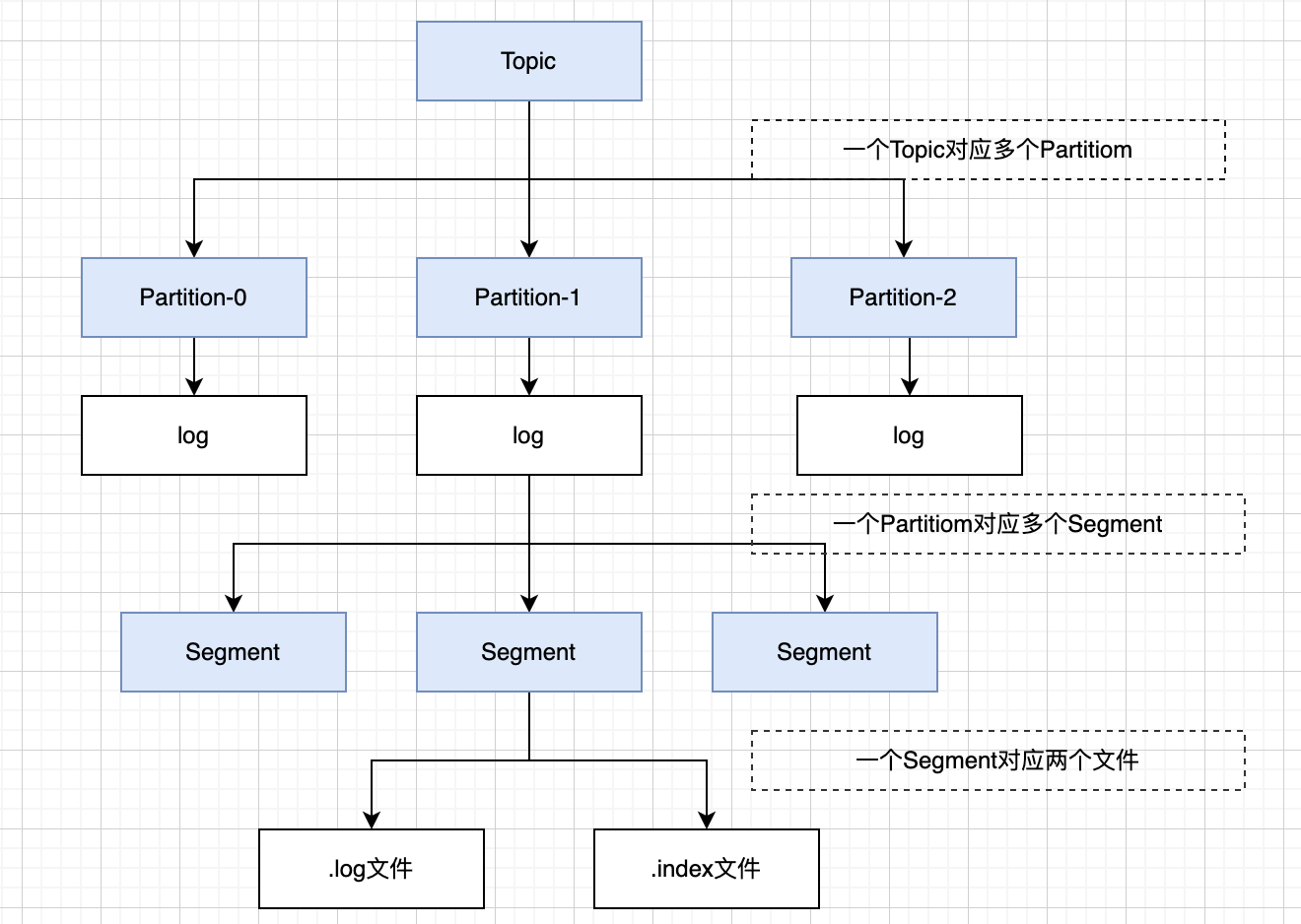
由于生产者生产的消息会不断追加到 log 文件末尾,为防止 log 文件过大导致数据定位效率低下,Kafka 采取了分片和索引机制,将每个 partition 分为多个 segment,每个 segment 对应两个文件:“.index” 索引文件和 “.log” 数据文件。这些文件位于同一文件下,该文件夹的命名规则为:topic 名-分区号。例如,first 这个 topic 有三分分区,则其对应的文件夹为 first-0,first-1,first-2。
ls/root/data/kafka/first-0
00000000000000009014.index
00000000000000009014.log
00000000000000009014.timeindex
00000000000000009014.snapshot
leader-epoch-checkpoint
".index”文件存储大量的索引信息,“.log” 文件存储大量的数据,索引文件中的元数据指向对应数据文件中 message 的物理偏移量。
5.spark宽依赖,窄依赖,数据倾斜问题解决方案?
