
Antlr4 语法解析器(下)
Antlr4 的两种AST遍历方式:Visitor方式 和 Listener方式。
Antlr4规则文法:
- 注释:和Java的注释完全一致,也可参考C的注释,只是增加了JavaDoc类型的注释;
- 标志符:参考Java或者C的标志符命名规范,针对Lexer 部分的 Token 名的定义,采用全大写字母的形式,对于parser rule命名,推荐首字母小写的驼峰命名;
- 不区分字符和字符串,都是用单引号引起来的,同时,虽然Antlr g4支持 Unicode编码(即支持中文编码),但是建议大家尽量还有英文;
- Action,行为,主要有@header 和@members,用来定义一些需要生成到目标代码中的行为,例如,可以通过@header设置生成的代码的package信息,@members可以定义额外的一些变量到Antlr4语法文件中;
- Antlr4语法中,支持的关键字有:import, fragment, lexer, parser, grammar, returns, locals, throws, catch, finally, mode, options, tokens
基于IDEA调试Antlr4语法规则(文法可视化)
基于IDEA调试Antlr4语法一般步骤:
1) 创建一个调试工程,并创建一个g4文件
这里,我自己测试用Java开发,所以创建的是一个Maven工程,g4文件放在了src/main/resources 目录下,取名 Test.g4
2)写一个简单的语法结构
这里我们参考写一个加减乘除操作的表达式,然后在赋值操作对应的Rule上右键,可选择测试:
grammar Test;
@header {
package com.chaplinthink.antlr;
}
stmt : expr;
expr : expr NUL expr # Mul
| expr ADD expr # Add
| expr DIV expr # Div
| expr MIN expr # Min
| INT # Int
;
NUL : '*';
ADD : '+';
DIV : '/';
MIN : '-';
INT : Digit+;
Digit : [0-9];
WS : [ \t\u000C\r\n]+ -> skip;
SHEBANG : '#' '!' ~('\n'|'\r')* -> channel(HIDDEN);
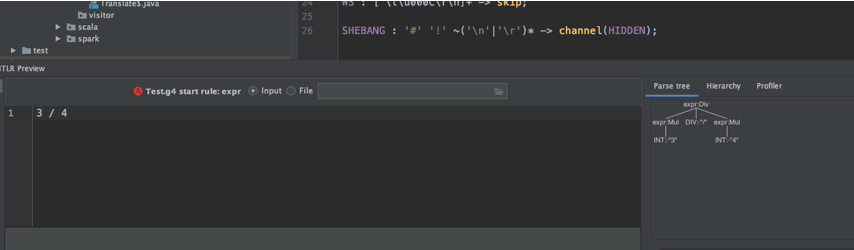
看我们 3/ 4 是可以识别出来的 语法中 channel(HIDDEN) (代表隐藏通道) 中的 Token,不会被语法解析阶段处理,但是可以通过Token遍历获取到。
Antlr4生成并遍历AST
1. 通过命令行如上篇文章
java -jar antlr-4.7.2--complete.jar -Dlanguage=Python3 -visitor Test.g4
这样就可以生成Python3 target的源码,如果不希望生成Listener,可以添加参数 -no-listener
2. Maven Antlr4插件自动生成(针对Java工程,也可以用于Gradle)
此处使用第一种方式
访问者模式遍历Antlr4语法树
java -jar /usr/local/lib/antlr-4.7.2-complete.jar -visitor -no-listener Test.g4
生成源码文件:

通过代码展示访问者模式在Antlr4中使用:
public class App {
public static void main(String[] args) {
CharStream input = CharStreams.fromString("12*2+12");
TestLexer lexer = new TestLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
TestParser parser = new TestParser(tokens);
