[Elasticsearch] ES更新问题踩坑记录
问题描述
我们有个系统设计的时候针对Hive创建表、删除表, 需要更新ES中的一个状态,标记是否删除,在几乎同时执行两条下面的语句的时候,发现在ES 中出现表即使被创建了还是无法被查询到的情况,针对该问题记录下排查分析过程.
drop table if exists tmp.test_create_table;
create table if not exists tmp.test_create_table(
id int,
name string
) stored as parquet;
问题排查
查看ES数据
发现ES创建表的状态没有正常更新 yn 还是0
查看日志
查看日志, 截取部分关键信息:
ReceiverController] [4eb1c8fd7b6987ae] - 接收的hive元数据为:{"data": ...
"eventType":"DROP_TABLE" ...
ReceiverController] [d1aa226b8739d352] - 接收的hive元数据为:{"data": ...
"eventType":"CREATE_TABLE" ...
[Kafka-Consume-Thread-bigdata_aa-0] [ec812addb0bf424d] - update table data to es: ... "yn":0}
[Kafka-Consume-Thread-bigdata_aa-0] [3085b7329053aaac] - update table data to es: ... "yn":1}
日志里有几个关键线索:
-
建表与删除表的Hive元数据信息正常上报上来了
-
建表删表事件都执行了更新数据到ES的操作, [Kafka-Consume-Thread-bigdata_aa-0] 可以看出是单线程更新ES, 所以不会存在多线程并发的问题
-
基本可以定位是在es更新这块出问题了
看对应代码
final TableDocBean docBean = baseSearchService.getById(id);
setValueForBean(afterColumns, docBean);
log.info("update table data to es: {}", JSON.toJSONString(docBean));
baseSearchService.update(docBean);
代码先通过表id 获取对应ES文档,然后赋值 执行更新数据操作
这块没有看出什么问题,考虑到两个事件同时执行时间间隔较短,采用了在代码里Thread.sleep(1000) 睡眠下试试,发现两条SQL语句同时执行的基本每次都成功,可以在ES搜索到.
这种操作不免让人觉得ES里执行更新操作,肯定是有延迟的,具体为什么延迟,就需要看下ES的更新原理
更新原理
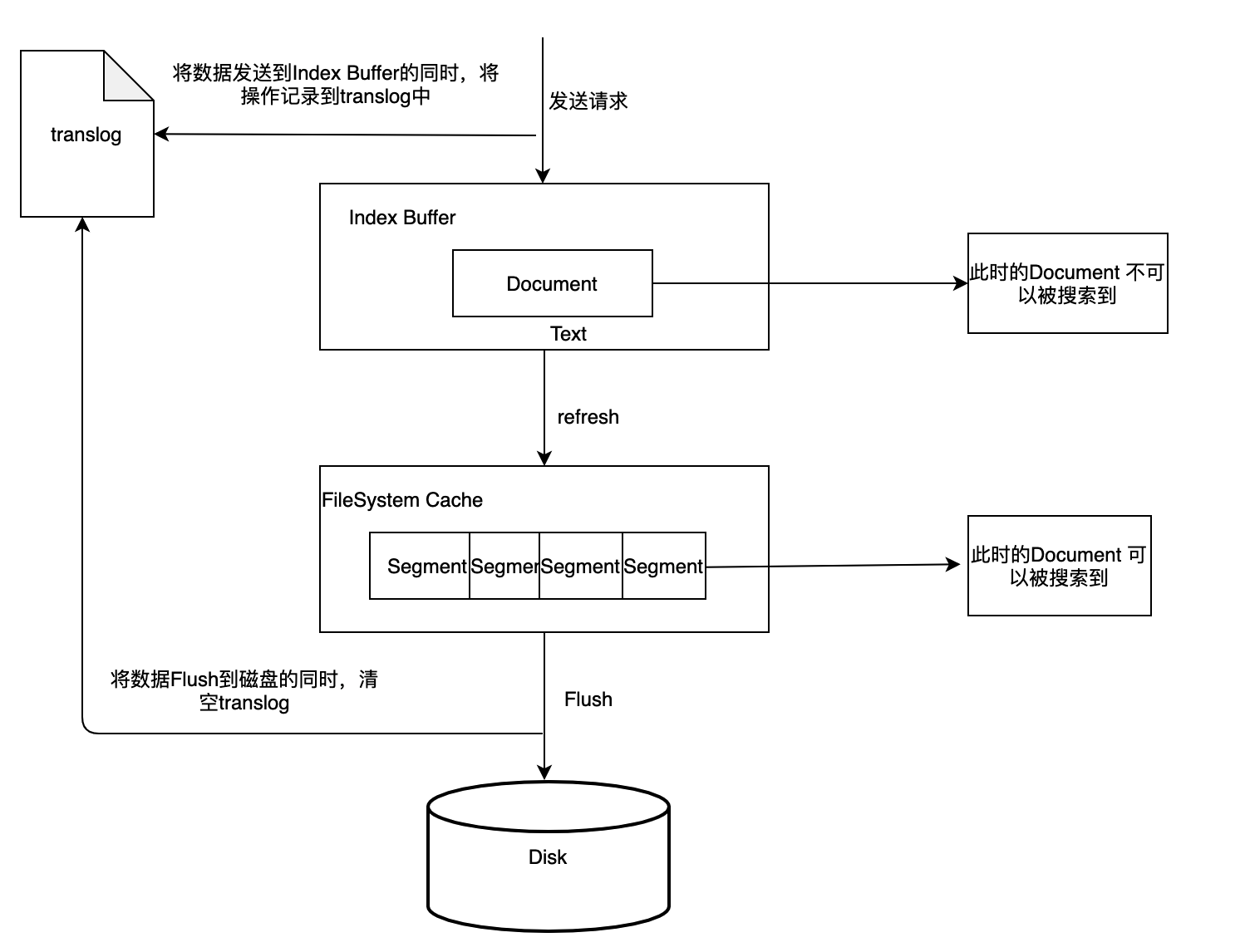
ES更新请求先将index-buffer中文档(document)解析完成的segment写到filesystem cache之中,这样避免了比较损耗性能io操作,又可以使document可以被搜索 , 从index-buffer中取数据到filesystem cache中的过程叫做refresh。es默认的refresh间隔时间是1s
ES数据在更新的时候并不是在原来的数据上做修改的, 而是找到该数据的索引Id,把原来的数据删掉,再重新插入一条,但索引id是相同的
当删除、更新两个操作间隔很短时间执行,上一个数据还没有refresh 到 FileSystem Cache区域,就无法查询,final TableDocBean docBean = baseSearchService.getById(id);
获取不到数据,所以会导致数据更新失败
解决方案
修改ES refresh到cache区域间隔时间:
curl -XPUT http://ip:9200/meta_es_data/_settings?pretty -d '
{
"refresh_interval" : "500ms"
}'
在每次更新操作后,休眠1s:
baseSearchService.update(docBean);
Thread.sleep(1000);
ES 请求接口有请求后强制刷新方法,但是一般用于测试,不建议线上用
setRefreshPolicy(WriteRequest.RefreshPolicy.IMMEDIATE);
总结
- 不要忽视一个看起来貌似是一个小的问题,其背后有一定的设计、原理在里面
- 代码关键处加一些有意义且清晰的日志是非常必要的, 可以提高解决问题的效率
- 排查问题就像破案,要有耐心找到一个个关键线索,最终破案. 现实工作中解决问题的能力非常重要
微信公众号

出处:https://www.cnblogs.com/bigdata1024/p/15254164.html
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
posted on 2021-09-11 11:29 chaplinthink 阅读(2285) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号