宽依赖:是指1个父RDD分区对应多个子RDD的分区
窄依赖:是指一个或多个父RDD分区对应一个子RDD分区
宽依赖会产生shuffle,会跨网络拉取数据; 窄依赖在一个节点内就可以完成转换。
数据倾斜解决方案:
- 针对hive数据分布不均匀,Hive ETL 预处理数据
- 过滤少数导致数据倾斜的key
- 提高shuffle操作的并行度
- 双重聚合,局部聚合先给每个key都打上一个随机数,再全局聚合
- 将reduce join转为map join, BroadCast+filter(或者map)
- 采样倾斜key分拆join操作, 将两次join的结果union合并起来,就是join的结果
6.flink状态存储,架构,如何实现精确一次语义?
Flink提供了三种开箱即用的状态存储方式:
- MemoryStateBackend 内存存储
- FsStateBackend 文件系统存储
- RocksDBStateBackend RocksDB存储
如果没有特殊配置,系统默认使用内存存储方式
架构:
JobManager:
JobManager具有许多与协调 Flink 应用程序的分布式执行有关的职责:它决定何时调度下一个 task(或一组 task)、对完成的 task 或执行失败做出反应、协调checkpoint、并且协调从失败中恢复等等
TaskManagers:
TaskManager(也称为worker)执行作业流的 task,并且缓存和交换数据流
精确一次语义保证:
source端: Flink Kafka Source 负责保存 Kafka 消费 offset, Chckpoint成功时 Flink 负责提交这些写入
sink端: 从 Source端开始,每个内部的 transform 任务遇到 checkpoint barrier(检查点分界线)时,都会把状态存到 Checkpoint 里,
数据处理完毕到 Sink 端时,Sink 任务首先把数据写入外部 Kafka,这些数据都属于预提交的事务(还不能被消费)
当所有算子任务的快照完成, 此时 Pre-commit 预提交阶段才算完成。才正式到两阶段提交协议的第二个阶段:commit 阶段。该阶段中JobManager 会为应用中每个 Operator 发起 Checkpoint 已完成的回调逻辑, 当 Sink任务收到确认通知,就会正式提交之前的事务,Kafka 中未确认的数据就改为“已确认”,数据就真正可以被消费了
7.doris架构设计,如何实现查询计算较快?
架构:
FE: 主要负责查询的编译,分发和元数据管理(基于内存,类似HDFS NN)
BE: 主要负责查询的执行和存储系统
查询计算快原因:
1. MPP架构
2. 列式存储
8.yarn调度算法有哪些,以及调度过程?