TestParser.ExprContext tree = parser.expr();
TestVisitor tv = new TestVisitor();
tv.visit(tree);
}
static class TestVisitor extends TestBaseVisitor<Void> {
@Override
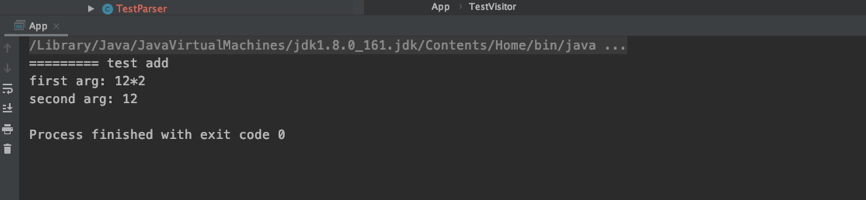
public Void visitAdd(TestParser.AddContext ctx) {
System.out.println("========= test add");
System.out.println("first arg: " + ctx.expr(0).getText());
System.out.println("second arg: " + ctx.expr(1).getText());
return super.visitAdd(ctx);
}
}
}
一般来说,面向程序静态分析时,都是使用访问者模式的,很少使用监听器模式(无法主动控制遍历AST的顺序,不方便在不同节点遍历之间传递数据)
Antlr4词法解析和语法解析
如前面的语法定义,分为Lexer和Parser,实际上表示了两个不同的阶段:
- 词法分析阶段:对应于Lexer定义的词法规则,解析结果为一个一个的Token;
- 解析阶段:根据词法,构造出来一棵解析树或者语法树。
如下图所示:

Spark & Antlr4
Spark SQL /DataFrame 执行过程是这样子的:
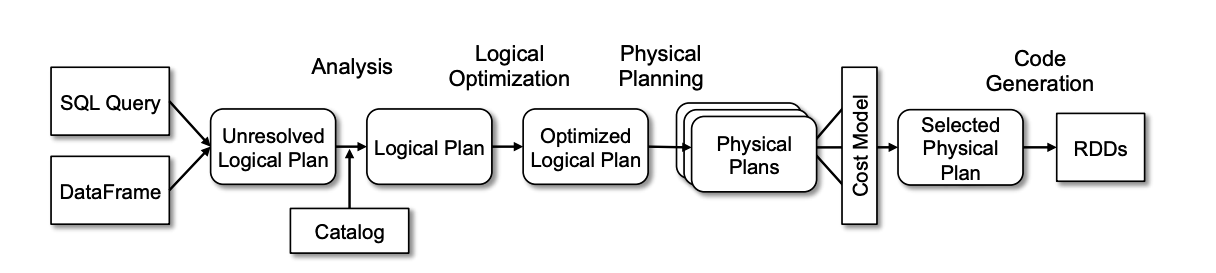
我们看下在 Spark SQL 中是如何使用Antlr4的.
当你调用spark.sql的时候, 会调用下面的方法:
def sql(sqlText: String): DataFrame = {
Dataset.ofRows(self, sessionState.sqlParser.parsePlan(sqlText))
}
parse sql阶段主要是parsePlan(sqlText)这一部分。而这里又会辗转去org.apache.spark.sql.catalyst.parser.AbstractSqlParser调用parse方法:
protected def parse[T](command: String)(toResult: SqlBaseParser => T): T = {
logDebug(s"Parsing command: $command")
val lexer = new SqlBaseLexer(new UpperCaseCharStream(CharStreams.fromString(command)))
lexer.removeErrorListeners()
lexer.addErrorListener(ParseErrorListener)
val tokenStream = new CommonTokenStream(lexer)
val parser = new SqlBaseParser(tokenStream)
parser.addParseListener(PostProcessor)
parser.removeErrorListeners()
parser.addErrorListener(ParseErrorListener)
try {
try {
// first, try parsing with potentially faster SLL mode
parser.getInterpreter.setPredictionMode(PredictionMode.SLL)
toResult(parser)
}
catch {
case e: ParseCancellationException =>
// if we fail, parse with LL mode
tokenStream.seek(0) // rewind input stream
parser.reset()
// Try Again.