调度算法:
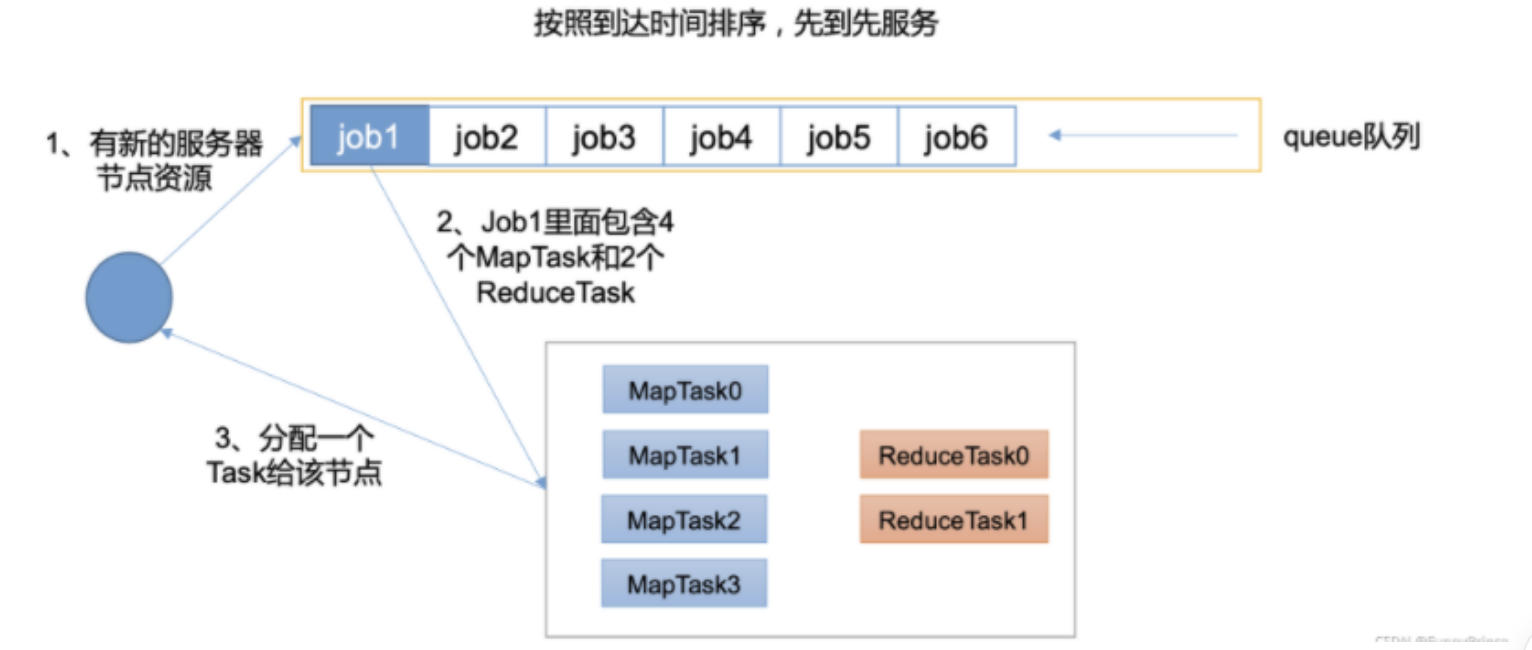
- 先进先出调度器(FIFO) 单队列,根据提交作业的先后顺序,先到先得。
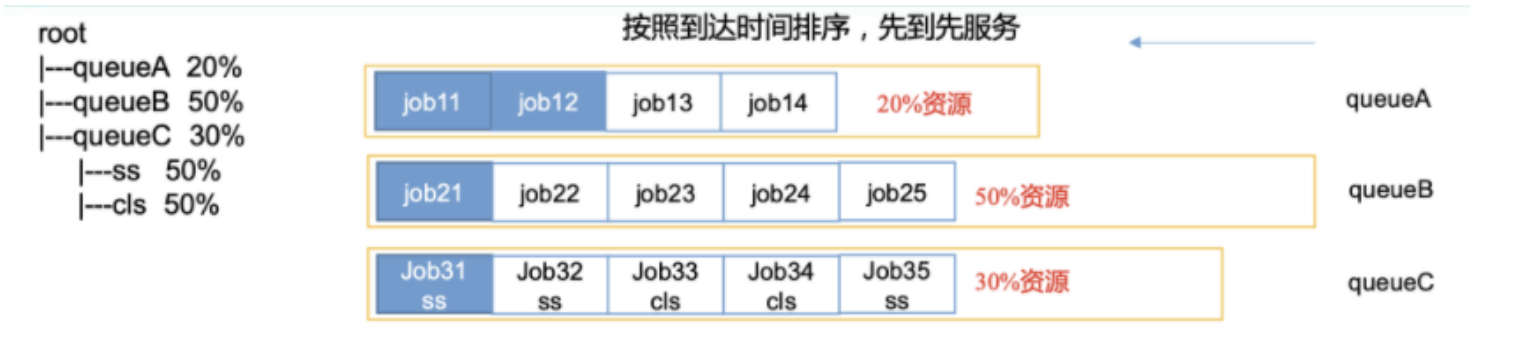
- 容量调度器
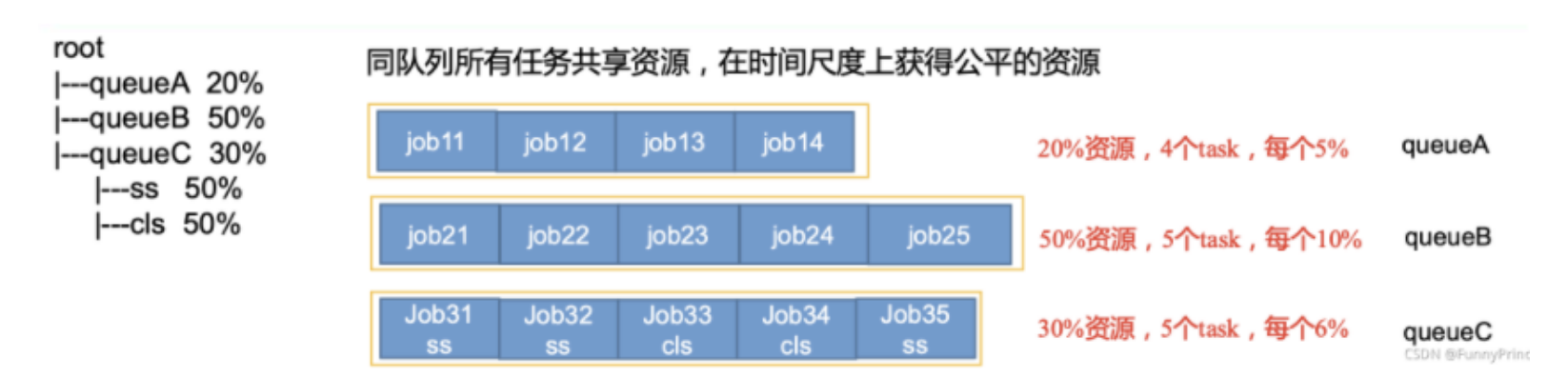
- 公平调度器
容量调度器:优先选择资源利用率低的队列;
公平调度器:优先选择对资源缺额比例大的。
9.flink作业提交流程?
Yarn-session: 应用模式与单作业模式的提交流程非常相似,只是初始提交给Yarn资源管理器的不再是具体的作业,而是整个应用。一个应用中可能包含了多个作业,这些作业都在Flink集群中启动各自对应的JobMaster。
Per-job: 与会话模式不同的是JobManager的启动方式,以及省去了分发器。作业提交给JobMaster之后的步骤是一样的
参考
- 列式存储: https://juejin.cn/post/7080504990900420644
- Yarn调度器和调度算法(FIFO、容量调度器 与 公平调度器):https://blog.csdn.net/FunnyPrince_/article/details/120244552
- Flink作业提交流程(Yarn集群模式: https://blog.csdn.net/FlatTiger/article/details/124195400
微信公众号

出处:https://www.cnblogs.com/bigdata1024/p/16167371.html
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
posted on 2022-04-19 21:41 chaplinthink 阅读(861) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号