parser.getInterpreter.setPredictionMode(PredictionMode.LL)
toResult(parser)
}
}
catch {
case e: ParseException if e.command.isDefined =>
throw e
case e: ParseException =>
throw e.withCommand(command)
case e: AnalysisException =>
val position = Origin(e.line, e.startPosition)
throw new ParseException(Option(command), e.message, position, position)
}
}
这里SqlBaseLexer 、SqlBaseParser都是Antlr4的东西,包括最后的toResult(parser)也是调用访问者模式的类去遍历语法树来生成Logical Plan
spark提供了一个.g4文件,编译的时候会使用Antlr根据这个.g4生成对应的词法分析类和语法分析类,同时还使用了访问者模式,用以构建Logical Plan(语法树)。
访问者模式简单说就是会去遍历生成的语法树(针对语法树中每个节点生成一个visit方法),以及返回相应的值。我们接下来看看一条简单的select语句生成的树是什么样子:
这个sqlBase.g4文件我们也可以直接复制出来,用antlr相关工具就可以生成一个生成一个解析SQL的图
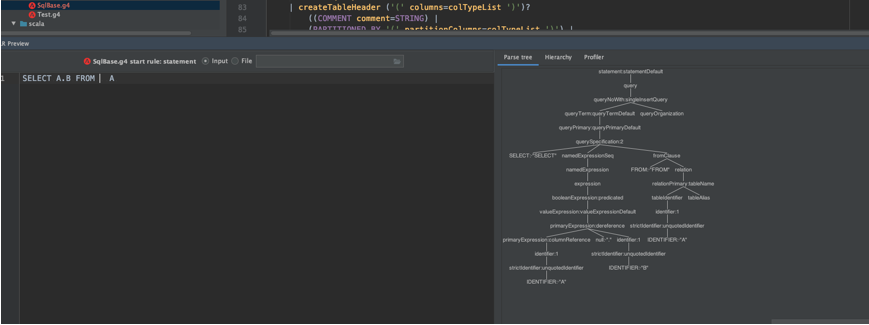
将SELECT A.B FROM A,转换成一棵语法树。我们可以看到这颗语法树非常复杂,这是因为SQL解析中,要适配这种SELECT语句之外,还有很多其他类型的语句,比如INSERT,ALERT等等。Spark SQL这个模块的最终目标,就是将这样的一棵语法树转换成一个可执行的Dataframe(RDD)
Spark使用Antlr4的访问者模式,生成Logical Plan. 我们继承SqlBaseBaseVisitor,里面提供了默认的访问各个节点的触发方法。我们可以通过继承这个类,重写对应节点的visit方法,实现自己的访问逻辑,Spark SQL中这个继承的类就是org.apache.spark.sql.catalyst.parser.AstBuilder
通过观察这棵树,我们可以发现针对我们的SELECT语句,比较重要的一个节点,是querySpecification节点,实际上,在AstBuilder类中,visitQuerySpecification也是比较重要的一个方法(访问对应节点时触发),正是在这个方法中生成主要的Logical Plan的。
以下是querySpecification在Spark SQL 中实现的 代码:
/**
* Create a logical plan using a query specification.
*/
override def visitQuerySpecification(
ctx: QuerySpecificationContext): LogicalPlan = withOrigin(ctx) {
val from = OneRowRelation().optional(ctx.fromClause) {
visitFromClause(ctx.fromClause)
}
withQuerySpecification(ctx, from)
}
先判断是否有FROM子语句,有的话会去生成对应的Logical Plan,再调用withQuerySpecification()方法,
withQuerySpecification是逻辑计划核心方法, 根据不同的子语句生成不同的Logical Plan.
参考:
[1] Spark SQL: Relational Data Processing in Spark: https://amplab.cs.berkeley.edu/wp-content/uploads/2015/03/SparkSQLSigmod2015.pdf
[2] Antlr4简明使用教程: https://bbs.huaweicloud.com/blogs/226877
微信公众号

出处:https://www.cnblogs.com/bigdata1024/p/15008050.html
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
posted on 2021-07-13 19:25 chaplinthink 阅读(2730) 评论(3) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号